Erlang/Elixir: 使用 Leex 和 Yecc 解析领域语言(DSL)
本文的目的是处理 Telegram 协议的定义语言TL
本文需要对 编译原理 有一定的了解.
Leex 是一个 Erlang 语言实现的词法分析器( Lexical Analyzer ). 接收字符流输入, 产生符号流输出.
Yecc 是一个 Erlang 语言实现的语法分析器( Syntactic Parser ). 接收符号流输入, 产生 AST .
词法分析器 leex
一个 leex 词法分析文件的包含下面三个部分:
-
符号定义
Definitions.
Definitions.这部分使用正则表达式定义字符类别. -
符号规则
Rules.
Rules.定义了如何生成符号的字符匹配规则 -
符号转换
Erlang code.
一般在这里定义一些辅助 Erlang 函数, 用于对TokenChars做进一步处理.
语法分析器 yecc
yecc 是一个 LALR-1 解析器生成器, 类似于 yacc . 接收一个 BNF 语法定义作为输入, 生成一个解析器的 Erlang 代码.
语法规则文件的构成
一个 .yrl 语法规则文件, 由四个部分组成, 分别是:
-
Nonterminals.
什么是
Nonterminals., 那些可以被展开为更小的语言符号的东西, 比如一个代码块, 函数块, 控制流程:def test do Logger.info "这是一个Nonterminals的代码块" end -
Terminals.
end,def, 以及变量等不能再被展开的符号 -
Rootsymbol.
抽象语法树的树根定义, 它指出了, 在语法规则文件.yrl中规则从哪里开始应用. -
Erlang code.(可选的)转换函数
项目实践
本文给出了一个解析Telegram 的二进制协议的代码生成示例
channel#a14dca52 flags:# creator:flags.0?true kicked:flags.1?true left:flags.2?true editor:flags.3?true moderator:flags.4?true broadcast:flags.5?true verified:flags.7?true megagroup:flags.8?true restricted:flags.9?true democracy:flags.10?true signatures:flags.11?true min:flags.12?true id:int access_hash:flags.13?long title:string username:flags.6?string photo:ChatPhoto date:int version:int restriction_reason:flags.9?string = Chat;完整的协议定义文件参考 scheme.tl
创建一个项目
这一节简单的阐述了如何设置一个项目, 通过词法规则文件 .xrl 和语法规则文件 .yrl 生成词法解析程序和语法解析程序. 首先需要创建一个项目:
mix new leex_yecc_example mkdir src 手动编译 .xrl 文件和 .yrl 文件为 Erlang模块是一件单调乏味的事情, Mix 能够自动帮助你生成词法分析器和语法分析器, 只要你把 .xrl 文件和 .yrl 文件放在项目根目录的 src (例如 leex_yecc_example/src )子目录下即可. 执行 mix compile 会自动帮你生成词法分析器和语法分析器对应的 .erl 文件.
Mix 支持编译那些文件?
iex(1)> Mix.compilers() [:yecc, :leex, :erlang, :elixir, :app]创建词法文件
lexer.xrl
Definitions. D = [0-9] NONZERODIGIT = [1-9] O = [0-7] HEX = [0-9a-fA-F] UPPER = [A-Z] LOWER = [a-z] EQ = (=) COLON = (:) SHARP = (#) WHITESPACE = [/s/t] TERMINATOR = /n|/r/n|/r COMMA = , ... ComplexType = ({LOWER}+/.{Capital}|{Capital}) VectorPrimitiveType = (V|v)(ector)(<)({PrimitiveType})(>) VectorComplexType = (V|v)(ector)(<)({ComplexType})(>) ... Rules. {COMMA} : skip_token. {WHITESPACE} : skip_token. {TERMINATOR} : skip_token. {MtpName}#{MtpId} : {token, {mtp_name, TokenLine, split_msg_type(TokenChars)}}. (flags:#) : {token, {flags_sharp_token,TokenLine, TokenChars}}. ...创建语法文件
parser.yrl
Nonterminals grammer field_items field_item . Terminals mtp_name mtp_id mtp_sharp flags_sharp_token field_name ... eq_token . Rootsymbol grammer. grammer -> mtp_name field_items eq_token return_type_vector_primitive: ['$1', '$2', '$3', '$4']. grammer -> mtp_name field_items eq_token return_type_vector_complex: ['$1', '$2', '$3', '$4']. grammer -> mtp_name field_items eq_token return_type_complex: ['$1', '$2', '$3', '$4']. ... field_items -> field_item : ['$1']. field_items -> field_item field_items : ['$1' | '$2']. field_item -> flags_sharp_token : ['$1']. field_item -> field_name field_primitive_type : [unwrap('$1'), unwrap('$2')]. ... Erlang code. unwrap({Type, _, V}) -> {Type, V}. strip_tail(S) -> lists:sublist(S, 1, length(S)-1).调用语法分析模式的parse函数, 可以生成需要的AST. 然会对AST遍历处理每一种类型的符号, 执行代码生成.
理解
leex 是一个词法分析器, 它的用途是接收输入, 应用词法规则, 并标识输入中的符号, 并把这些符号转换成某种形式让语法分析器能够生成AST.
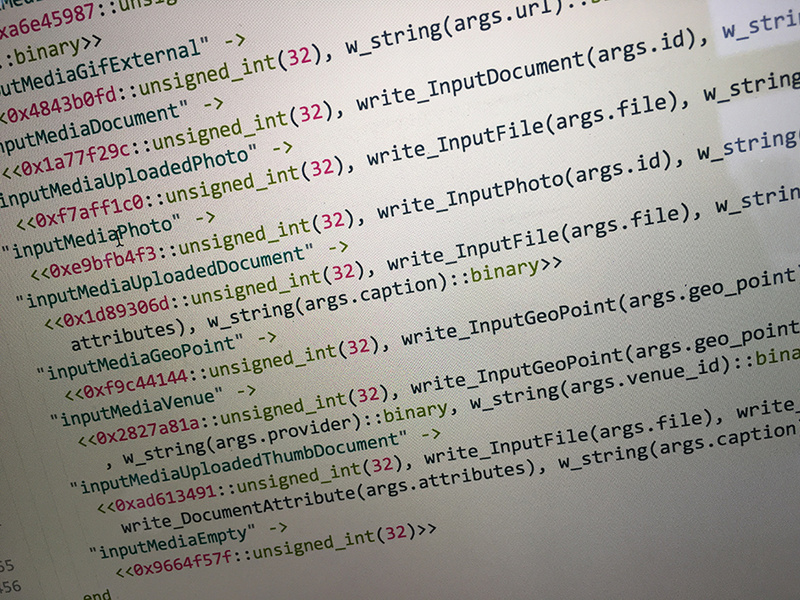
最后生成的代码就是文章开头照片所示.
参考资料
-
LALR语法分析器
-
如何在Elixir中使用Leex和Yecc
-
编写一个模板编译器
-
一个自定义的查询语言
-
Riak QL 的词法规则文件
-
RESTFul API的生成方法
-
Leex 和 Yecc
-
http://andrealeopardi.com/posts/tokenizing-and-parsing-in-elixir-using-leex-and-yecc/
-
http://blog.rusty.io/2011/02/08/leex-and-yecc/
-
http://www.erlang-factory.com/upload/presentations/523/EFSF2012-Implementinglanguages.pdf
-
https://github.com/rvirding/leex/blob/master/examples/erlang_scan.xrl
-
https://arifishaq.wordpress.com/2014/01/22/playing-with-leex-and-yeec/
正文到此结束
热门推荐










相关文章

近期评论
-
666 666
-
666
-
文章和留言都翻到11页了 没有OOM
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
-
-
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

