MongoDB复制集自适应oplog管理
MongoDB复制集运行过程中,经常可能出现Secondary同步跟不上的情况,主要原因是 主备写入速度上有差异,而复制集配置的oplog又太小 ,这时需要人工介入,向Secondary节点发送resync命令。
上述问题可通过配置更大的oplog来规避,目前 官方文档建议的修改方案 步骤比较长,而且需要停写服务来做,大致过程是先把oplog备份,然后再oplog集合删掉,重新创建,再把备份的内容导入到新创建的oplog。
我们团队针对使用wiredtiger存储引擎的场景,开发了通过collMod命令在线修改oplog大小的功能,已向官方提交了 pull request ,大家应该能在下一个大版本3.4里享受到这个功能。
即使有了在线修改oplog的功能,从运维角度看,还是需要人去感知到『复制集需要更大oplog』这个需求,然后去进行调整;但实际上复制集的每个成员都是了解所有节点当前的复制状况的(rs.status()的输出,可以看到每个节点最新的optime),Primary只要根据这个信息自适应的保留oplog即可,保证同步最慢的节点也能跟上。
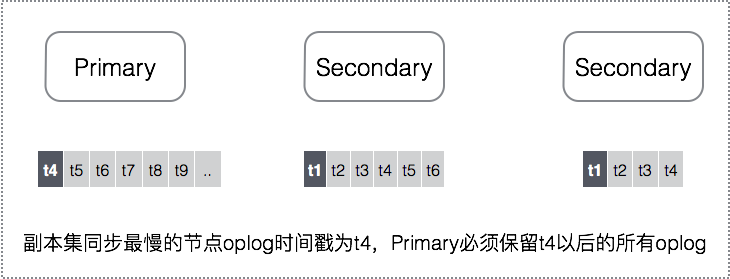
为了实现上述功能,我们改造了 oplog删除的策略 ,支持『在oplog删除时,只能删除某个特定时间戳之前的oplog』,每个成员不断的根据复制集最慢节点的optime来更新时间戳,这样就能保证同步最慢的节点需要的oplog一定存在,避免了同步跟不上的场景。功能稳定后,我们会将patch提到JIRA上,让社区用户也能用上这个特性,免去管理oplog的烦恼。
参考资料
- 阿里云MongoDB云数据库
- MongoDB Secondary同步慢问题分析
- MongoDB Secondary同步慢问题分析(续)
- 修改oplog方案
- oplog删除的策略
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

