数据描述 3 - 间接寻址 & 模拟指针
继续是《数据结构算法与应用:C++语言描述》第3章数据描述的笔记。本小节讲述间接寻址和模拟指针的内容。
间接寻址
基本概念
间接寻址(indirect addressing)是公式化描述和链表描述的组合。
采用这种描述方法,可以保留公式化描述的优点– 可以根据索引在$/theta(1)$的时间内访问每个元素,可采用二叉搜索方法在对数时间内对一个有序表进行搜索等等 。同时,也可以获得链表描述方法的重要特色– 在诸如插入和删除操作期间不必对元素进行实际的移动 ,因此大多数间接寻址链表操作的时间复杂性都与元素的总数无关。
间接寻址中,使用一个指针表来跟踪每个元素。元素本身可能存储在动态分配的节点或者节点数组之中。下图给出一个采用间接寻址表table描述的5元素线性表。其中table[i]是一个指针,它指向表中的第i+1个元素,length是表的长度。
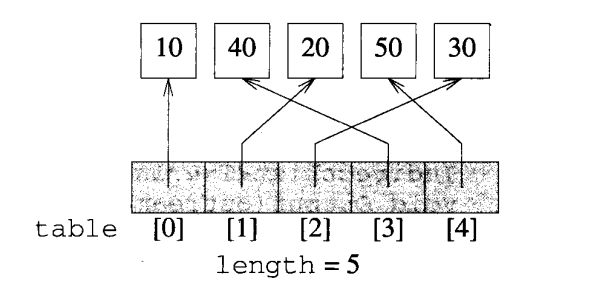
间接寻址方法和链表描述方法都使用了指针域。在链表方式中,指针位于每个节点中,而在间接寻址方式中,指针完全放在数组table中。
下面给出了类定义
#ifndef INDRECTLIST_H_ #define INDRECTLIST_H_ #include<iostream> template<class T> class IndrectList{ private: T **table; // 一维T类型指针数组 int length, MaxSize; public: IndrectList(int MaxListSize = 10); ~IndrectList(); bool isEmpty() const{ return length == 0; } int Length() const { return length; } bool Find(int k, T&x)const; int Search(const T& x)const; IndrectList<T>& Delete(int k, T& x); IndrectList<T>& Insert(int k, const T& x); void Output(std::ostream& out)const; }; #endif
操作
下面给出构造函数和析构函数的代码实现:
template<class T> IndrectList<T>::IndrectList(int MaxListSize){ MaxSize = MaxListSize; table = new T *[MaxSize]; length = 0; } template<class T> IndrectList<T>::~IndrectList(){ // 删除表 for (int i = 0; i < length; i++) delete table[i]; delete[] table; }
函数 Length 和 IsEmpty 都已经被定义为内联函数。假设$1/le k /le length$,第k个元素可以由 table[k-1] 之后的下一个指针指出,对x进行搜索可以通过依次检查指针table[0]、table[1]、…所指向的元素。下面给出 Find和Search 函数的代码实现:
template<class T> bool IndrectList<T>::Find(int k, T& x)const{ if (k<1 || k>length) return false; x = *table[k - 1]; return true; } template<class T> int IndrectList<T>::Search(const T& x)const{ // 返回x所处位置,如果没有则返回0; for (int i = 0; i < length; i++){ if (*table[i] == x) return ++i; } return 0; }
删除操作需要移动要删除的元素后面的指针,相对于公式化操作中需要移动的是表中的元素。删除操作实现如下所示
template<class T> IndrectList<T>& IndrectList<T>::Delete(int k, T&x){ if (Find(k, x)){ // 向前移动指针 for (int i = k; i < length; i++) table[i - 1] = table[i]; length--; return *this; } else throw OutOfBounds(); }
上述实现中,首先是借助 Find 函数寻找到需要删除的第k个元素,然后将第k个元素开始的所有指针都往前移动一位。
插入操作和删除操作相反,需要将指针往后移动,实现如下:
template<class T> IndrectList<T>& IndrectList<T>::Insert(int k, const T& x){ if (k<0 || k>length) throw OutOfBounds(); if (length == MaxSize) throw NoMem(); // 向后移动一位 for (int i = length - 1; i >= k; i--) table[i + 1] = table[i]; table[k] = new T; *table[k] = x; length++; return *this; }
插入操作在最坏情况下的时间复杂性是$O(length)$,而对于公式化操作,其最坏情况下的时间复杂性是$O(s*length)$,其中 s 是一个T类型的元素的大小。
更完整的例子可以查看我的 github
模拟指针
在大多数应用中,可以利用动态分配及C++指针来实现链表和间接寻址表。不过有时候,可以采用一个节点数组以及对该数组进行索引的模拟指针,可以使设计更方便、更高效。
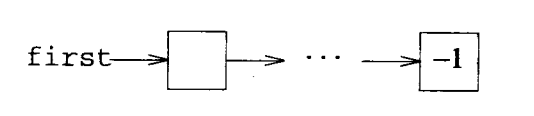
假设采用一个数组node,该数组的每个元素都包含两个域: data和link 。数组中的节点分别是 node[0]、node[1]、...、node[NumberOfNodes - 1] 。下面用 节点i 来代表 node[i] 。如果一个单向链表 c 由节点10,5和24按顺序构成,那么将得到 c=10 (指向链表 c 的第一个节点的指针是整数类型), node[10].link = 5 (指向第二个节点的指针), node[5].link = 24,node[24].link=-1(表示节点24是链表中的最后一个节点) 。该链表如下图所示:

为了实现指针的模拟,需要设计一个过程来分配和释放一个节点。当前未被使用的节点将被放入一个存储池之中。开始时,存储池中包含了所有节点 node[0:NumberOfNodes-1] 。 Allocate 从存储池中取出节点,每次取出一个。而 Deallocate 则将节点放入存储池中,每次放入一个。因此 Allocate和Deallocate 分别对存储池执行插入和删除操作,等价于C++函数的new和delete。如果存储池是一个节点链表,如下所示,这两个函数就可以高效地执行。用作存储池的链表被称之为 可用空间表 ,其中包含了当前未使用的所有节点。 first 是一个类型为int的变量,它指向可用空间表的第一个节点,添加和删除操作都是在可用空间表的前部进行的。
代码实现如下所示:
#ifndef SIMPOINTER_H_ #define SIMPOINTER_H_ template<class T> class SimNode{ T data; int link; }; template<class T> class SimSpace{ private: int NumberOfNodes, first; SimNode<T>*node; // 节点数组 public: SimSpace(int MaxSpaceSize = 100); ~SimSpace(){ delete[] node; } // 分配一个节点 int Allocate(); // 释放节点i void Deallocate(int& i); }; #endif
上述就是节点数组以及可用空间表的代码实现。
SimSpace的操作
由于所有节点初始时都是自由的,因此在刚被创建的时候,可用空间表中包含 NumberOfNodes 个节点。代码实现如下所示:
template<class T> SimSpace<T>::SimSpace(int MaxSpaceSize){ NumberOfNodes = MaxSpaceSize; node = new SimNode<T>[NumberOfNodes]; // 初始化可用空间表,创建一个节点链表 for (int i = 0; i < NumberOfNodes-1; i++) node[i].link = i + 1; // 链表的最后一个节点 node[NumberOfNodes - 1].link = -1; // 链表的第一个节点 first = 0; } template<class T> int SimSpace<T>::Allocate(){ // 分配一个自由节点 if (first == -1) throw NoMem(); int i = first; first = node[i].link; // first 指向下一个自由节点 return i; } template<class T> void SimSpace<T>::Deallocate(int & i){ // 释放节点 // 使i成为可用空间表的第一个节点 node[i].link = first; first = i; i = -1; }
上面三个函数的时间复杂性分别是$/theta(NumberOfNodes),/theta(1),/theta(1)$。
通过使用两个可用空间表,可用减少构造函数的运行时间,其中第一个表包含所有尚未被使用的自由节点,第二个表包含所有已被至少使用过一次的自由节点。每当一个节点被释放时,就被放入第二个表中。当需要一个新节点时,如果第二个表非空,则从该表中取出一个节点,否则从第一个表中取出一个节点。令 first1 和 first2 分别指向第一个表和第二个表的首节点。
基于上述分配节点的方式,第一个表中的元素是 node[i] ,其中$first1 /le i /lt NumberOfNodes$。释放节点的代码与上述代码中 Deallocate 方法的唯一区别是所有 first 变量均替换成 first2 。新的构造函数和分配函数如下所示。为了使新函数能正常工作,需要把整型变量 first1 和 first2 设置为 SimSpace 的私有成员变量。
template<class T> SimSpace<T>::SimSpace(int MaxSpaceSize) { // 使用两个可用空间表的构造函数 NumberOfNodes = MaxSpaceSize; node = new SimNode<T> [NumberOfNodes]; // 初始化可用空间表 firstl = 0; first2 = -1; } template<class T> int SimSpace<T>::Allocate() { // 分配一个自由节点 if (first2 == -1) {// 第2个表为空 if (firstl == NumberOfNodes) throw NoMem(); return firstl++;} // 分配链表中的第一个节点 int i = first2; first2 = node[i].link; return i; }
描述方法的比较
下图给出了本章四种数据描述方法执行各种链表操作所需要的时间复杂性。表中, s 和 n 分别表示 sizeof(T) 和链表长度。由于采用C++指针和采用模拟指针完成这些操作所需要的时间复杂性完全相同,因此表中把这两种情形的时间复杂性合并在一行中进行描述。
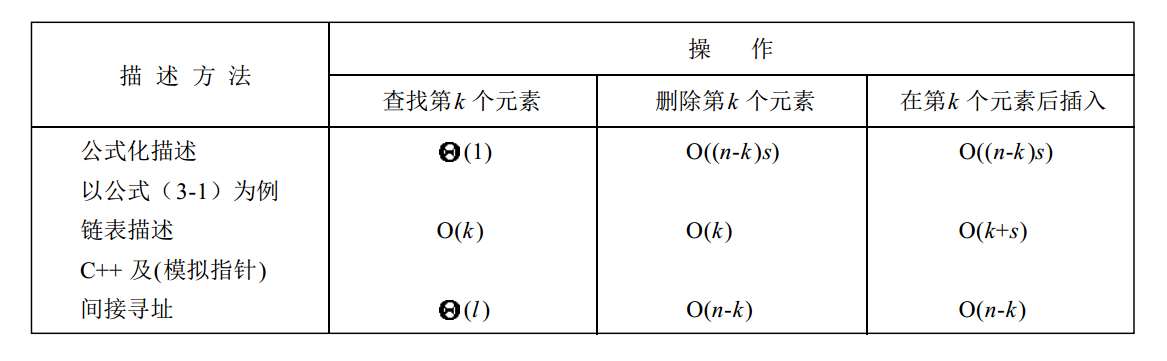
有上述表格以及前面所学的知识可以得到以下结论:
- 使用间接寻址与使用链表描述所需要的空间大致相同,二者都比使用公式化描述所需要的空间更多。
- 链表描述和间接寻址,在执行链表的插入和删除操作所需要的时间复杂性都与链表元素本身的大小无关;相反,使用公式化描述时,插入和删除操作的复杂性与元素的本身大小呈 线性关系 。
- 公式化描述和间接寻址,在确定表的长度以及访问表中第k个元素所需要的时间复杂性均为$/theta(1)$;而使用链表描述,这两种操作的时间复杂性分别是$/theta(length)$和$O(k)$。
- 间接寻址比较适合这样的应用:表元素本身很大,较频繁地进行插入、删除操作以及确定表的长度、访问第k个元素。
- 如果线性表本身已经按序排列,那么使用公式化描述或间接寻址进行搜索所需要时间均为$O(logn)$,而使用链表描述时,所需要的时间是$O(n)$.
小结
本小节介绍了间接寻址和模拟指针两种实现线性表的方法。间接寻址还是可以理解的,实际上就是综合了公式化描述和链表描述的特点,指向数据元素的指针使用一个数组(实现代码中是命名为 table )来存放,数据元素放在动态分配的节点数组中。这样数组的顺序也就是每个元素存放的顺序,这样有利于快速访问第k个元素,同时在插入和删除操作方面需要移动的是指针在数组的位置,而不是元素本身,速度也是相对更快。
对于模拟指针,由于还是首次接触,所以还是不太熟悉,有不少地方是还没怎么弄懂的,要好好再看看。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

