Nvidia新的Pascal值不值得买(升级)
14 Jun 2016
Nvidia最近更新了三块基于Pascal的GPU,分别是面向高端用户的P100和正常用户的GTX 1080和GTX 1070. 很多用GPU做计算的小伙伴问新卡值不值得买。很明显是,无论从功耗,价格(下面两图比较了N厂各卡),还是内存大小和带宽来看,肯定是新卡更好。而且这是三个之中个人推荐是GTX 1080。原因是P100太贵目前不是一般人能买的,虽然1070和1080在价格,功耗,计算上基本是正比关系。但在付相同额外开销(CPU,内存,机器空间,后期维护)下,1080能得到的计算密度更高。
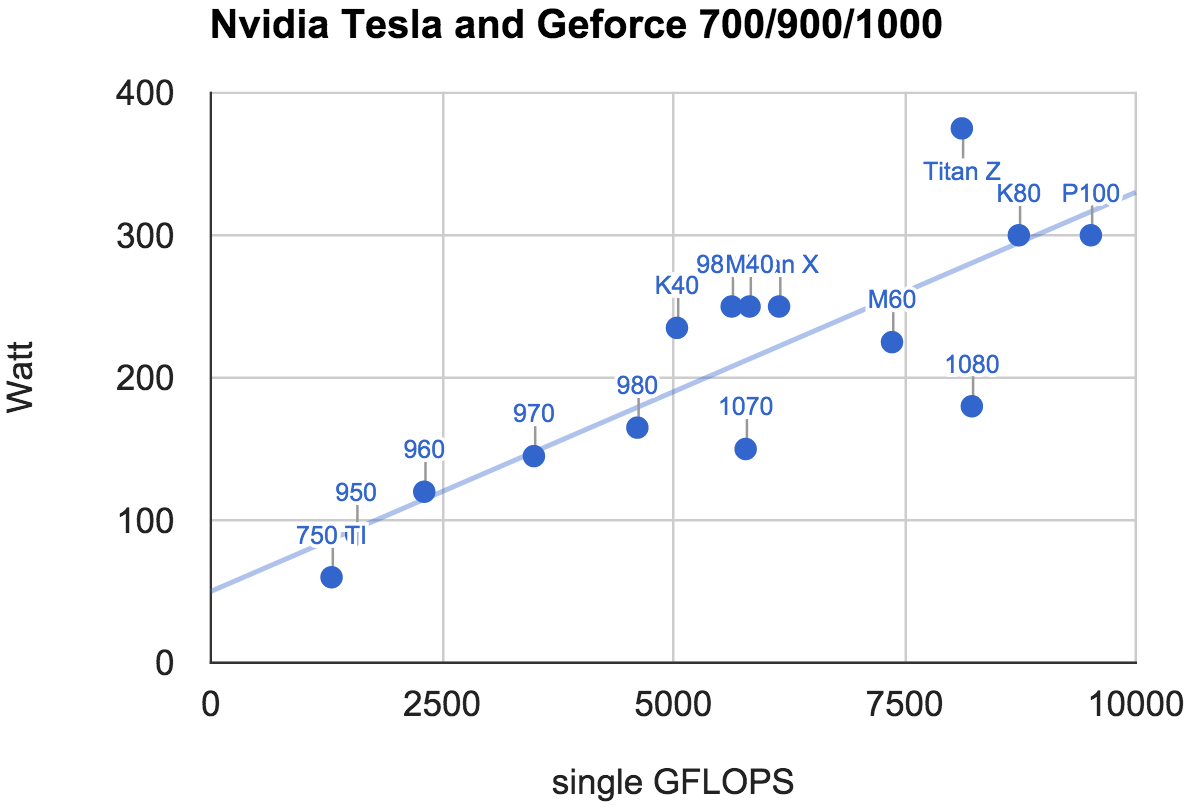
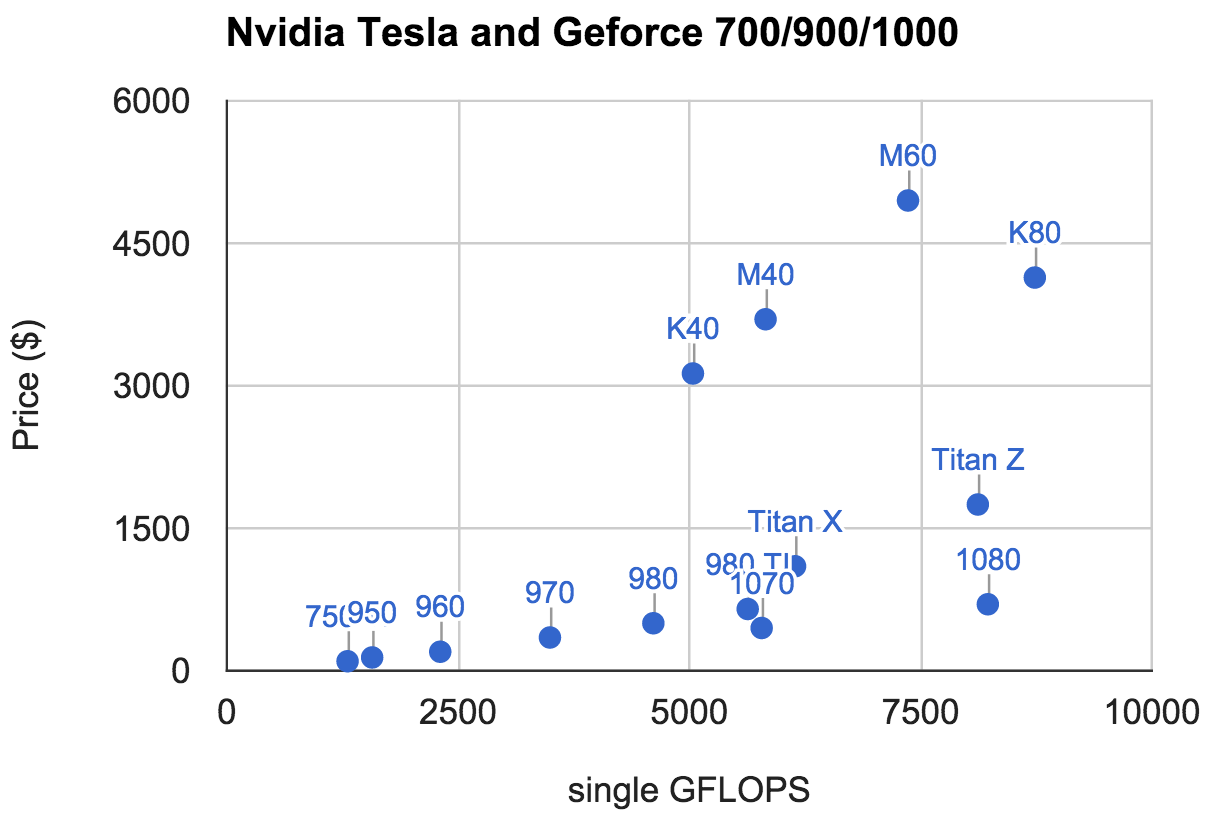
下一个问题是,值不值得升级现有的卡到pascal。这个问题比较纠结,主要是因为nvidia有几个东西没有解释清楚。
如果大家听过黄老大在今年GTC上的报告的话,估计会对P100的21 TFLOPs的半精度(FP16)计算能力有深刻印象。它的原理是把两个FP16并成一个FP32来计算。事实上这也是我们对pascal的最大期望之一。不管是去年NIPS,在GTC前N厂的一个小型deep learning meetup,还是盛会GTC,N厂员工一直说FP16是未来,号召我们大力支持。所以MXNet的小伙伴也花了很多精力折腾FP16,毕竟是两倍性能提升啊。
虽然P100太贵玩不起, 但GTX还是可以的。所以新卡出来后MXNet小伙伴Eric第一时间从N厂化缘了一块GTX 1080,兴高采烈准备测一下MXNet的FP16性能来搞个大新闻。实验跑下来结果眼镜碎一地。
在titanx上fp16比fp32快10%。 基本正常。 在1080上fp16比fp32慢一倍。 fullyconnected慢100倍。。。 还可变的。。。
此时网上也是 议论纷纷 ,甚至大家猜测是N厂故意限速了。
我们马上咨询了下N厂,得到的答复是,GTX 1070/1080确实FP16不快,但是8-bit int (int8)很快哦,在30 TFLOPs以上,你们可以试试啊。汗一地。。。你早说啊。。。
更快的FP16还是int8
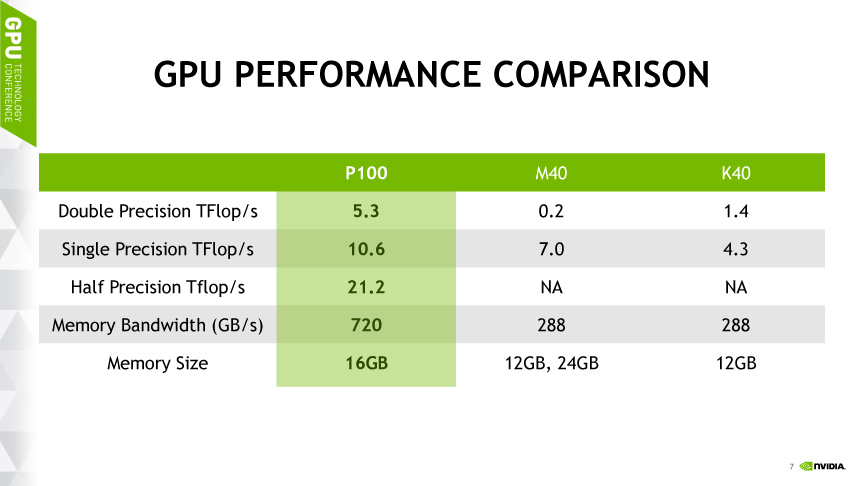
这几天研究下来,我尝试在这里不保证太多准确性的回答下为什么。我们知道P100用的核心是GP100,而GTX 1080、1070用的则是GP104. 下图是GP100的一个SM的架构图。

这里有包含单精度浮点和整数运算单元的core(下图所示),双精度运算的DP Unit,各种特殊函数例如sin/cos的SFU。可以看到core和DP Unit的比例是2:1所以导致P100的单精度和双精度运算能力是2:1的关系。而GP104的DP unit更少,所以双精度浮点运算能力比较低。
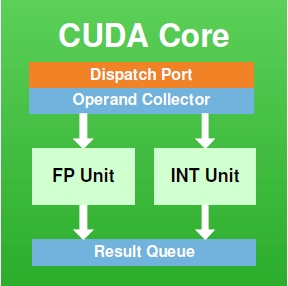
如果对比Pascal和它的前代例如Kepler和Maxwell,会发现SM图大同小异。所以我们以为N厂有特殊技术使得Pascal能够用FP32来算两个FP16. 而实际上是,只是Pascal没有画FP16 unit而已。所以GP100的FP16快,是因为它可以帮助计算FP16的单元多。而GP104没有那么多FP16单元(同样FP64也少),所以慢了。
但是,GP104有特别的技巧,uint8计算单元多。。。所以。。int8快了。。。
问题来了,到底N厂未来是走FP16还是int8路线呢?N厂回答是,我们先搞出来让你们玩着先。到时候看谁好用。根据目前情况看,FP16在有特殊技巧的帮助下,还是能够用来训练模型。而int8主要应用应该主要是在模型预测上。
总结
Pascal目前有两个型号,GP100(对应Tesla P100)和GP104(对应GTX 1080/1070)。前者半精度浮点运算快(FP16),后者8-bit int(int8)运算强。如果是需要买新卡,建议上GTX 1080(不过目前供货不足)。如果考虑主要是做模型预测的话,也可以升级旧卡到GTX 1080。不然的话等年底可能的新卡GTX 1080 TI或者新的Titan X也不错。
最后,招募小伙伴来MXNet折腾下int8。这个也许也是移动端、嵌入式做深度学习预测的未来。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

