Hadoop On Yarn Mapreduce运行原理与常用数据压缩格式
作者:杨思义, 2015年6月毕业于山东大学齐鲁软件学院,工程硕士学位。2014年6月至2016年4月工作于北京亚信智慧数据科技有限公司 BDX大数据事业部,从2014年9月开始从事项目spark相关应用开发。
个人博客地址:http://www.cnblogs.com/yangsy0915
市面上的hadoop权威指南一类的都是老版本的书籍了,索性学习并翻译了并整理了下最新版的Hadoop:The Definitive Guide, 4th Edition与大家共同学习。
我们通过提交jar包,进行MapReduce处理,那么整个运行过程分为五个环节:
1、向client端提交MapReduce job.
2、随后yarn的ResourceManager进行资源的分配.
3、由NodeManager进行加载与监控containers.
4、通过applicationMaster与ResourceManager进行资源的申请及状态的交互,由NodeManagers进行MapReduce运行时job的管理.
5、通过hdfs进行job配置文件、jar包的各节点分发。
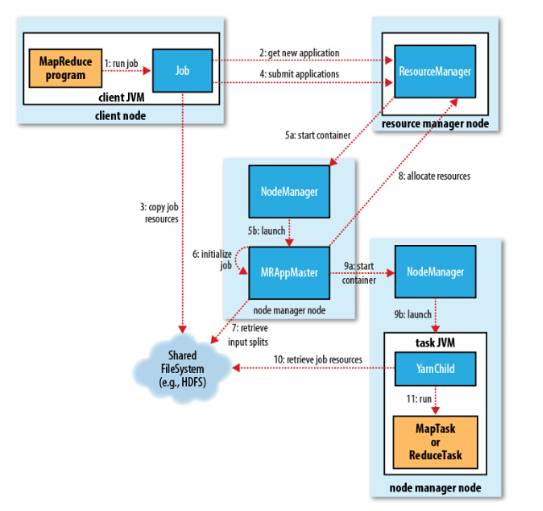
Job 提交过程
job的提交通过 调用submit()方法 创建一个 JobSubmitter 实例,并 调用submitJobInternal() 方法。整个job的运行过程如下:
1、向ResourceManager申请application ID,此ID为该MapReduce的jobId。
2、检查output的路径是否正确,是否已经被创建。
3、计算input的splits。
4、拷贝运行job 需要的jar包、配置文件以及计算input的split 到各个节点。
5、在ResourceManager中调用submitAppliction()方法,执行job
Job 初始化过程
1、当resourceManager收到了submitApplication()方法的调用通知后,scheduler开始分配container,随之ResouceManager发送applicationMaster进程,告知每个nodeManager管理器。
2、 由applicationMaster决定 如何运行tasks,如果job数据量比较小,applicationMaster便选择 将tasks运行在一个JVM中 。那么如何判别这个job是大是小呢?当一个job的 mappers数量小于10个 , 只有一个reducer或者读取的文件大小要小于一个HDFS block时 ,(可通过修改配置项mapreduce.job.ubertask.maxmaps,mapreduce.job.ubertask.maxreduces以及mapreduce.job.ubertask.maxbytes 进行调整)
3、在运行tasks之前,applicationMaster将会 调用setupJob()方法 ,随之创建output的输出路径(这就能够解释,不管你的mapreduce一开始是否报错,输出路径都会创建)
Task 任务分配
1、接下来applicationMaster向ResourceManager请求containers用于执行map与reduce的tasks(step 8),这里map task的优先级要高于reduce task,当所有的map tasks结束后,随之进行sort(这里是shuffle过程后面再说),最后进行reduce task的开始。(这里有一点,当map tasks执行了百分之5%的时候,将会请求reduce,具体下面再总结)
2、运行tasks的是需要消耗内存与CPU资源的, 默认情况下,map和reduce的task资源分配为1024MB与一个核 ,(可修改运行的最小与最大参数配置,mapreduce.map.memory.mb,mapreduce.reduce.memory.mb,mapreduce.map.cpu.vcores,mapreduce.reduce.reduce.cpu.vcores.)
Task 任务执行
1、这时一个task已经被ResourceManager分配到一个container中,由applicationMaster告知nodemanager启动container,这个task将会被一个 主函数为YarnChild 的java application运行,但在运行task之前, 首先定位task需要的jar包、配置文件以及加载在缓存中的文件 。
2、YarnChild运行于一个专属的JVM中,所以 任何一个map或reduce任务出现问题,都不会影响整个nodemanager的crash或者hang 。
3、每个task都可以在相同的JVM task中完成,随之将完成的处理数据写入临时文件中。
Mapreduce数据流
运行进度与状态更新
1、MapReduce是一个较长运行时间的批处理过程,可以是一小时、几小时甚至几天,那么Job的运行状态监控就非常重要。每个job以及 每个task都有一个包含job(running,successfully completed,failed)的状态 ,以及value的计数器,状态信息及描述信息(描述信息一般都是在代码中加的打印信息),那么,这些信息是如何与客户端进行通信的呢?
2、当一个task开始执行,它将会保持运行记录,记录task完成的比例,对于map的任务,将会记录其运行的百分比,对于reduce来说可能复杂点,但系统依旧会估计reduce的完成比例。当一个map或reduce任务执行时, 子进程会持续每三秒钟与applicationMaster进行交互 。
Job 完成
最终,applicationMaster会收到一个job完成的通知,随后改变job的状态为successful。最终,applicationMaster与task containers被清空。
Shuffle与Sort
从map到reduce的过程,被称之为shuffle过程,MapReduce使到reduce的数据一定是经过key的排序的,那么shuffle是如何运作的呢?
当map任务将数据output时, 不仅仅是将结果输出到磁盘,它是将其写入内存缓冲区域,并进行一些预分类 。

1、The Map Side
首先map任务的 output过程是一个环状的内存缓冲区,缓冲区的大小默认为100MB (可通过修改配置项mpareduce.task.io.sort.mb进行修改),当写入内存的大小到达一定比例 ,默认为80% (可通过mapreduce.map.sort.spill.percent配置项修改),便开始写入磁盘。
在写入磁盘之前,线程将会指定数据写入与reduce相应的patitions中,最终传送给reduce.在每个partition中 ,后台线程将会在内存中进行Key的排序 ,( 如果代码中有combiner方法,则会在output时就进行sort排序 ,这里,如果只有少于3个写入磁盘的文件,combiner将会在outputfile前启动,如果只有一个或两个,那么将不会调用)
这里 将map输出的结果进行压缩会大大减少磁盘IO与网络传输的开销 (配置参数mapreduce.map .output.compress 设置为true,如果使用第三方压缩jar,可通过mapreduce.map.output.compress.codec进行设置)
随后这些paritions输出文件将会通过HTTP发送至reducers,传送的最大启动线程通过mapreduce.shuffle.max.threads进行配置。
2、The Reduce Side
首先上面每个节点的map都将结果写入了本地磁盘中,现在reduce需要将map的结果通过集群拉取过来,这里要注意的是, 需要等到所有map任务结束后,reduce才会对map的结果进行拷贝 ,由于reduce函数有少数几个复制线程,以至于它 可以同时拉取多个map的输出结果。默认的为5个线程 (可通过修改配置mapreduce.reduce.shuffle.parallelcopies来修改其个数)
这里有个问题,那么reducers怎么知道从哪些机器拉取数据呢?
当所有map的任务结束后, applicationMaster通过心跳机制(heartbeat mechanism),由它知道mapping的输出结果与机器host ,所以 reducer会定时的通过一个线程访问applicationmaster请求map的输出结果 。
Map的结果将会被拷贝到reduce task的JVM的内存中(内存大小可在mapreduce.reduce.shuffle.input.buffer.percent中设置)如果不够用,则会写入磁盘。当内存缓冲区的大小到达一定比例时(可通过mapreduce.reduce.shuffle.merge.percent设置)或map的输出结果文件过多时(可通过配置mapreduce.reduce.merge.inmen.threshold),将会除法合并(merged)随之写入磁盘。
这时要注意, 所有的map结果这时都是被压缩过的,需要先在内存中进行解压缩,以便后续合并它们 。(合并最终文件的数量可通过mapreduce.task.io.sort.factor进行配置) 最终reduce进行运算进行输出。
这里附带的整理了下Parquet存储结构与SequenceFile存储结构的特点
Parquet
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,那么这里就总结下Parquet数据结构到底是什么样的呢?
一个Parquet文件是 由一个header以及一个或多个block块组成,以一个footer结尾 。header中只包含一个4个字节的数字PAR1用来识别整个Parquet文件格式。文件中 所有的metadata都存在于footer中 。footer中的metadata包含了格式的版本信息,schema信息、key-value paris以及所有block中的metadata信息。footer中最后两个字段为一个以4个字节长度的footer的metadata,以及同header中包含的一样的PAR1。
读取一个Parquet文件时,需要完全读取Footer的meatadata,Parquet格式文件不需要读取sync markers这样的标记分割查找,因为所有block的边界都存储于footer的metadata中(因为metadata的写入是在所有blocks块写入完成之后的,所以吸入操作包含的所有block的位置信息都是存在于内存直到文件close)
这里注意,不像sequence files以及Avro数据格式文件的header以及sync markers是用来分割blocks。Parquet格式文件不需要sync markers,因此block的边界存储与footer的meatada中。
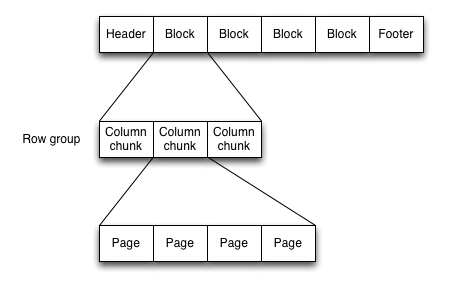
在Parquet文件中,每一个block都具有一组Row group,她们是由一组Column chunk组成的列数据。继续往下,每一个column chunk中又包含了它具有的pages。每个page就包含了来自于相同列的值.Parquet同时使用更紧凑形式的编码,当写入Parquet文件时,它会自动基于column的类型适配一个合适的编码,比如,一个boolean形式的值将会被用于run-length encoding。
另一方面,Parquet文件对于每个page支持标准的压缩算法比如支持Snappy,gzip以及LZO压缩格式,也支持不压缩。
Parquet格式的数据类型:

Hadoop SequenceFile
在一些应用中,我们需要一种特殊的数据结构来存储数据,并进行读取,这里就分析下为什么用SequenceFile格式文件。
Hadoop提供的SequenceFile文件格式提供一对key,value形式的不可变的数据结构。同时,HDFS和MapReduce job使用SequenceFile文件可以使文件的读取更加效率。
SequenceFile的格式
SequenceFile的格式是 由一个header 跟随一个或多个记录组成 。前三个字节是一个Bytes SEQ代表着版本号,同时header也包括key的名称,value class , 压缩细节,metadata,以及Sync markers。Sync markers的作用在于可以读取任意位置的数据。
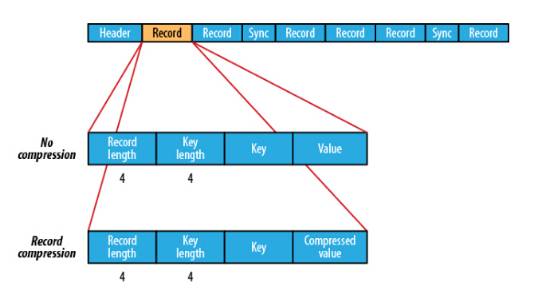
在recourds中,又分为是否压缩格式。当没有被压缩时,key与value使用Serialization序列化写入SequenceFile。当选择压缩格式时,record的压缩格式与没有压缩其实不尽相同,除了value的bytes被压缩,key是不被压缩的。
在Block中,它使所有的信息进行压缩,压缩的最小大小由配置文件中,io.seqfile.compress.blocksize配置项决定。
SequenceFile的MapFile
一个MapFile可以通过SequenceFile的地址,进行分类查找的格式。使用这个格式的优点在于,首先会将SequenceFile中的地址都加载入内存,并且进行了key值排序,从而提供更快的数据查找。
写SequenceFile文件:
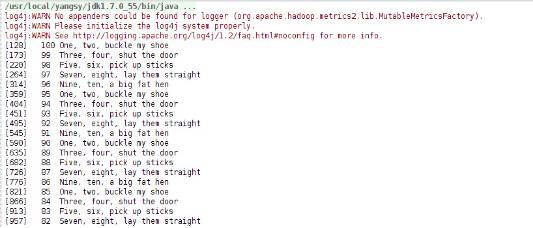
将key按100-1以IntWritable object进行倒叙写入sequence file,value为Text objects格式。在将key和value写入Sequence File前,首先将每行所在的位置写入(writer.getLength())
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.IOException;import java.net.URI;
public class SequenceFileWriteDemo {
private static final String[] DATA = {
“One, two, buckle my shoe”,
“Three, four, shut the door”,
“Five, six, pick up sticks”,
“Seven, eight, lay them straight”,
“Nine, ten, a big fat hen”
};
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path,
key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 – i);
value.set(DATA[i % DATA.length]);
System.out.printf(“[%s]/t%s/t%s/n”, writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
读取SequenceFile文件:
首先需要创建SequenceFile.Reader实例,随后通过调用next()函数进行每行结果集的迭代(需要依赖序列化).
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.IOException;import java.net.URI;
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {//同步记录的边界
String syncSeen = reader.syncSeen() ? “*” : “”;
System.out.printf(“[%s%s]/t%s/t%s/n”, position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
参考文献:《Hadoop:The Definitive Guide, 4th Edition》
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

