Tornado源码剖析
pdb调试
简单的介绍一下pdb的调试, 更详细的命令查看 python pdbf官方文档
importpdb // 使用以下语句希望debug的地方打断点 pdb.set_trace()
| 命令 | 说明 |
|---|---|
| n | 运行下一行代码 |
| p | 计算p后面的表达式(当前上下文中), 并打印表达式的值 |
| s | 进入函数 |
| r | 从函数中返回 |
| b | 动态设置断点 |
| w | 打印当前栈信息 |
| q | 退出pdb |
Tornado剖析
Tornado is a Python web framework and asynchronous networking library, originally developed at FriendFeed. By using non-blocking network I/O , Tornado can scale to tens of thousands of open connections, making it ideal for long polling, WebSockets, and other applications that require a long-lived connection to each user.
源码剖析基于Tornado 2.0.0及以下测试源码
#!/usr/bin/env python # -*- coding: utf-8 -*- importtornado.web importtornado.httpserver importtornado.ioloop importtornado.options importos.path fromtornado.optionsimportdefine, options define("port", default=8000, help="run on the given port", type=int) # 继承Application classApplication(tornado.web.Application): def__init__(self): handlers = [ (r"/", MainHandler), ] settings = dict( template_path=os.path.join(os.path.dirname(__file__), "templates"), static_path=os.path.join(os.path.dirname(__file__), "static"), debug=True, ) tornado.web.Application.__init__(self, handlers, **settings) # URI Hanlder逻辑 classMainHandler(tornado.web.RequestHandler): defget(self): importpdb pdb.set_trace() self.write("Hello, World") defrun(): tornado.options.parse_command_line() http_server = tornado.httpserver.HTTPServer(Application()) http_server.listen(options.port) print"Start server, http://localhost:%s"% options.port tornado.ioloop.IOLoop.instance().start() if__name__ =="__main__": run() 首先运行一上源码(服务器端), 另外开启一个 Terminal 来发出请求(也可以使用浏览器来访问). 服务端收到请求后, 会在我们 pdb.set_trace() 停下等待调试.
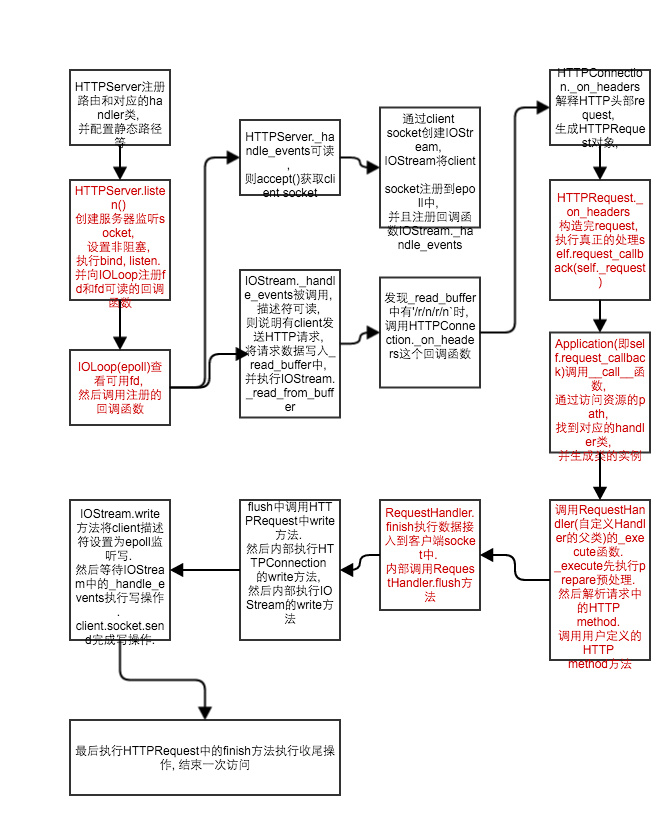
//新的Terminal命令行执行以下命令 $ curl http://localhost:8000 // 此时服务器端会进入`pdb`调试状态. 输入w以获得当前调用栈信息如下: (Pdb) w /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/bin/run(13)<module>() -> sys.exit(learn.learn_source.run()) /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/learn/learn_source.py(41)run() -> tornado.ioloop.IOLoop.instance().start() /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/.buildout/eggs/tornado-2.0-py2.7.egg/tornado/ioloop.py(233)start() -> self._run_callback(callback) /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/.buildout/eggs/tornado-2.0-py2.7.egg/tornado/ioloop.py(370)_run_callback() -> callback() /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/.buildout/eggs/tornado-2.0-py2.7.egg/tornado/stack_context.py(159)wrapped() -> callback(*args, **kwargs) /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/.buildout/eggs/tornado-2.0-py2.7.egg/tornado/iostream.py(235)wrapper() -> callback(*args) /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/.buildout/eggs/tornado-2.0-py2.7.egg/tornado/stack_context.py(159)wrapped() -> callback(*args, **kwargs) /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/.buildout/eggs/tornado-2.0-py2.7.egg/tornado/httpserver.py(400)_on_headers() -> self.request_callback(self._request) /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/.buildout/eggs/tornado-2.0-py2.7.egg/tornado/web.py(1282)__call__() -> handler._execute(transforms, *args, **kwargs) /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/.buildout/eggs/tornado-2.0-py2.7.egg/tornado/web.py(927)_execute() -> getattr(self, self.request.method.lower())(*args, **kwargs) > /Users/andrew_liu/Development/BackEnd/Python3/TornadoToturial/src/learn/learn_source.py(33)get() -> self.write("Hello, World") 一. 首先 Application 调用 __init__ , 通过 self.add_handlers(".*$", handlers) 配置路由, 配置静态资源资源路径.
二. tornado.httpserver.HTTPServer 接收一个 Application 参数并命名为 request_callback , 注意此处Application实例被命名为request_callback 留意 HTTPServer 中有一个属性 self._sockets 保存 fd 到 socket object 的映射.
三. 调用 HTTPServer 的 listen(options.port) 方法开始做socket监听. listen中做了两件事. 一: bind创建socket对象设置并设置非阻塞, 并进行 socket.bind() 和 socket.listen() 监听. 并在 self._sockets 保存socket描述符和socket对象的映射. 二: start 函数初始化一个 IOLoop 对象(单例对象), 并遍历 self._sockets socket描述符, 将其添加到 IOLoop 并绑定读事件
为了方便查看, 本来去掉源码中的异常捕获和一些干扰阅读的细节
# 步骤三中的核心代码 # 步骤三第一部分 classHTTPServer(object): defbind(self, port, address=None, family=socket.AF_UNSPEC) # 网编编程的一套, socket => bind => listen sock = socket.socket(af, socktype, proto) sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR,1) sock.setblocking(0) sock.bind(sockaddr) sock.listen(128) self._sockets[sock.fileno()] = sock # 步骤三第二部分 defstart(self, num_processes=1) ifnotself.io_loop: self.io_loop = ioloop.IOLoop.instance()# 返回一个全局的IOLoop对象 forfdinself._sockets.keys():# 对整个fd和socket对象的映射集合, 都加入到epoll, 并注册回调 self.io_loop.add_handler(fd,self._handle_events, ioloop.IOLoop.READ)# 给每个fd绑定读事件, self._handle_events为回调事件(当fd可读的时候, 则调用此函数)
四. tornado.ioloop.IOLoop.instance().start() 中通过步骤三中全局的IOLoop对象执行 start . 此处核心代码为 event_pairs = self._impl.poll(0.2) . 其中 self._impl 根据不同平台来选择 select/poll/epoll/kqueue , 每当有事件可读时, 则执行其回调函数 self._handle_events . 整个回调函数为HTTPServer中的handler_events函数
# 步骤四start中的核心代码 classIOLoop(object): defstart(self) whileTrue: event_pairs = self._impl.poll(poll_timeout)# epoll对触发读事件的描述符返回, 此处说明有客户端访问服务器 self._events.update(event_pairs)# 将要处理的事件更新到self._events这个dict中 whileself._events: fd, events = self._events.popitem()# 随机取出一个事件(key-value) self._handlers[fd](fd, events)# self._handlers是在第三步中add_handler中添加的, self._handlers是fd描述符和self._handle_events形成的映射(dcit). 此处从self._handlers中取出fd描述符对应的self._handle_events执行.
五. 最后我们发现, 让了一圈又回到 HTTPServer._handle_events 函数上. 函数中创建了IOStream对象和HTTPConnection对象.
# 步骤五的核心代码 # 当我们访问http://localhost:8000, epoll返回事件 classHTTPServer(object): def_handle_events(fd, event): whileTrue: connection, address = self._sockets[fd].accept() # 此处connection为客户端连接 stream = iostream.IOStream(connection, io_loop=self.io_loop) HTTPConnection(stream, address, self.request_callback, self.no_keep_alive, self.xheaders)
其中 iostream.IOstream 回通过client socket( connection )来初始化, 并且完成将fd注册到 IOLoop的epoll 中. 当fd可读时, 会调用 IOStream._handle_events 函数做回调, 描述符可读, 即客户端发送了HTTP, 读取客户端发送的数据写入IOStream中的 self._read_buffer 读缓冲区中.
classIOStream(object): def__init__(self, socket, io_loop=None, max_buffer_size=104857600, read_chunk_size=4096): self.socket = socket self.socket.setblocking(False) self.io_loop = io_loop orioloop.IOLoop.instance() self.max_buffer_size = max_buffer_size self.read_chunk_size = read_chunk_size self._state = self.io_loop.ERROR withstack_context.NullContext(): self.io_loop.add_handler( self.socket.fileno(), self._handle_events, self._state) # 将client socket注册到io_loop中, 并绑定回调事件self.handle_events(IOStream) def_handle_events(self, fd, events): ifevents & self.io_loop.READ:# 当客户端有链接时, 则event可读 self._handle_read() def_handle_read(self): whileTrue: result = self._read_to_buffer() # 将数据接入读缓冲区self._read_buffer中
然后通过iostream来初始化 HTTPConnection , 注意HTTPConnection中的 self.request_callback 属性就是在HTTPServer初始化时的 Application . 其中执行 self.stream.read_until 并读取缓冲区的数据, 然后回调 HTTPConnection._on_headers 解析HTTP请求的头部, 然后 出现了最重要的一步!!! , self.request_callback(self._request) , 终于出现了, 这是最吼的! self.request_callback 就是我们用来初始化 HTTPServer 的 Application 对象呀!!! 这货有个黑魔法函数 __call__ , 可以直接对Application对象进行传参调用!!! 传入客户端的request请求到Application中.
# 这个类执行真正的客户端请求处理 classHTTPConnection(object): """Handles a connection to an HTTP client, executing HTTP requests. """ def__init__(self, stream, address, request_callback, no_keep_alive=False, xheaders=False): self.stream = stream # IOStream包含数据缓冲区 self.address = address self.request_callback = request_callback # Application类 self.no_keep_alive = no_keep_alive self.xheaders = xheaders self._request = None self._header_callback = stack_context.wrap(self._on_headers) self.stream.read_until(b("/r/n/r/n"), self._header_callback)# 通过指定分隔符从self.stream中读取数据, 然后回调self._header_callback, 即self._on_headers def_on_headers(self, data): self._request = HTTPRequest(connection=self, method=method, uri=uri, version=version,headers=headers, remote_ip=self.address[0])# 对请求的头部进行解析, 然后生成HTTPRequest对象, 注意此处的connection(HTTPConnection), 向客户端发送数据会用到 self.request_callback(self._request) # 最后终于出现self.request_callback了!!! 这就是Application呀!! 执行他的黑魔法__call__方法 六. 重新看栈信息 self.request_callback(self._request) web.py(1282)__call__() 完全符合我们的分析. __call__ 接收 self._request , 其中通过 _request 中host信息作路径匹配, 如果路径相匹配则返回我们创建的 Handler类
classApplication(object): def__call__(self, request): handlers = self._get_host_handlers(request) # 获取与host匹配的handler forspecinhandlers: match = spec.regex.match(request.path) ifmatch: handler = spec.handler_class(self, request, **spec.kwargs) # 找到最初我们注册的MainHandler并创建实例. handler._execute(transforms, *args, **kwargs) def_get_host_handlers(self, request): host = request.host.lower().split(':')[0] forpattern, handlersinself.handlers: ifpattern.match(host): returnhandlers 我们再次查看栈信息, 发现此时的handler即为 MainHandler , 并执行对象的 _execute 方法
->handler._execute(transforms, *args, **kwargs) (Pdb) l 1277ifgetattr(RequestHandler,"_templates",None): 1278forloaderinRequestHandler._templates.values(): 1279loader.reset() 1280RequestHandler._static_hashes = {} 1281 1282 -> handler._execute(transforms, *args, **kwargs) 1283returnhandler 1284 1285defreverse_url(self, name, *args): 1286"""Returns a URL path for handler named `name` 1287 (Pdb) print handler <learn.learn_source.MainHandler object at 0x1054c7210> 七. handler._execute 找到 request 中的HTTP方法, 然后执行对应的函数. 我们在MainHandler中实现了get方法, 此处会调用对应的方法. 并将数据发送给客户端.
classRequestHandler(object): def_execute(self, transforms, *args, **kwargs): self.prepare() # 次数调用了prepre方法 ifnotself._finished: args = [self.decode_argument(arg) forarginargs] kwargs = dict((k, self.decode_argument(v, name=k)) for(k,v)inkwargs.iteritems()) getattr(self, self.request.method.lower())(*args, **kwargs) # 获取对应的get/post等方法的具体实现并执行. ifself._auto_finishandnotself._finished: self.finish() # 数据的返回由finish完成 deffinish(self, chunk=None): # 中间执行一些构造响应头部的操作 ifnotself.application._wsgi: self.flush(include_footers=True)# 数据刷新操作. self.request.finish() # 移除客户端的相关操作 self._log() self._finished = True defflush(self, include_footers=False): # Ignore the chunk and only write the headers for HEAD requests ifself.request.method =="HEAD": ifheaders: self.request.write(headers) return ifheadersorchunk: self.request.write(headers + chunk) # write执行写入操作 classHTTPRequest(object): defwrite(self, chunk): """Writes the given chunk to the response stream.""" assertisinstance(chunk, bytes_type) self.connection.write(chunk) # 此处connection是一个HTTPConnection classHTTPConnection(object): defwrite(self, chunk): """Writes a chunk of output to the stream.""" assertself._request,"Request closed" ifnotself.stream.closed(): self.stream.write(chunk, self._on_write_complete) # 实现写入操作有IOStream完成. # IOStream是对客户端socket的封装 classIOStream(object): defwrite(self, data, callback=None): """Write the given data to this stream. """ assertisinstance(data, bytes_type) self._check_closed() self._write_buffer.append(data) self._add_io_state(self.io_loop.WRITE) # 这里改变为WRITE, 则执行写操作 self._write_callback = stack_context.wrap(callback) def_handle_events(self, fd, events): ifevents & self.io_loop.WRITE: ifself._connecting: self._handle_connect() self._handle_write() def_handle_write(self): whileself._write_buffer: num_bytes = self.socket.send(self._write_buffer[0])# 终于完成了数据发送
八. 完成数据写入client socket后, HTTPRequest.finish() 被调用执行移除时间和关闭客户端socket操作. 是不是已经晕了, 稍等我们来画个图来理一理整个流程.
参考链接
- Tornado: 1. 流程分析
- Tornado 源码分析 - 基础篇
- Tornado核心框架
- Tornado 源码阅读
- Python 代码调试技巧
- 为什么 IO 多路复用要搭配非阻塞 IO?
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

