Apache Flink fault tolerance源码剖析完结篇
这篇文章是对Flink fault tolerance 的一个总结。虽然还有些细节没有涉及到,但是基本的实现要点在这个系列中都已提及。
回顾这个系列,每篇文章都至少涉及一个知识点。我们来挨个总结一下。
恢复机制实现
Flink中通常需要进行状态恢复的对象是 operator 以及 function 。它们通过不同的方式来达到状态快照以及状态恢复的能力。其中 function 通过实现 Checkpointed 的接口,而 operator 通过实现 StreamOpeator 接口。这两个接口的行为是类似的。
当然对于数据源组件而言( SourceFunction ),要想使得Flink具备完整的失败恢复能力,需要外部数据提供者具备重新消费数据的能力( Apache Kafka 提供的 message offset 机制具备这样的能力,Flink的 kafka-connector 也利用了这一点来实现数据源的失败恢复,具体的实现见 FlinkKafkaConsumerBase )。
检查点触发机制
检查点根据状态的不同,分为:
- PendingCheckpoint:正在处理的检查点
- CompletedCheckpoint:完成了的检查点
PendingCheckpoint 表示一个检查点已经被创建,但还没有得到所有该应答的 task 的应答。一旦所有的 task 都给予应答,那么它将会被转化为一个 CompletedCheckpoint 。
检查点的触发机制是基于时间的周期性触发。触发检查点的驱动者是 JobManager ,而检查点的执行者则是 TaskManager 。
检查点的触发需要满足很多条件,比如需要所有的 task 都具备触发检查点的条件等等,检查点才能被触发执行,如果检查点定时任务在执行时遇到上一次正在执行的任务还没有完成,那么当前定时任务将先“入队”,等待上一次任务完成。
基于Akka消息驱动的协调机制
Flink运行时的控制中心是 JobManager ,检查点的触发由 JobManager 发起,真正的检查点的执行者为 TaskManager 。Flink的 JobManager 以及 TaskManager 之间利用Akka进行消息通信。因此,检查点的协调机制也基于Akka之上(通过消息来驱动),Flink定义了多个不同的消息对象来驱动检查点执行,比如 DeclineCheckpoint , TriggerCheckpoint , AcknowledgeCheckpoint 等。
基于Zookeeper的高可用
Flink提供了两种恢复模式 RecoverMode :
- STANDALONE
- ZOOKEEPER
STANDALONE 表示不对 JobManager 的失败进行恢复。而 ZOOKEEPER 表示 JobManager 将基于Zookeeper实现HA(高可用)。
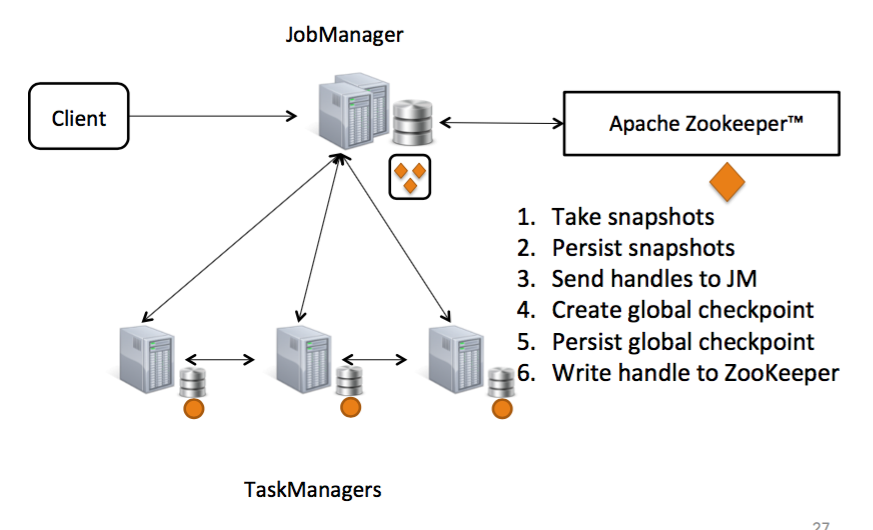
作为Flink高可用的实现机制,Zookeeper被用来生成 原子的 & 单调递增 的检查点ID,并存储已完成的检查点。
而检查点ID生成器以及已完成的检查点的存储合起来被称之为 检查点恢复服务 。
保存点
所谓的 保存点 ,其实是用户人为触发的一种特殊的 检查点 。其本质就是检查点,但它相比检查点有两点不同:
- 用户自行触发
- 当有新的已完成的检查点产生的时候,不会自动失效
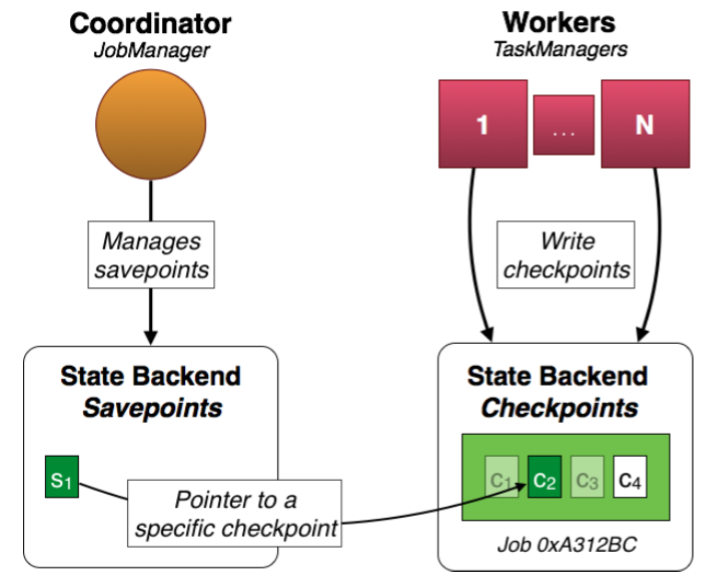
保存点是用户人为触发的,如何触发呢?这依赖于Flink提供的 client ,用户可以通过 client (CLI)来触发一个保存点。用户执行触发保存点操作后, client 会通过 akka 给 JobManager 发一个消息, JobManager 接着通知各 TaskManager 触发 检查点 。检查点触发完成后, TaskManager 会执行 JobManager 的回调,在回调中 JobManager 会告知触发保存点的结果(也是通过 akka 给客户端发消息)。保存点它不会随着新的已完成的检查点产生而自动失效。另外,不同于检查点的是,保存点并不像检查点一样将状态作为自己的一部分一并保存。保存点不存储状态,它只通过一个指针指向具体的检查点所属的状态。
保存点的存储。Flink支持两种形式的保存点的存储: memory 和 filesystem 。推荐在生产环境下使用 filesystem (可以利用hdfs等提供持久化保证)。因为基于 memory 的保存点存储机制是将保存点存储在 JobManager 的内存中。一旦 JobManager 宕机,那么保存点的信息将没有办法被恢复。
状态终端
在Flink中被直接支持的最终状态有:
- ValueState : 单值状态
- ListState : 集合状态
- FoldingState :
folding状态,forFoldFunction - ReducingState :
reducing状态,forReduceFunction
但最终结合检查点机制进行存储和恢复的状态表示是 KvState ,它表示通用的用户定义的键值对状态,可以简单得将其看做上面被最终支持的状态的容器。而 KvStateSnapshot 表示状态 KvState 的快照,用于对状态进行恢复。 StateHandle 给 operator 提供操作状态的接口,将状态从面向存储介质的原始表示还原为对象表示。
状态终端用来对状态进行持久化存储,Flink支持多个状态终端:
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend(第三方开发者实现)
基于Barrier机制的一致性保证
Flink提供两种不同的一致性保证:
- EXACTLY_ONCE:恰巧一次
- AT_LEAST_ONCE:至少一次
其中 EXACTLY_ONCE 支持对数据处理精确度要求较高的使用场景,但有时会产生明显的时延。而 AT_LEAST_ONCE 应对于需要低延时,但对数据的准确性要求并不高的场景。
需要注意的是这里的一致性保证并不是指被处理的 元素 流过 Stream Dataflow 的保证,而是指 operator 在最后一次改变状态之后,后续的数据对状态的改变产生的最终影响(结合检查点)。
一致性保证离不开Flink的 checkpoint barrier 。
单个数据流视角, barrier 示意:
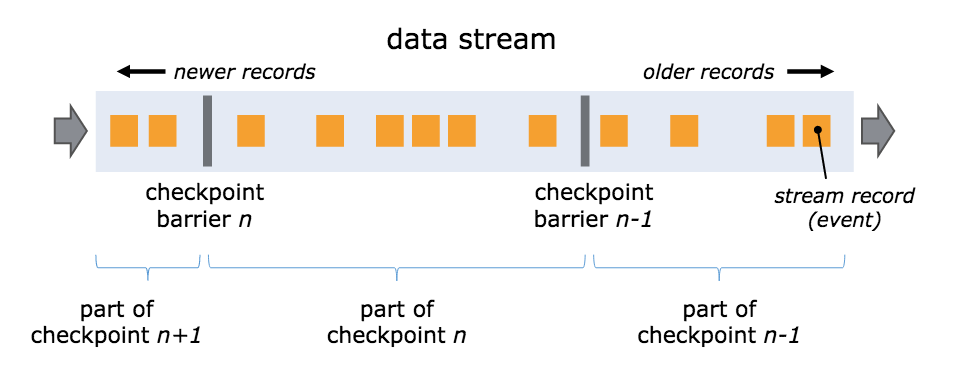
分布式多 input channel 视角, barrier 示意图:

该图演示的是多barrier aligning(对齐),但只有 EXACTLY_ONCE 一致性时才会要求这一点
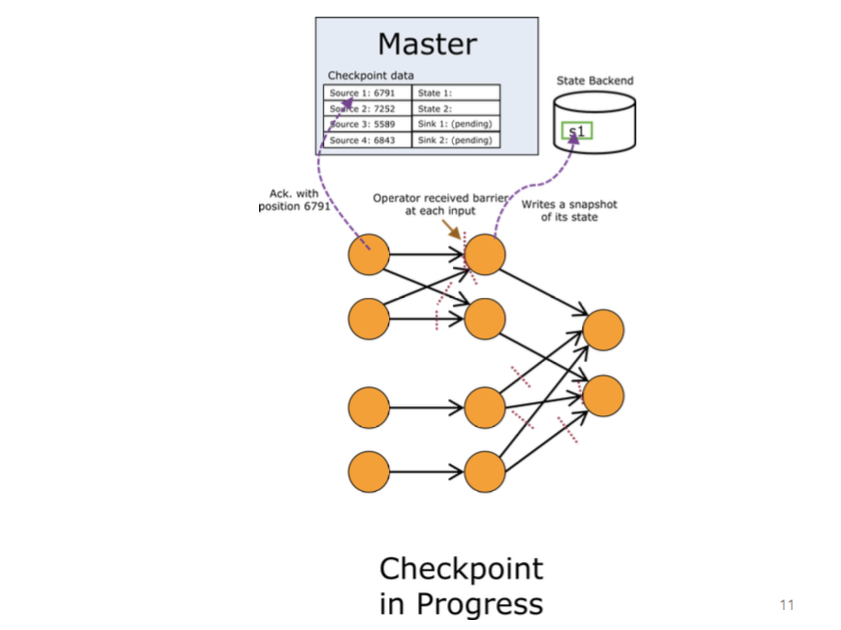
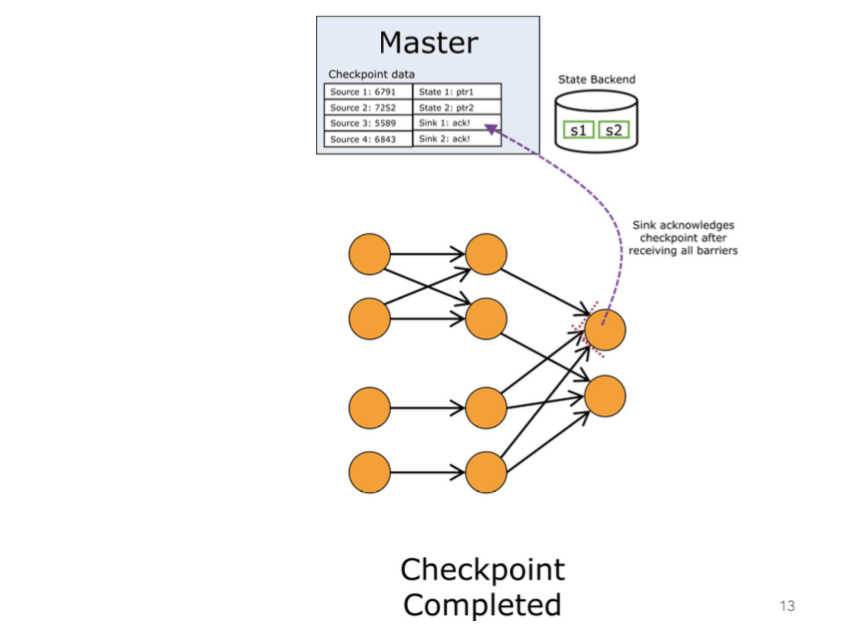
JobManager 将指示 source 发射 barriers 。当某个 operator 从其输入中接收到一个 CheckpointBarrier ,它将会意识到当前正处于前一个检查点和后一个检查点之间。一旦某 operator 从它的所有 input channel 中接收到 checkpoint barrier 。那么它将意识到该检查点已经完成了。它可以触发 operator 特殊的检查点行为并将该 barrier 广播给下游的 operator 。
应对两种不同的一致性保证,Flink提供了两个不同的 CheckpointBarrierHandler 的实现,它们的对应关系是:
- BarrierBuffer - EXACTLY_ONCE
- BarrierTracker - AT_LEAST_ONCE
BarrierBuffer 通过阻塞已接收到 barrier 的 input channel 并缓存被阻塞的 channel 中后续流入的数据流,直到所有的 barrier 都接收到或者不满足特定的检查点的条件后,才会释放这些被阻塞的 channel ,这个机制被称之为——aligning(对齐)。正是这种机制来实现 EXACTLY_ONCE 的一致性(它将检查点中的数据精准得隔离开)。
而 BarrierTrack 的实现就要简单地多,它仅仅是对数据流中的 barrier 进行跟踪,但是数据流中的元素 buffer 是直接放行的。这种情况会导致同一个检查点中可能会预先混入后续检查点的元素,从而只能提供 AT_LEAST_ONCE 的一致性。
完整的检查点流程示例
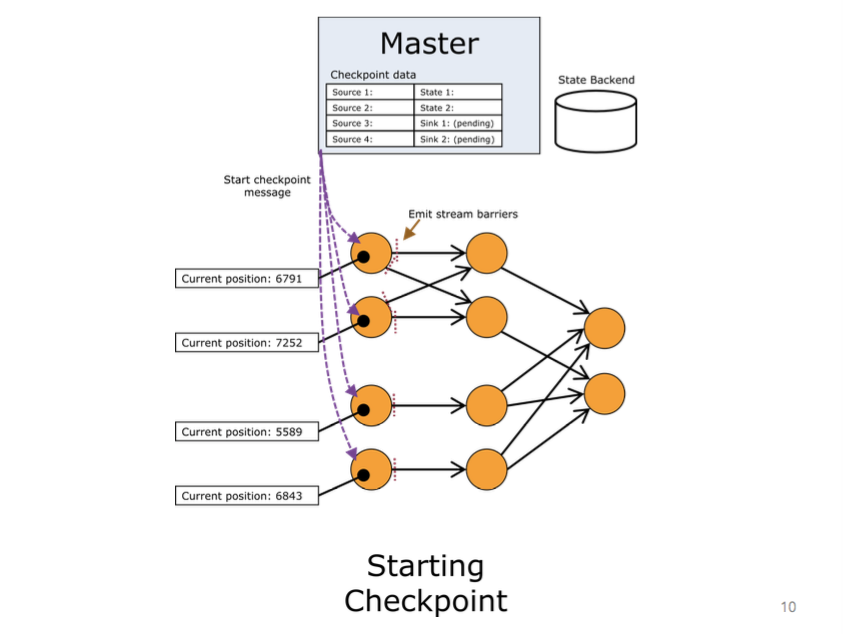

小结
本文是Flink fault tolerance 系列的完结篇,对关键概念和流程进行了总结和梳理。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

