THE GOLDILOCKS PRINCIPLE: READING CHILDREN’S BOOKS WITH EXPLICIT MEMORY REPRESENTATIONS #Pa...
本文是机器阅读理解系列的第五篇文章,将会分享的题目是 THE GOLDILOCKS PRINCIPLE: READING CHILDREN’S BOOKS WITH EXPLICIT MEMORY REPRESENTATIONS ,作者是来自剑桥大学的博士生 Felix Hill ,本文的工作是在Facebook AI Research完成的,文章最早于2016年4月1日submit在arxiv上,后来发表在ICLR 2016会议上。
本文的贡献主要是两点:一是构建了一个新的语料,Children’s Book Test(CBT),丰富了机器阅读理解任务的数据源;二是将Facebook提出的Memory Network框架应用到了机器阅读理解任务中,并取得了不错的结果。
首先,来介绍CBT。CBT的数据均来自 Project Gutenberg ,使用了其中的与孩子们相关的故事,这是为了保证故事叙述结构的清晰,从而使得上下文的作用更加突出。每篇文章只选用21句话,前20句作为document,将第21句中去掉一个词之后作为query,被去掉的词作为answer,并且给定10个候选答案,每个候选答案是从原文中随机选取的,并且这10个答案的词性是相同的,要是名词都是名词,要是命名实体都是实体,要是动词都是动词。例子看下图:

左图为电子书的原文,右图为构建成数据集之后的几个元素,document、query、answer和candidate。数据集根据词性一共分为四类,第一类是Named Entity,第二类是Nouns,第三类是Verbs,第四类是Preposition。这里,用LSTM RNNLM从query本身出发就可以非常准确地预测出Verbs和Preposition,不需要借助过多的document context,但是对于前两类却束手无策。因此本文提出了用Memory Network来解决这个问题。
Memory Network是Facebook提出的框架,在nlp的很多任务中都表现出色,比如语言模型。
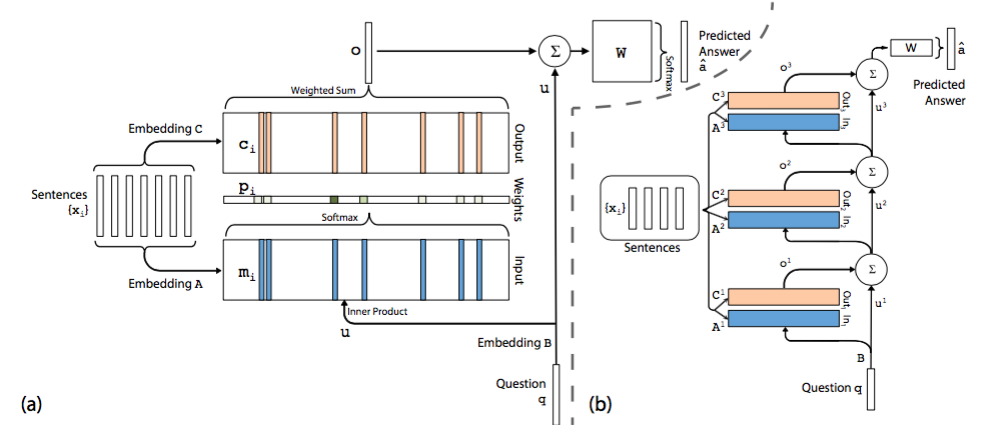
原文中没有模型结构图,该图来自于文章 End-To-End Memory Networks 。左图是一个单层的Memory Network,右图是一个多层的Network。
首先,介绍下单层模型。
模型将document中的每一个word保存为一个memory m(i),每个memory本质上就是一个向量,这一点与embedding是一回事,只是换了一个名词。另外每个word还与一个输出向量c(i)相关联。可以理解为每个word表示为两组不同的embedding A和C。同样的道理,query中的每个单词可以用一个向量来表示,即对应着另一个embedding B。
在Input memory表示层,用query向量与document中每个单词的m(i)作内积,再用softmax归一化得到一组权重,这组权重就是attention,即query与document中每个word的相关度,与昨天的AS Reader模型有些类似。
接下来,将权重与document中的另一组embedding c(i)作加权平均得到Output memory的表示。
最后,利用query的表示和output memory的表示去预测answer。
然后,介绍下右图的多层模型。根据单层模型的结构,非常容易构造出多层模型。每一层的query表示等于上一层query表示与上一层输出memory表示的和。每一层中的A和C embedding有两种模式,第一种是邻接,即A(k+1) = C(k),依次递推;第二种是类似于RNN中共享权重的模式,A(1) = A(2) = … = A(k),C(1) = C(2) = … = C(k)。其他的过程均和单层模型无异。
本文模型的特点是易于构造更多层的模型,从而取得更好的效果。我们之前分享过的一篇文章 Gated-Attention Readers for Text Comprehension 就是借鉴了其中的思想,从而获得了目前来说最棒的结果。前面的文章给我的启示是,简单的模型反而会得到更好的结果,而本文给我的一个感觉是,如果你用了更多的layer也可能会获得不错的结果。如果你用了很多层非常简单的模型会不会得到更好的结果呢?这是一个需要思考和认真实践的问题。
明天将会继续介绍一篇机器阅读理解的单文,周末将会写一篇类似综述的文章,系统地对比下各种模型和结果。
工具推荐
RSarXiv 一个好用的arxiv cs paper推荐系统 网站地址 ios App下载:App Store 搜索rsarxiv即可获得
PaperWeekly,每周会分享N篇nlp领域好玩的paper,旨在用最少的话说明白paper的贡献。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

