暴走漫画基于公有云的容器架构实践
Author:Micheal Ding
很高兴能和大家分享一些暴走漫画基于公有云的容器化架构的实践经验
基于之前在暴漫的经验,我到了扇贝以后,大概用了一个月的时间,就将扇贝的产品成功迁移到了容器环境中,并做了很多改进,也有了更多的思考。
暴走漫画(以下简称"暴漫")相信大家都不陌生,它应该算一个互联网应用。先简单介绍一下背景:暴漫主要做App和网站,后端主要是Ruby,也有一些Python、Scala的异构化系统。整体架构是标准的互联网应用架构。包括负载均衡、Nginx、应用服务器、数据库(MySQL),等等。这里暂时讲不到资源编排和调度(mesos/k8s)
就在去年(2015)暴漫在推进容器。这当中一直在考虑的事情就是怎样更好的将容器为我们所用。原来暴漫的所有东西都是跑在云主机(Ucloud)上,环境也是零散的脚本拼凑起来的,经过了大概一年的摸索和实践,现在基本上所有的东西都实现了容器化。
这里简单提一下暴漫和扇贝的情况:1. 产品差别很大;2. 公司风格差别也很大,暴漫很轻松,扇贝则相反;3. 技术栈,暴漫后端主要为Ruby、Ucloud,扇贝是Python、阿里云;暴漫老板非技术出身,扇贝老板则是技术出身;4. 规模相差不大,暴漫6~70人,扇贝4~50人,服务器百台左右,都没有专业运维
Consul简介
原来在暴漫用的是etcd,之后在扇贝换成了Consul。两者之间的特性和核心功能是一样的,为什么换成Consul呢?因为Consul在核心功能的基础上提供了三个非常重要的特性。etc要找对应的第三方的组件配合搭建,Consul已经直接包含了。1. 服务发现;2. Failure Detection;3. DNS;我觉得这三个特性很适合我们公有云用容器的场景。比如:启动ES的一个节点,往Consul服务器上发送一个http request,然后用DNS查询就能发现此节点。这样就可以提供高可用的ES服务。传统做法你需要维护一个节点列表,客户端随机往此列表发请求,或者在前面加HAProxy随机发请求,如果用Consul服务发现和DNS做负载均衡就简单多了:ES的集群每个节点都向Consul注册服务,利用DNS查询,Consul可以动态的改变节点在结果中的顺序,每次取到的节点都是随机的。
Failure Detection可以监控每个节点的健康情况,自动踢出DNS列表中挂掉的节点。
Consul支持多数据中心,我们实际应用中将生产环境和开发环境分离到了两个不同的数据中心中。
Docker简介
首先将容器和VM做一个对比:Docker是一个进程级别的包装,VM是一个环境的虚拟,这里用一个故事来比喻可能更形象一些:从前有一个国王,特别喜欢踩在牛皮上走路,不喜欢踩在地上。当时有两个大臣提了两个方案:一个大臣说给全国的路都铺上牛皮,这样不管走在哪里都是踩在牛皮上了;另一个大臣则说给国王做牛皮靴,只要穿着牛皮靴,走到哪儿都是踩在牛皮上。这刚好说明了VM和Docker在思路上的本质区别:VM是铺路,Docker则是牛皮靴。
关于为什么用了云主机后还要上Docker,好处相信大家都知道:1. 对开发更友好,且保证了各环境的一致性;2. 环境的快速部署,避免了重复劳动和升级的麻烦;3. 节省资源,将一些不常用的服务跑在一台VM上而不是单独跑在几台VM上。
service distribution workflow
现在总结一下:Consul用来做服务发现,负载均衡,Docker用来封装服务,我们内部所有的服务,从开发到运行都会经历三个步骤:1. build images,开发生产用的同一个image;2. upload,将build好的images上传;3. 在不同的VM上把服务跑起来,其中又分为三个小步骤:第一步从Consul拉取配置,第二步创建对应的容器,第三步就是向Consul注册服务了。
2 types of services
说到服务,通常书本上都喜欢把服务分为有状态服务和无状态服务,但我们是根据容器的重启方式来划分:一般服务和gracefully reload。容器重启可以闲结束之前的容器再启一个新的,另一种则不能stop,暴漫和扇贝的日活还是很大的,如果stop一个节点或者该节点出了问题,会导致其它节点负载急剧增大,平均响应时间从一百多毫秒上升到七八百毫秒。
第一种操作很简单,通过Consul可以得到现在已有的节点信息,通过发送http request来检查节点是否活着;对于第二种不能随便重启的服务,我们直接通过docker kill而不是docker stop/run来重启,也就是给docker container主进程发不同的信号,这里用uwsgi举例:它提供了一种机制,你给它发不同的信号会有不同的反应,你发送HUP信号,它都会执行一次reload,过程大概是这样:uwsgi有一个主进程master,master不处理任何请求,它会fork出若干的worker进程,worker的个数可以自定义,我们以5个为例,如果发HUP给master,让master reload,master会先创建5个子进程,我们称之为新worker进程,等子进程创建完了以后,master会检查老的worker还有没有请求在处理,等待所有请求处理完就kill掉老的worker,没有请求的直接kill掉,reload以后的请求都转给新的worker处理,所以这是一个平滑的重启过程。除了信号之外,其次就是代码的更新。重启的目的就是为了更新的代码。在这种服务类型的容器中,我们的代码是通过mount数据卷来做的,image只有基础环境。比如:python环境要一些数值计算的库,代码在数据卷上更新,更新完以后就去调这个函数,然后给它发HUP,重启以后运行的就是更新后的代码。
web系统的架构
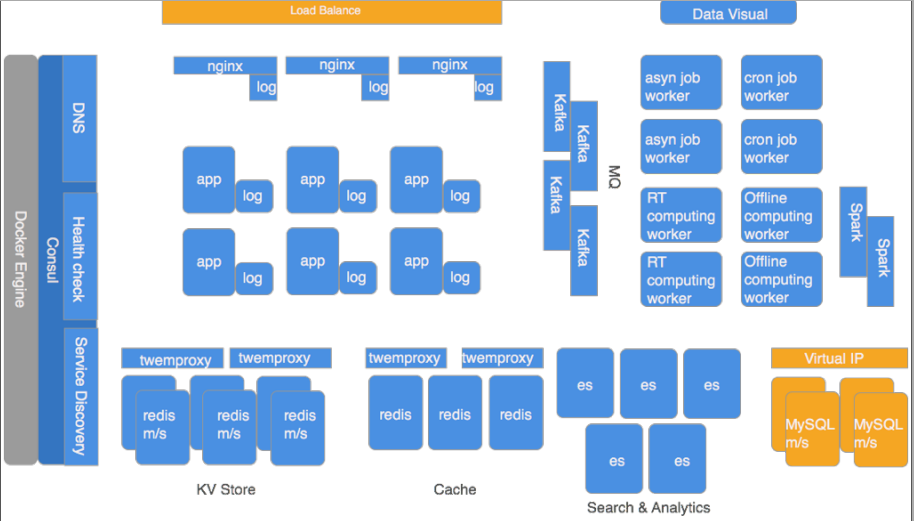
图为我们现在的架构。蓝色的部分都是放在Docker里的,灰色的部分跑在云主机VM上,黄色的部分是云服务商提供。从左往右看的话,所有的东西都是基于Docker,当然还有Consul。我们在注册服务和服务检查的时候都是和本地的Consul打交道,整个架构都是分布式的,就不存在一个Consul刮掉导致整个系统瘫痪的问题。Consul提供三个最主要的功能。比如nginx到app,app到redis,app到mysql都是通过DNS,不通过IP。
就我们现有的架构和mesos/k8s做了一个简单的类比,因为我们基于阿里云,我们不需要关心资源的计划、计算等。考虑到现有团队规模,水平、技能点灯各种重要因素,觉得那一套并不适合我们。我们用的human schedule,基于阿里云的API资源的分配、ansible/scripts自动化、Consul负载均衡、docker环境封装等。
最后强调一点:不管你怎么设计你的架构,怎么设计你的系统,我们现在还很难做到完全不用人去运维。而且在后续的升级、后续的重构、后续的改进当中都是需要人去做的。所以你选用什么样的架构,一定要先考虑到你们的团队,现有的构成,你们的预算,团队现有的水平也好,人数也好,技能点的分布也好,这些东西都是非常重要的,只有充分考虑到这些以后,你再去选对应的架构。我觉得我们现在这一套就适合几十人,可能100人以内还可以应付,如果技术团队哪天爆发到两三百人,这一套估计就不适合了,这个就是充分考虑到团队的,我们也没有专业的运维,就是开发在做运维,所以我们也尽可能希望我们的运维工作可编程化,所以我们会上Docker,会上这些工具。而且Docker+Consul已经足够了。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

