Docker Swarm系列第二部:重新调度Redis
欢迎回来,我们继续本系列的第二篇教程。今天我们将主要关注 Redis ,希望大家还记得第一部分的主要内容——了解如何安装我们将要使用的环境。
传送门: Docker Swarm系列第一部:利用Flocker部署多节点Cassandra集群
在发生节点故障时利用Swarm对Redis服务器进行重新调度
如果大家认真阅读了第一部分,应该记得我们在Swarm部署中使用了--experimental标记。其中包括Swarm 1.1.0中的一项功能——在节点故障时对容器进行重新调度。
今天,我们将关注如何部署Redis容器并测试当前实验性重新调度功能的当前状态。
注意:重新调度尚处于实验阶段,其中存在bug。我们将在示例过程中的对应位置提醒大家可能出现的bug。
如果大家希望在Swarm主机发生故障时对容器进行重新调度,则需要在容器部署中使用特定标记。作为可行方案之一,我们可以使用以下标记:--restart=always -e reschedule:on-node-failure或者类似于-l 'com.docker.swarm.reschedule-policy=["on-node-failure"]'的标签。以下示例将使用环境变量方法。
首先,我们使用重新调度标记与由Flocker管理的分卷进行Redis容器部署。
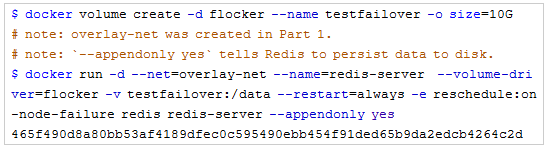
接下来,利用SSH接入Docker主机内的Redis容器运行位置,并查看Redis始终使用的appendonly.aof文件内容。该文件应当位于Flocker分卷中,作为容器起始点存在且不包含任何数据。

然后接入Redis服务器并添加一些键/值对。而后,再次查看appendonly.aof文件内容以确保Redis以正确方式存储数据。
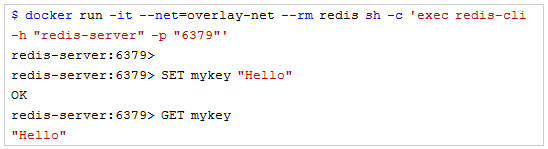
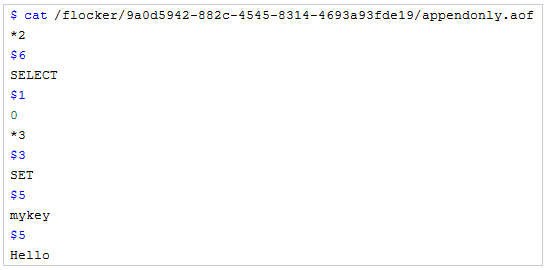
在Flocker分卷中查看数据以验证Redis正确运行。
测试故障转移
现在我们将测试故障转移场景,确保我们的Flocker分卷能够将存储在Redis中的数据正确迁移至Swarm重新调度容器的新Docker主机上。
要实现这一目标,我们在Swarm管理器中指定Docker,并利用docker events命令监控各项事件。
要开始测试,首先在运行有Redis容器的Docker主机上运行shutdown -h now以模拟节点故障。大家应该看到与该节点及容器相关的各项事件。
这些事件在告知我们,该容器及其资源由于遭遇故障(包括网络与分卷)需要被移除、断开连接或者卸载。我们看到的事件如下:
Container Kill
Container Die
Network Disconnect
Swarm Engine Disconnect
Volume Unmount
Container Stop

在Docker主机关闭一段时间之后,大家应该会最终看到故障容器正在进行重新调度(即重新创建)。在这里需要提醒的是,在测试中我们发现Swarm 1.1.3版本中仍然存在问题,即其仍然会在被创建在新Docker主机上的容器中运行 Start 。
大家应该会在查看到Create事件记录的同时发现docker events,而后者的作用是对容器重建以及Flocker分卷移动进行初始化。
我们发现,大家可能需要在重新调度完成后,在新主机上手动Start该容器。
注意:容器创建过程中存在一些问题,但在测试中我们并未在容器启动时发现问题。
此事件代表着我们的容器已经经过重新调度并自动创建于新的Docker主机之上。请注意,最新信息中的IP地址发生了变化,这是因为容器被调度到了新的Docker主机中。
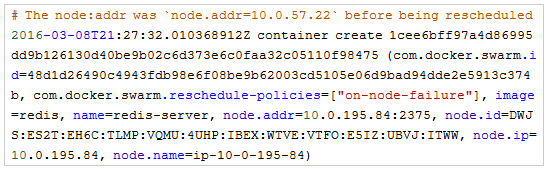
回顾
下面来看流程回顾:

如果我们对Swarm运行docker ps,则会看到该Redis容器为Created。在这种情况下,我们可以手动进行启动,而Redis也将恢复并运行在新节点上。
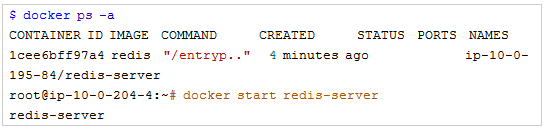
下面接入该Redis服务器以确保我们添加的数据仍然存在。

数据仍然存在!不过考虑到重新调度情况,我们不建议大家直接使用这些数据。
在测试当中,大部分用户反映容器能够在新节点上正常启动。但也确实有部分用户指出重新调度机制并未生效,或者是在Docker主机恢复后出现了两套容器。无论如何,工作当中显然还存在着问题,而社区的作用也正在于此——帮助测试、报告并修复这些问题,从而确保其运行效果更为可靠。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

