python3中的正则模块
与正则最相关的应该算是字符串, 但是,在内置的py的str类型中, 并没有内置的正则方法. 我们可以看一下str的基本方法:
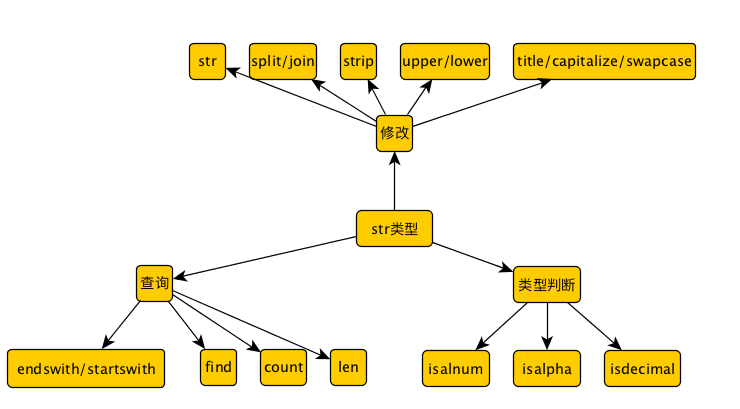
我觉得最有用的,应该算find,len,split,join 这4个方法了. 但对于字符串操作来说, 这简直too too simple. 所以, py提供了我们一个Re 模块, 来帮助我们使用正则对字符串进行相关操作. 另外, py中的正则是perl-like 所以, 支持的正则的特性比js多很多.
使用Re
首先, 我们需要导入正则模块.
<spanclass="hljs-reserved">import</span> re
我们可以使用 dir(re) 来查看里面主要有哪些方法. 或者你可以直接查阅 python官网 . 这样, 我们就可以使用相关的正则方法了.
在正式使用方法之前, 我们得学习一下, 如果在py中写正则. 因为py不同于其他语言使用 // (slashes) 作为正则标识符, py使用 r 作为正则表达式的flag.
<spanclass="hljs-comment"># js中</span> //d+/ <spanclass="hljs-comment"># py中</span> <spanclass="hljs-string">r"/d+"</span>
接下来, 我们会边介绍re模块的同时, 简单说明一下,python的正则语法.
match
match 用来找到string中被pattern 匹配的部分.基本的syntax:
re.match(pattern, string, flags=0)
- pattern: 正则表达式
- string: 被匹配的字符串
- flags: 用来表示正则匹配的模式, 比如忽略大小写, 全局匹配等
match 返回的是 re 自定义的match object. 当然, 如果没有匹配到的话, 则会返回None. 我们看个demo:
reg = re.match(<spanclass="hljs-string">r"/w"</span>, <spanclass="hljs-string">"wa"</span>); <spanclass="hljs-comment"># 加上flag: re.I -> 忽略大小写</span> reg = re.match(<spanclass="hljs-string">r"/w"</span>, <spanclass="hljs-string">"wa"</span>,re.I);
如果匹配到了, 我们该怎么从里面获得我们想要的呢?很简单: match object 上面自带了两个方法: group和groups
- group(num=0): 用来返回匹配到的内容,
0返回的是全部匹配到的内容. 从1开始是返回通过(...)匹配到的内容 - groups() : 返回所有通过
(...)匹配到的子内容, 并且放在tuple 当中.
reg = re.match(<spanclass="hljs-string">r"/w"</span>, <spanclass="hljs-string">"w1a"</span>,re.I); print(reg.group(<spanclass="hljs-number">0</span>)) <spanclass="hljs-comment"># 返回 w</span> reg = re.match(<spanclass="hljs-string">r"/b/w*/b(/s/b/w*/b)"</span>, <spanclass="hljs-string">"Cats are smarter than dogs"</span>); print(reg.group(<spanclass="hljs-number">0</span>)) <spanclass="hljs-comment"># Cats are</span> print(reg.group(<spanclass="hljs-number">1</span>)) <spanclass="hljs-comment"># are</span> print(reg.groups()) <spanclass="hljs-comment"># (' are',)</span> 还有一个常用的方法是search. 目前并不知道, 他和match的区别在哪里.
search
search 方法用来查找第一个正则匹配到的str内容. 同样,如果匹配到,他也会返回match Object. 如果没有匹配到, 则会返回None. 所以, 他的match上的方法和上面是一样的
不过, 实际上两者还是有区别的。 根据官方的介绍, match 只能从string的开头部分开始匹配, 而search则可以从任何一个位置开始匹配. 相当于:
- match 默认就是
r"^xxxx"酱汁. - search则和javascript中的
//w+/g全局匹配类似.
具体看一个demo吧:
search = re.search(<spanclass="hljs-string">r"123"</span>, <spanclass="hljs-string">"aresmarter12323handogs"</span>); match = re.match(<spanclass="hljs-string">r"123"</span>, <spanclass="hljs-string">"aresmarter12323handogs"</span>) print(search.group()) <spanclass="hljs-comment"># Cats are</span> print(match.group()) <spanclass="hljs-comment"># AttributeError</span>
使用match来说, 这一点就比较尴尬了.
sub
该方法是将匹配到的str 部分使用 指定字符串替代. 实际上, 和python的replace方法一样. 只是他是使用正则进行匹配的:syntax:
re.sub(pattern, repl, string, max=0)
- pattern: 正则表达式
- repl: 就是replace 用来替代的字符串
- string: 目标字符串
- max: 替换次数.为0 则默认不替换, 为1则表示替换一处
看示例吧, 清楚一点
reg = re.sub(<spanclass="hljs-string">r"/d+"</span>,<spanclass="hljs-string">""</span>, <spanclass="hljs-string">"remove digital from xxx123xxx123xx"</span>); print(reg) <spanclass="hljs-comment"># remove digital from xxxxxxxx</span> reg = re.sub(<spanclass="hljs-string">r"/d+"</span>,<spanclass="hljs-string">""</span>, <spanclass="hljs-string">"remove digital from xxx123xxx123xx"</span>,<spanclass="hljs-number">1</span>); print(reg) <spanclass="hljs-comment"># remove digital from xxxxxx123xx</span>
compile
这是python提供的一个parse regexp 的方法函数. 实际上, 是为了更好的复用正则. 比如, 我有一处正则, 但是,我想多次用的话, 在没有compile的情况下, 就只能copy了. 这实际上和javascript中的 RegExp 对象是一个道理. 并且, 该方法上挂载了,所有依赖正则的方法, 也就是说, 需要输入pattern的地方,都可以直接使用dot来调用.基本格式为:
re.compile(pattern, flags=0)
看个demo吧:
getDigital = re.compile(<spanclass="hljs-string">r'/d+'</span>,re.I) a_str = <spanclass="hljs-string">'remove digital from xxxxxx123xx'</span> removeDigital = getDigital.sub(<spanclass="hljs-string">''</span>,a_str) print(removeDigital) <spanclass="hljs-comment"># remove digital from xxxxxxxx</span>
看情况用吧
findall
从上面的match和search开始,我就觉得很有必要吧findall 提出来, 因为, 该方法比match和search来说更常见. 按照使用频率我们可以排序:
- findall > search > match
findall的作用就是, 全局匹配.格式为:
re.findall(pattern, string, flags=0)
他返回的内容并不是match object, 而是一个list, 用来表示在整个string中, 被pattern 匹配到的内容.
(和match差不了多少)
看一下demo:
get_digital = re.findall(<spanclass="hljs-string">r'/d+'</span>,<spanclass="hljs-string">"123 I am a space 13123"</span>) print(get_digital) <spanclass="hljs-comment"># ['123', '13123']</span>
fullmatch
fullmatch 用来表示正则和string是完全匹配的关系. 相当于从头到尾, 如果匹配到, 这返回相关内容, 否则返回None. fullmatch 相当于 r"/A your regular expression /Z" . (你也可以使用 ^ 替代 /A , $ 替代 /Z )
格式为:
fullmatch(pattern, string, flags=0)
看个demo:
get_digital = re.fullmatch(<spanclass="hljs-string">r'/d{3,11}'</span>,<spanclass="hljs-string">"331213322"</span>) same_effect = re.match(<spanclass="hljs-string">r'^/d{3,11}$'</span>,<spanclass="hljs-string">"331213322"</span>) print(get_digital.group()) <spanclass="hljs-comment"># 使用fullmatch</span> print(same_effect.group()) <spanclass="hljs-comment"># 使用/A /Z 进行匹配</span> split
和str中的split方法比起来, 他的作用就是多出一个正则匹配. 返回的是list.格式为:
split(pattern, string, maxsplit=0, flags=0)
看个demo吧:
split_str = re.split(<spanclass="hljs-string">r'/d'</span>,<spanclass="hljs-string">'this is 1 this is 2'</span>) print(split_str) <spanclass="hljs-comment"># ['this is ', ' this is ', '']</span>
最后再介绍一个escape 方法. 常常用在处理恶意字符当中.
escape
用来过滤其他字符, 只会保留ASCII和数字(在v3.3版本之前 支持 _ , 不过现在不支持了). 他的返回值就是一个新的str.
格式为:
escape(string)
看个demo:
esc = re.escape('I"m a evil <span class="hljs-tag"><<span class="hljs-title">script</span>></span><span class="javascript"> <span class="hljs-built_in">window</span>.location.href=<span class="hljs-string">"villainhr.com"</span></span><span class="hljs-tag"></<span class="hljs-title">script</span>></span>') print(esc) # 最后得到的内容全部使用/ 进行转义. # I/"m/ a/ evil/ /<span class="hljs-tag"><<span class="hljs-title">script/</span>></span>/ window/.location/.href/=/"villainhr/.com/"/<span class="hljs-tag"><<span class="hljs-title">/</span>/<span class="hljs-attribute">script</span>/></span> 介绍完了基本的方法, 我们来深入的看看, match object上面到底存在些什么方法和属性.
Match Object
match object是 match 和 search 返回的结果. 上文介绍了, MO(match object) 中存在的两个基本方法, group() 以及 groups(). 参考官方文档, 我们可以了解到, MO还存在其他一些很有用的方法。
- start([group]): 找到某个group 在str中开始的位置. 返回的是Number。
reg = re.match(<spanclass="hljs-string">r"/w+/d+(/w+)"</span>, <spanclass="hljs-string">"first1232second"</span>); print(reg.group(<spanclass="hljs-number">1</span>),<spanclass="hljs-string">'start from'</span>,reg.start(<spanclass="hljs-number">1</span>)) <spanclass="hljs-comment"># second start from 9</span>
- end([group]): 和start 一样, 返回某个group的结束位置.
reg = re.match(<spanclass="hljs-string">r"/w+/d+(/w+)"</span>, <spanclass="hljs-string">"first1232second"</span>); print(reg.group(<spanclass="hljs-number">1</span>),<spanclass="hljs-string">'end up with'</span>,reg.end(<spanclass="hljs-number">1</span>)) <spanclass="hljs-comment"># second end up with 15</span>
官方提供了几种使用start和end快速获取匹配内容的办法.
-
- 匹配第二个分组之前的内容:(记住,第二个分组就是index为2,index为1是所有匹配到的内容)
exa = <spanclass="hljs-string">"first1232second third"</span> reg = re.search(<spanclass="hljs-string">r"/d+(/w+)/s(/w+)"</span>, exa); print(exa[:reg.start(<spanclass="hljs-number">2</span>)]) <spanclass="hljs-comment"># first1232second </span>
-
- 匹配第二个分组到第一个分组之间的内容:
exa = <spanclass="hljs-string">"first1232second , third"</span> reg = re.search(<spanclass="hljs-string">r"/d+(/w+)/s[/'',.]/s(/w+)"</span>, exa); print(exa[reg.end(<spanclass="hljs-number">1</span>):reg.start(<spanclass="hljs-number">2</span>)]) <spanclass="hljs-comment"># , </span>
其他的, 到具体业务场景再说吧.
- span([group]): 返回指定group 在原来str中占的范围.
reg = re.match(<spanclass="hljs-string">r"/w+/d+(/w+)"</span>, <spanclass="hljs-string">"first1232second"</span>); print(reg.group(<spanclass="hljs-number">1</span>),<spanclass="hljs-string">'its span is'</span>,reg.span(<spanclass="hljs-number">1</span>)) <spanclass="hljs-comment"># 返回</span> <spanclass="hljs-comment"># second its span is (9, 15)</span>
- lastindex: 返回最后一个分组的index. 如果没有匹配到分组, 则返回None. lastindex 实际上可以用来表示匹配到分组的长度(记得 +1 就行了)
reg = re.search(<spanclass="hljs-string">r"/d+(/w+)"</span>, <spanclass="hljs-string">"first1232second"</span>); print(reg.lastindex) <spanclass="hljs-comment"># 返回 1</span>
- lastgroup: 返回最后一个分组的命名. 这估计就要牵扯到,正则的命名了. 我们来看一个简单的demo:
exa = <spanclass="hljs-string">"first1232second , third third"</span> reg = re.search(<spanclass="hljs-string">r"/d+(?P<name>/w+)/s[/'',.]/s(?P<sam>/w+)/s"</span>, exa); print(reg.lastgroup) <spanclass="hljs-comment"># sam</span>
在python中, 我们可以使用(?P< xxx>)的格式进行命名. 实际上, lastgroup用到的并不多, 可以说非常少.基本上, 关于re的方法,以及MO的方法和属性都已经介绍完毕了.
接下来我们补充一下,关于flags 和 分组的使用(结合group)
regexp supplement
分组的作用
上文说到了分组表示, 但是还没有深入说一下, 相关分组到底有什么x用. 使用分组简单的说来有两个好处,一个是sub方法, 一个是group 方法.
这里, 我们先说一下 group方法吧.
我们可以使用 /number 这样的默认分组,也可以使用 直接定义命名 (?P<xxx>) 。 如果使用前者, 那么我们的group方法, 可以说根本发挥不了什么效果.
Old style:
exa = <spanclass="hljs-string">"first1232second , third"</span> reg = re.search(<spanclass="hljs-string">r"/d+(/w+)"</span>, exa); print(reg.group(<spanclass="hljs-number">1</span>))
由于分组是从1开始, 所以,我们这里也就理解了, 为什么group(0) 不算分组而算全部匹配的内容.
我们使用命名的方式,使用group来获取一下.
New style:
exa = <spanclass="hljs-string">"my id is 12334213"</span> reg = re.search(<spanclass="hljs-string">r"(?P<id>/d+)"</span>, exa); print(reg.group(<spanclass="hljs-string">'id'</span>))
如果使用这样的方式来的话, 语义清晰, 方便快捷. 五星推荐.
分组还有另外一个好处,就是使用sub方法, 能够快速实现HTML替换.直接看demo吧:
exa = <spanclass="hljs-string">'<text top="33" font="0"><b>test</b></text>'</span> new_text = re.sub(<spanclass="hljs-string">r"<b>(.*?)</b>"</span>, <spanclass="hljs-string">r'/1'</span>,exa); print(new_text)
当然, 你也可以直接使用命名的方法:
exa = <spanclass="hljs-string">'<text top="33" font="0"><b>test</b></text>'</span> new_text = re.sub(<spanclass="hljs-string">r"<b>(?P<innerHTML>.*?)</b>"</span>, <spanclass="hljs-string">r'/g<innerHTML>'</span>,exa); print(new_text)
这就是分组的作用.
另外, 我们还得需要看看 re提供的几个正则flag
flag
这里就列几个比较常用的吧:
| name | effect |
|---|---|
| re.I | 忽略大小写匹配 |
| re.M | 多行匹配. 通常情况下, ^ 和 $ 会从str的开头限定到结果,如果是多行的话也是这样. 使用了re.M的flag之后, 就可以设定, 在str的每一行都使用 ^...$ 里面的内容进行匹配 |
| re.S | 该flag是正针对于 . 而设置的. 因为 . 是可以匹配任意字符,但不包括换行符. 但,如果你加上这个flag后, 那么 . 就可以匹配所有字符 |
| re.X | 相当于一种宽松型regexp. 这种方式的意图是告诉你,可以使用一种comment 的方式,来写正则,让你更宽的理解他. 并且,regexp中的空格全部无效,除非你显示使用 /s |
根据官网提供的demo,我们来解释一下re.X的作用.
a = re.compile(<spanclass="hljs-string">r"""/d + # the integral part /. # the decimal point /d * # some fractional digits"""</span>, re.X) b = re.compile(<spanclass="hljs-string">r"/d+/./d*"</span>) <spanclass="hljs-comment"># a 等价于b</span>
看demo, 我觉得就已经足够了.
关于正则的基本内容就到这里, 我们最后来看看总结吧.
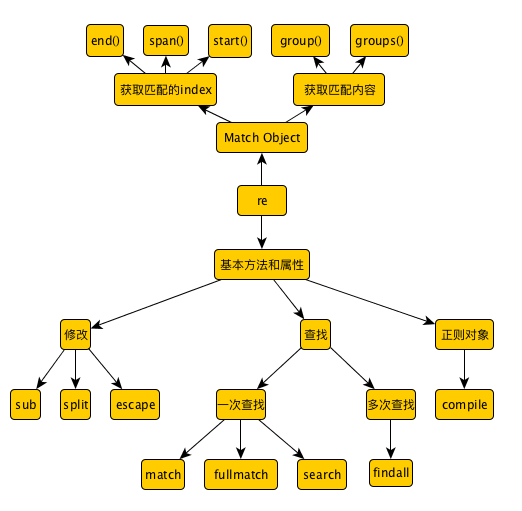
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

