Java 编程简介,第 2 部分: 构建真实的应用程序
开始之前
了解有望从本文中获得哪些收获,以及如何从本教程中获得最大的收获。
关于本教程
这个分两部分的 Java 编程简介教程适用于不熟悉 Java 技术的软件开发人员。学习完这两个部分,掌握并使用 Java 语言和平台执行面向对象编程 (OOP) 和实际应用程序开发。
Java 编程简介教程第 2 部分介绍的 Java 语言功能比第 1 部分中介绍的功能更复杂。
目标
Java 语言非常成熟和复杂,可帮助您完成几乎任何编程任务。本教程介绍了在处理复杂的编程场景时所需的 Java 语言特性,包括:
- 异常处理
- 继承和抽象
- 接口
- 嵌套类
- 正则表达式
- 泛型
enum类型- I/O
- 序列化
前提条件
本教程的内容适合不熟悉 Java 语言中各种更复杂特性的初级 Java 语言程序员。本教程假设您已阅读了“Java 编程简介,第 1 部分:Java 语言基础”并且:
- 了解了 Java 平台上的 OOP 基础知识
- 设置了教程示例的开发环境
- 开始将在第 2 部分中继续开发的编程项目
系统要求
要完成本教程中的练习,需要安装并设置一个开发环境,其中包含:
- 来自 Oracle 的 JDK 8
- Eclipse IDE for Java Developers
第 1 部分中提供了这两个软件的下载和安装说明。
推荐的系统配置是:
- 一个支持 Java SE 8、拥有至少 2GB 内存的系统。Linux®、Windows®、Solaris® 和 Mac OS X 都支持 Java 8。
- 至少有 200MB 的磁盘空间来安装软件组件和示例。
对象的后续处理
本教程的第 1 部分介绍了 Person 类,这个类比较有用,但尚未达到它应有的实用程度。在这里,您将开始学习用各种技术增强一个类(比如 Person),首先学习以下技术:
- 重载方法
- 覆盖方法
- 将一个对象与另一个对象进行比较
- 让代码更易于调试
重载方法
创建两个具有相同名称,但具有不同参数列表(即不同数量或类型的参数)的方法时,就拥有了一个重载方法。在运行时,Java 运行时环境(JRE;也称为 Java 运行时)根据传递给它的参数来决定调用哪个重载方法的变体。
假设 Person 需要两个方法来打印其当前状态的审计结果。我将这些方法命名为 printAudit()。将清单 1 中的重载方法粘贴到 Eclipse 编辑器视图中的 Person 类中:
清单 1. printAudit():一个重载方法
public void printAudit(StringBuilder buffer) { buffer.append("Name="); buffer.append(getName()); buffer.append(","); buffer.append("Age="); buffer.append(getAge()); buffer.append(","); buffer.append("Height="); buffer.append(getHeight()); buffer.append(","); buffer.append("Weight="); buffer.append(getWeight()); buffer.append(","); buffer.append("EyeColor="); buffer.append(getEyeColor()); buffer.append(","); buffer.append("Gender="); buffer.append(getGender()); } public void printAudit(Logger l) { StringBuilder sb = new StringBuilder(); printAudit(sb); l.info(sb.toString()); } 您有 printAudit() 的两个重载版本,并且一个版本甚至使用了另一个版本。通过提供两个版本,让调用方能够选择如何打印类的审计结果。根据所传递的参数,Java 运行时会调用正确的方法。
两条方法重载规则
使用重载方法时,记住这两条重要的规则:
- 不能仅通过更改一个方法的返回类型来重载该方法。
- 不能有两个名称和参数列表都相同的方法。
如果违背这些规则,编译器会发出错误信息。
覆盖方法
如果一个类的另一个子类提供了父类中已定义方法的自有实现,就称为方法覆盖。要了解方法覆盖有何用处,需要在 Employee 类上执行一些操作。设置好之后,我将展示方法覆盖在哪些地方很有用。
Employee:Person 的一个子类
回想本教程的第 1 部分,Employee 可以是 Person 的一个子类(或孩子),但拥有额外的属性:
- 纳税人识别编号
- 员工编号
- 招聘日期
- 工资
要在一个名为 Employee.java 的文件中声明这样一个类,可在 Eclipse 中右键单击 com.makotojava.intro 包。单击 New > Class... 打开 New Java Class 对话框,如图 1 所示。
图 1. New Java Class 对话框
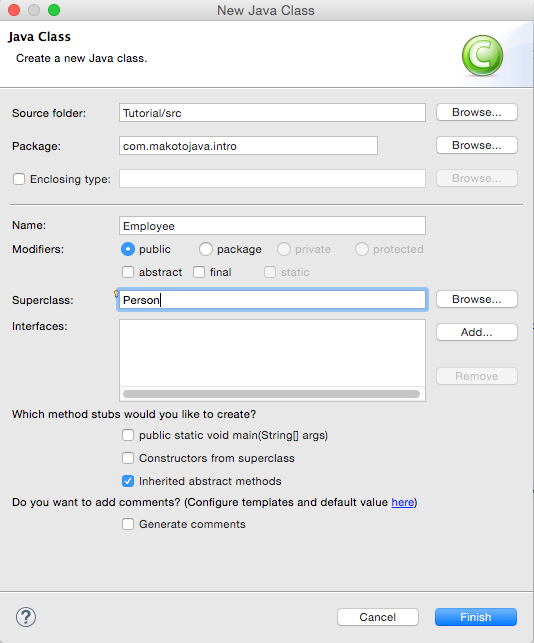
输入 Employee 作为该类的名称,Person 作为它的超类,然后单击 Finish。可在编辑窗口中看到 Employee 类。您没有明确要求声明一个构造函数,但仍然实现了两个构造函数。首先,确保 Employee 类编辑窗口是当前窗口,然后转到 Source > Generate Constructors from Superclass...。 此时会看到一个对话框,可在其中选择要实现的构造函数,如图 2 所示。
图 2. Generate Constructors from Superclass 对话框
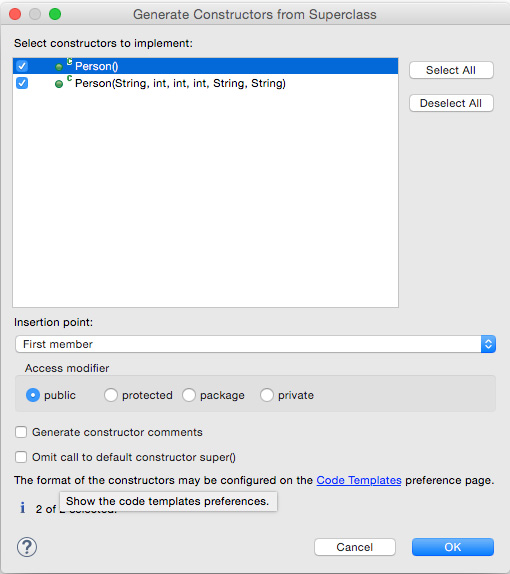
选择两个构造函数(如图 2 所示)并单击 OK。Eclipse 会为您生成这些构造函数。 现在拥有一个与清单 2 类似的 Employee 类。
清单 2. 改进后的新 Employee 类
package com.makotojava.intro; public class Employee extends Person { public Employee() { super(); // TODO Auto-generated constructor stub } public Employee(String name, int age, int height, int weight, String eyeColor, String gender) { super(name, age, height, weight, eyeColor, gender); // TODO Auto-generated constructor stub } }Employee 继承了 Person
在清单 3 中可以看到,Employee 继承了它的父类 Person 的属性和行为,同时也拥有自己的一些属性和行为。
清单 3. 包含 Person 属性的 Employee 类
package com.makotojava.intro; import java.math.BigDecimal; public class Employee extends Person { private String taxpayerIdentificationNumber; private String employeeNumber; private BigDecimal salary; public Employee() { super(); } public String getTaxpayerIdentificationNumber() { return taxpayerIdentificationNumber; } public void setTaxpayerIdentificationNumber(String taxpayerIdentificationNumber) { this.taxpayerIdentificationNumber = taxpayerIdentificationNumber; } // Other getter/setters... }不要忘记为新属性生成 getter 和 setter。第 1 部分中介绍了如何完成该操作。
方法覆盖: printAudit()
现在正如我所承诺的,可以练习覆盖方法了。 您要覆盖 printAudit() 方法(参见清单 1),该方法可格式化 Person 实例的当前状态。Employee 继承了 Person 的行为。如果实例化 Employee,设置它的属性,然后调用 printAudit() 的一个重载方法,则调用会成功完成。但是,生成的审计结果不会全面代表一个 Employee。问题在于,printAudit() 无法格式化特定于 Employee 的属性,因为 Person 不知道这些属性。
解决方案是覆盖可将 StringBuilder 作为参数的 printAudit() 的重载方法,并添加代码来打印特定于 Employee 的属性。
要在 Eclipse IDE 中实现此解决方案,确保已在编辑器窗口中打开或已在 Project Explorer 视图中选择了 Employee。然后转到 Source > Override/Implement Methods...,此时会看到一个对话框(如图 3 所示),可在其中选择要覆盖或实现哪些方法。
图 3. Override/Implement Methods 对话框
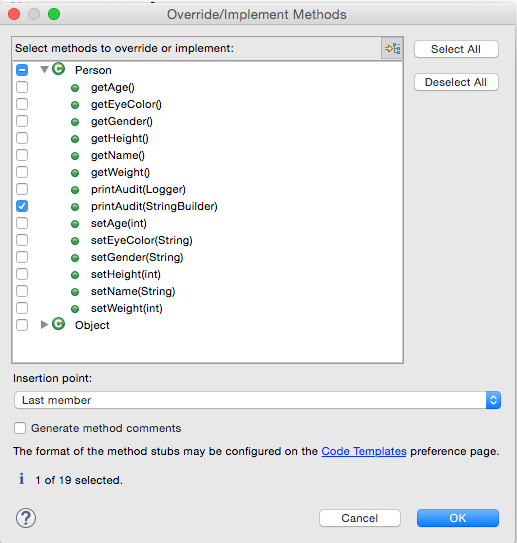
选择 printAudit() 的 StringBuilder 重载方法,如图 3 所示,然后单击 OK。Eclipse 会生成方法存根,然后您可填写剩余的部分,类似这样:
@Override public void printAudit(StringBuilder buffer) { // Call the superclass version of this method first to get its attribute values super.printAudit(buffer); // Now format this instance's values buffer.append("TaxpayerIdentificationNumber="); buffer.append(getTaxpayerIdentificationNumber()); buffer.append(","); buffer.append("EmployeeNumber="); buffer.append(getEmployeeNumber()); buffer.append(","); buffer.append("Salary="); buffer.append(getSalary().setScale(2).toPlainString()); } 请注意对 super.printAudit() 的调用。您在这里所做的是要求 (Person) 超类向 printAudit() 显示其行为,然后使用 Employee 类型的 printAudit() 行为来扩充它。
不需要首先调用 super.printAudit(),首先打印这些属性似乎是个不错的主意。事实上,您根本不需要调用 super.printAudit()。如果不调用它,就必须在 Employee.printAudit() 方法中自行格式化来自 Person 的属性。
类成员
您在 Person 和 Employee 上拥有的变量和方法是实例变量和方法。要使用它们,必须实例化所需要的类,或者拥有对该实例的引用。每个对象实例都拥有变量和方法,而且对于每个实例,准确的行为会有所不同,因为这些行为基于对象实例的状态。
类本身也可拥有变量和方法。可使用第 1 部分中介绍的 static 关键字来声明类变量。类变量与实例变量之间的区别在于:
- 类的每个实例共享一个类变量的单个副本。
- 您可在类本身上调用类方法,而无需拥有实例。
- 实例方法可访问类变量,但类方法无法访问实例变量。
- 类方法只能访问类变量。
添加类变量和方法
何时添加类变量和方法才有意义?最佳的经验是很少添加,这样才不会过度使用它们。尽管如此,在以下情况中使用类变量和方法仍是个不错的主意:
- 声明类的任何实例都可使用的常量(而且常量的值在开发时是固定的)
- 跟踪类实例的“计数器”
- 用在具有实用程序方法的类上,这些方法从不需要该类的实例(比如
Logger.getLogger())
类变量
要创建类变量,在声明变量时请使用 static 关键字:
accessSpecifier static variableName [= initialValue];
备注:此处的方括号表示它们的常量是可选的。方括号不是声明语法的一部分。
JRE 会在内存中创建空间,为所有类实例存储每个类实例变量。相反,JRE 仅创建每个类变量的单个副本,无论有多少个实例都是如此。它在首次加载类时执行此操作(也就是在程序中首次遇到该类时)。类的所有实例共享该变量的这个副本。这使类变量成为所有实例都应该能够使用的常量的不错选择。
例如,可以将 Person 的 Gender 属性声明为 String,但没有对它设置任何约束。清单 4 显示了类变量的一种常见用法。
清单 4. 使用类变量
public class Person { //... public static final String GENDER_MALE = "MALE"; public static final String GENDER_FEMALE = "FEMALE"; // ... public static void main(String[] args) { Person p = new Person("Joe Q Author", 42, 173, 82, "Brown", GENDER_MALE); // ... } //... }声明常量
通常,常量命名要求如下:
- 全部用大写形式命名
- 使用由多个下划线分隔的单词来命名
- 已声明
final(这样就无法修改它们的值) - 使用
public访问说明符来声明(这样其他需要按名称引用常量值的类能够访问这些常量)
在清单 4 中,要在 Person 构造函数调用中使用 MALE 常量,可引用它的名称。要在类外使用一个常量,可将声明它的类的名称放在常量的前面:
String genderValue = Person.GENDER_MALE;
类方法
如果您是从第 1 部分开始学习的,那么已调用了静态 Logger.getLogger() 方法多次 — 检索 Logger 实例来将输出写到控制台时就会调用。但是请注意,并不需要一个 Logger 实例来这么做;可引用 Logger 类本身。这是执行类方法调用的语法。与类变量一样,static 关键字将 Logger(在本例中)标识为类方法。因此,有时也将类方法称为静态方法。
使用类方法
现在,将所学的静态变量和方法组合到一起,就可在 Employee 上创建一个静态方法。声明一个 private static final 变量来持有 Logger,所有实例都共享它,而且可通过在 Employee 类上调用 getLogger() 来访问它。清单 5 显示了如何执行该操作。
清单 5. 创建一个类(或静态)方法
public class Employee extends Person { private static final Logger logger = Logger.getLogger(Employee.class.getName()); //... public static Logger getLogger() { return logger; } }清单 5 中发生了两件重要的事:
- 声明
Logger实例时使用了private访问级别,所以Employee外部的任何类都无法直接访问该引用。 - 在加载该类时初始化
Logger— 因为我们使用 Java 初始化器语法来向它提供值。
要检索 Employee 类的 Logger 对象,可执行以下调用:
Logger employeeLogger = Employee.getLogger();
比较对象
Java 语言提供了两种方式来比较对象:
==运算符equals()方法
使用 == 比较对象
== 语法比较对象是否相等,只有在 a 和 b 拥有相同的值时,a == b 才返回 true。对于对象,需要两个对象引用同一个对象实例。对于原语,需要它们的值相等。假设为 Employee 生成一个 JUnit 测试(第 1 部分介绍了如何操作)。清单 6 中显示了 JUnit 测试。
清单 6. 使用 == 比较对象
public class EmployeeTest { @Test public void test() { int int1 = 1; int int2 = 1; Logger l = Logger.getLogger(EmployeeTest.class.getName()); l.info("Q: int1 == int2? A:" + (int1 == int2)); Integer integer1 = Integer.valueOf(int1); Integer integer2 = Integer.valueOf(int2); l.info("Q:Integer1 == Integer2? A:" + (integer1 == integer2)); integer1 = new Integer(int1); integer2 = new Integer(int2); l.info("Q:Integer1 == Integer2? A:" + (integer1 == integer2)); Employee employee1 = new Employee(); Employee employee2 = new Employee(); l.info("Q:Employee1 == Employee2?A:" + (employee1 == employee2)); } } 如果在 Eclipse 中运行清单 6 的代码(在 Project Explorer 视图中选择 Employee,然后选择 Run As > JUnit Test),输出应该是:
Sep 18, 2015 5:09:56 PM com.makotojava.intro.EmployeeTest test INFO:Q: int1 == int2? A: true Sep 18, 2015 5:09:56 PM com.makotojava.intro.EmployeeTest test INFO:Q:Integer1 == Integer2? A: true Sep 18, 2015 5:09:56 PM com.makotojava.intro.EmployeeTest test INFO:Q:Integer1 == Integer2? A: false Sep 18, 2015 5:09:56 PM com.makotojava.intro.EmployeeTest test INFO:Q:Employee1 == Employee2?A: false
在清单 6 中的第一种情况下,原语的值相同,所以 == 运算符返回 true。在第二种情况下,Integer 对象引用相同的实例,所以 == 同样返回 true。在第三种情况下,尽管 Integer 对象包含相同的值,但 == 返回 false,因为 integer1 和 integer2 引用了不同的对象。可将 == 视为对“相同对象”进行一种测试。
使用 equals() 比较对象
equals() 是每种 Java 语言对象都可自由使用的方法,因为它被定义为 java.lang.Object(每个 Java 对象都继承自该对象)的一个实例方法。
可像使用其他任何方法那样调用 equals():
a.equals(b);
这条语句调用对象 a 的 equals() 方法,向它传递对象 b 的引用。默认情况下,Java 程序会使用 == 语法简单地检查两个对象是否相同。因为 equals() 是一个方法,但是可以被覆盖。将清单 6 中的 JUnit 测试案例与清单 7 中的测试案例(我称之为 anotherTest())进行比较,后者使用 equals() 来比较两个对象:
清单 7. 使用 equals() 比较对象
@Test public void anotherTest() { Logger l = Logger.getLogger(Employee.class.getName()); Integer integer1 = Integer.valueOf(1); Integer integer2 = Integer.valueOf(1); l.info("Q: integer1 == integer2 ?A:" + (integer1 == integer2)); l.info("Q: integer1.equals(integer2) ?A:" + integer1.equals(integer2)); integer1 = new Integer(integer1); integer2 = new Integer(integer2); l.info("Q: integer1 == integer2 ?A:" + (integer1 == integer2)); l.info("Q: integer1.equals(integer2) ?A:" + integer1.equals(integer2)); Employee employee1 = new Employee(); Employee employee2 = new Employee(); l.info("Q: employee1 == employee2 ?A:" + (employee1 == employee2)); l.info("Q: employee1.equals(employee2) ?A :" + employee1.equals(employee2)); }运行清单 7 的代码会生成:
Sep 19, 2015 10:11:57 AM com.makotojava.intro.EmployeeTest anotherTest INFO:Q: integer1 == integer2 ?A: true Sep 19, 2015 10:11:57 AM com.makotojava.intro.EmployeeTest anotherTest INFO:Q: integer1.equals(integer2) ?A: true Sep 19, 2015 10:11:57 AM com.makotojava.intro.EmployeeTest anotherTest INFO:Q: integer1 == integer2 ?A: false Sep 19, 2015 10:11:57 AM com.makotojava.intro.EmployeeTest anotherTest INFO:Q: integer1.equals(integer2) ?A: true Sep 19, 2015 10:11:57 AM com.makotojava.intro.EmployeeTest anotherTest INFO:Q: employee1 == employee2 ?A: false Sep 19, 2015 10:11:57 AM com.makotojava.intro.EmployeeTest anotherTest INFO:Q: employee1.equals(employee2) ?A : false
关于比较 Integer 的说明
在清单 7 中,如果 == 返回 true,Integer 的 equals() 方法就会返回 true,对此不应感到奇怪。但请注意第二种情况中发生的事情,在其中创建了都包含值 1 的不同对象:== 返回 false,因为 integer1 和 integer2 引用不同的对象;但 equals() 却返回 true。
JDK 的编写者认为,对于 Integer,equals() 的含义与默认含义不同(回想一下,默认含义是比较对象引用,看看它们是否引用同一个对象)。对于 Integer,在底层的 int 值相同时,equals() 返回 true。
对于 Employee,您没有覆盖 equals(),所以(使用 == 的)默认行为返回了您期望的结果,因为 employee1 和 employee2 引用不同的对象。
然后,对于所编写的任何对象,可定义适合所编写应用程序的 equals() 含义。
覆盖 equals()
可通过覆盖 Object.equals() 的默认行为,定义 equals() 对于应用程序对象的含义。同样,也可使用 Eclipse 完成此任务。确保 Employee 拥有 Eclipse IDE 源代码窗口中的焦点,然后转到 Source > Override/ImplementMethods。此时打开图 4 中所示的对话框。
图 4. Override/Implement Methods 对话框
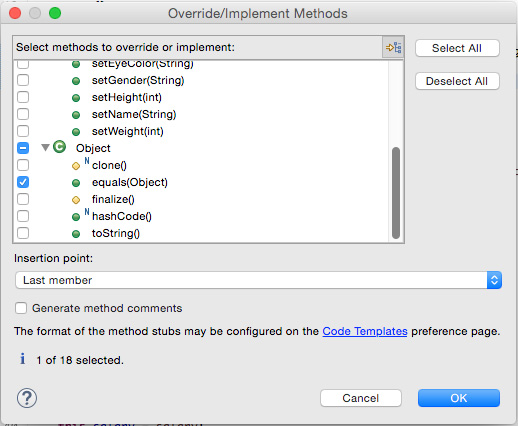
您之前使用过这个对话框,但在本例中,我们要实现 Object.equals() 超类方法。所以在方法列表中找到要覆盖或要实现的 Object,选择 equals(Object) 方法,然后单击 OK。Eclipse 生成正确的代码并将它放在源文件中。
如果两个 Employee 对象的状态相等,则这两个对象相等,这样就有意义了。也就是说,如果它们的值 — 姓氏、名字、年龄 — 相同,那么它们就相等。
自动生成 equals()
Eclipse 可根据您为一个类所定义的实例变量(属性)来生成一个 equals() 方法。因为 Employee 是 Person 的子类,所以首先为 Person 生成 equals()。在 Eclipse 的 Project Explorer 视图中,右键单击 Person 并选择 Generate hashCode() and equals(),打开图 5 中所示的对话框,选择要在 hashCode() 和 equals() 方法中包含哪些属性。
图 5. Generate hashCode() and equals() 对话框
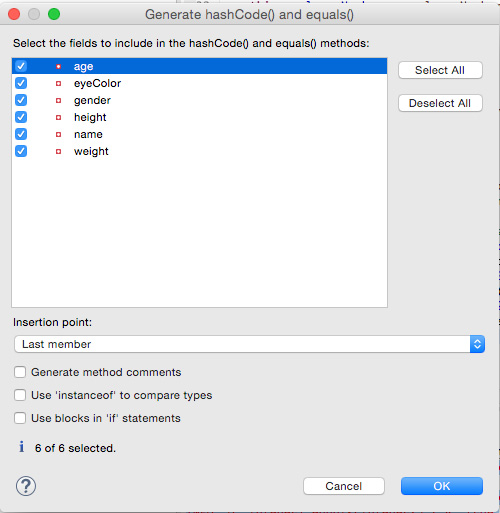
选择所有属性(如图 5 所示)后单击 OK。Eclipse 生成一个与清单 8 中所示内容类似的 equals() 方法。
清单 8. Eclipse 生成的 equals() 方法
@Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Person other = (Person) obj; if (age != other.age) return false; if (eyeColor == null) { if (other.eyeColor != null) return false; } else if (!eyeColor.equals(other.eyeColor)) return false; if (gender == null) { if (other.gender != null) return false; } else if (!gender.equals(other.gender)) return false; if (height != other.height) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; if (weight != other.weight) return false; return true; } 现在无需担心 hashCode()— 您可保留或删除它。Eclipse 生成的 equals() 方法看起来很复杂,但它的操作很简单:如果传入的对象与清单 8 中的对象相同,则 equals() 返回 true。如果传入的对象为 null(表示缺失),则返回 false。
接下来,该方法检查 Class 对象是否相同(意味着传入的对象必须是一个 Person 对象)。如果它们相同,会检查已传入对象的每个属性值,查看它是否与给定 Person 实例的状态逐值匹配。如果属性值为 null,equals() 会检查尽可能多的次数,如果这些值匹配,则认为这些对象相等。您可能不希望每个程序都具有这种行为,但它适用于大多数用途。
练习:为 Employee 生成一个 equals()
尝试执行“自动生成 equals()”中的操作步骤,为 Employee 生成一个 equals()。生成 equals() 后,添加下面这个 JUnit 测试案例(我将它称为 yetAnotherTest()):
@Test public void yetAnotherTest() { Logger l = Logger.getLogger(Employee.class.getName()); Employee employee1 = new Employee(); employee1.setName("J Smith"); Employee employee2 = new Employee(); employee2.setName("J Smith"); l.info("Q: employee1 == employee2? A:" + (employee1 == employee2)); l.info("Q: employee1.equals(employee2)?A:" + employee1.equals(employee2)); }如果运行该代码,应该看到以下输出:
Sep 19, 2015 11:27:23 AM com.makotojava.intro.EmployeeTest yetAnotherTest INFO:Q: employee1 == employee2? A: false Sep 19, 2015 11:27:23 AM com.makotojava.intro.EmployeeTest yetAnotherTest INFO:Q: employee1.equals(employee2)?A: true
在本例中,单单 Name 上的一个匹配值就足以让 equals() 相信两个对象相等。尝试向此示例添加更多属性,看看会获得什么。
练习:覆盖 toString()
还记得本部分开头的 printAudit() 方法吗?如果您认为它的工作太困难了,那就对了。 将一个对象的状态格式化为 String 是一种常见的模式,以至于 Java 语言的设计者已在一个(意料之中的)名为 toString() 的方法中将它内置到 Object 自身中。toString() 的默认实现不是很有用,但每个对象都有一个。在此练习中,您可让默认的 toString() 更有用。
如果认为 Eclipse 可为您生成一个 toString() 方法,那就对了。返回 Project Explorer 并右键单击 Person 类,然后选择 Source > Generate toString()...。此时会看到一个类似图 5 的对话框。选择所有属性并单击 OK。现在对 Employee 执行相同的操作。 Eclipse 为 Employee 生成的代码如清单 9 所示。
清单 9. Eclipse 生成的 toString() 方法
@Override public String toString() { return "Employee [taxpayerIdentificationNumber=" + taxpayerIdentificationNumber + ", employeeNumber=" + employeeNumber + ", salary=" + salary + "]"; } Eclipse 为 toString 生成的代码不包含超类的 toString()(Employee 的超类为 Person)。使用 Eclipse,可通过这个覆盖方法快速解决问题:
@Override public String toString() { return super.toString() + "Employee [taxpayerIdentificationNumber=" + taxpayerIdentificationNumber + ", employeeNumber=" + employeeNumber + ", salary=" + salary + "]"; } 添加 toString() 使 printAudit() 大大简化:
@Override public void printAudit(StringBuilder buffer) { buffer.append(toString()); }toString() 现在执行了主要的对象当前状态格式化工作,您只需将它返回的值放入 StringBuilder 并返回。
如果仅用于支持用途,我推荐您始终在类中实现 toString()。几乎不可避免的是,在某个时刻,您想在应用程序运行时查看一个对象的状态是什么,toString() 是一个实现此目的很好的挂钩。
异常
任何程序都无法始终正常运行,Java 语言的设计者完全了解这一点。在本节中,我会介绍 Java 平台的各种内置机制,处理代码未准确地按计划运行的情况。
异常处理基础
异常是在程序执行期间发生的、可破坏正常程序指令流的事件。异常处理是 Java 编程的一项基础技术。其基本机制是,您将代码包装在一个 try 代码块中(这表示“尝试此代码并让我知道它是否导致了异常”),并使用它 catch 各种类型的异常。
要想开始执行异常处理,可查看清单 10 中的代码。
清单 10. 您发现错误了吗?
@Test public void yetAnotherTest() { Logger l = Logger.getLogger(Employee.class.getName()); // Employee employee1 = new Employee(); Employee employee1 = null; employee1.setName("J Smith"); Employee employee2 = new Employee(); employee2.setName("J Smith"); l.info("Q: employee1 == employee2? A:" + (employee1 == employee2)); l.info("Q: employee1.equals(employee2)?A:" + employee1.equals(employee2)); } 请注意,Employee 引用被设置为 null。运行此代码会获得以下输出:
java.lang.NullPointerException at com.makotojava.intro.EmployeeTest.yetAnotherTest(EmployeeTest.java:49) . . .
IDE 警告
运行清单 10 的代码时可能会注意到,Eclipse 通过下面这条消息提醒潜在的错误: Null pointer access:The variable employee1 can only be null at this location.
Eclipse 会提醒许多潜在的开发错误 — 这是使用 IDE 执行 Java 开发的另一个优势。
此输出告诉您,您正在尝试通过一个 null 引用(指针)来引用一个对象,这是一个非常严重的开发错误。
幸运的是,可使用 try 和 catch 代码块捕获它(还有来自 finally 的一些帮助)。
try、catch 和 finally
清单 11 显示了使用标准异常处理代码块从清单 10 中清除的错误代码: try、catch 和 finally。
清单 11. 捕获一个异常
@Test public void yetAnotherTest() { Logger l = Logger.getLogger(Employee.class.getName()); // Employee employee1 = new Employee(); try { Employee employee1 = null; employee1.setName("J Smith"); Employee employee2 = new Employee(); employee2.setName("J Smith"); l.info("Q: employee1 == employee2? A:" + (employee1 == employee2)); l.info("Q: employee1.equals(employee2)?A:" + employee1.equals(employee2)); } catch (Exception e) { l.severe("Caught exception:" + e.getMessage()); } finally { // Always executes } }try、catch 和 finally 代码块一同构成了一张捕获异常的大网。首先,try 语句包装可能抛出异常的代码。在该例子中,异常直接放在 catch 代码块或异常处理函数中。在所有 try 和 catch 都完成后,会继续执行 finally 代码块,无论是否抛出了异常都是如此。捕获到一个异常时,您可尝试优雅地从异常中恢复,或者退出程序(或方法)。
在清单 11 中,程序从错误中恢复,然后打印出异常的消息:
Sep 19, 2015 2:01:22 PM com.makotojava.intro.EmployeeTest yetAnotherTest SEVERE:Caught exception: null
异常分层结构
Java 语言包含一个完整的异常分层结构,它由多种类型的异常组成,这些异常主要分为两类:
- 已检查的异常 已由编译器检查(表示编译器确定已在代码中的某处处理过这些异常)。
- 未检查的异常(也称为运行时异常)未由编译器检查。
程序导致异常时,您可以说它抛出了异常。任何方法都可在方法签名中包含 throws 关键字,从而向编译器声明已检查的异常。接下来是一个该方法可能在执行期间抛出的各种异常的逗号分隔列表。如果代码所调用的一个方法指定它抛出一种或多种类型的异常,就必须对它进行一定的处理,或者向方法签名中添加一个 throws 来传递该异常类型。
发生异常时,Java 运行时在堆栈中向上搜索异常处理函数。如果到达堆栈顶部时仍未找到异常处理函数,它会立即终止程序,就像在清单 10 中看到的一样。
多个 catch 代码块
您可拥有多个 catch代码块,但必须以特定的方式来搭建它们。如果任何异常是其他异常的子类,那么子类按 catch 代码块的顺序放在父类前面。清单 12 显示了按正确的分层结构顺序搭建的不同异常类型示例。
清单 12. 异常分层结构示例
@Test public void exceptionTest() { Logger l = Logger.getLogger(Employee.class.getName()); File file = new File("file.txt"); BufferedReader bufferedReader = null; try { bufferedReader = new BufferedReader(new FileReader(file)); String line = bufferedReader.readLine(); while (line != null) { // Read the file } } catch (FileNotFoundException e) { l.severe(e.getMessage()); } catch (IOException e) { l.severe(e.getMessage()); } catch (Exception e) { l.severe(e.getMessage()); } finally { // Close the reader } } 在这个示例中,FileNotFoundException 是 IOException 的子类,所以必须将它放在 IOException catch 代码块的前面。IOException 是 Exception 的子类,所以必须将它放在 Exception catch 代码块的前面。
try-with-resources 代码块
从 JDK 7 开始,资源管理工作变得简单多了。随着所使用的文件和 java.io 包越来越多,就越会认识到新语法的好处。清单 12 中的代码必须声明一个变量来持有 bufferedReader 引用,然后在 finally 中必须关闭 BufferedReader。
新的 try-with-resources 语法会在 try 代码块超出范围时自动关闭资源。清单 13 显示了更紧凑的语法。
清单 13. 资源管理语法
@Test public void exceptionTestTryWithResources() { Logger l = Logger.getLogger(Employee.class.getName()); File file = new File("file.txt"); try (BufferedReader bufferedReader = new BufferedReader(new FileReader(file))) { String line = bufferedReader.readLine(); while (line != null) { // Read the file } } catch (Exception e) { l.severe(e.getMessage()); } } 从本质上来说,要在 try 后面的圆括号内分配资源变量,在 try 代码块超出范围时,系统会自动关闭这些资源。这些资源必须实现 java.lang.AutoCloseable 接口;如果尝试在一个没有实现该接口的资源类上实现此语法,Eclipse 会提醒您。
构建 Java 应用程序
在本节中,我们继续将 Person 构建为 Java 应用程序。在此过程中,您可更好地了解一个对象或对象集合如何演变成应用程序。
Java 应用程序的元素
所有 Java 应用程序都需要一个入口点,这样 Java 运行时才能知道从这里开始执行代码。这个入口点就是 main() 方法。 域对象通常没有 main() 方法,但每个应用程序至少有一个类拥有该方法。
您从第 1 部分开始就一直在开发一个人力资源应用程序示例,其中包括 Person 及其 Employee 子类。现在看看将一个新类添加到应用程序时会发生什么。
创建一个 Driver 类
顾名思义,Driver 类的用途是“驱动”一个应用程序。请注意,人力资源应用程序的这个简单 Driver 包含一个 main() 方法:
package com.makotojava.intro; public class HumanResourcesApplication { public static void main(String[] args) { } } 在 Eclipse 中创建 Driver 类的过程与创建 Person 和 Employee 的过程相同。将该类命名为 HumanResourcesApplication,确保选择了相关的选项,向该类添加一个 main() 方法。Eclipse 将为您生成该类。
将一些代码添加到新的 main() 方法中,使其类似于下面这段代码:
package com.makotojava.intro; import java.util.logging.Logger; public class HumanResourcesApplication { private static final Logger log = Logger.getLogger(HumanResourcesApplication.class.getName()); public static void main(String[] args) { Employee e = new Employee(); e.setName("J Smith"); e.setEmployeeNumber("0001"); e.setTaxpayerIdentificationNumber("123-45-6789"); e.setSalary(BigDecimal.valueOf(45000.0)); e.printAudit(log); } } 现在,启动 HumanResourcesApplication 类并观察它的运行情况。您应看到此输出(反斜杠表示一个连续行):
Sep 19, 2015 7:59:37 PM com.makotojava.intro.Person printAudit INFO:Name=J Smith,Age=0,Height=0,Weight=0,EyeColor=null,Gender=null/ TaxpayerIdentificationNumber=123-45-6789,EmployeeNumber=0001,Salary=45000.00
这就是创建一个简单 Java 应用程序的全部过程。在下一部分中,将介绍一些可帮助您开发更复杂应用程序的语法和库。
继承
您在本教程中已遇到过多个继承示例。本节复习第 1 部分中有关继承的一些内容,并更详细地解释继承的工作原理 — 包括继承分层结构、构造函数和继承,以及继承抽象。
继承的工作原理
Java 代码中的各个类位于分层结构中。分层结构中一个给定类上方的类是该类的超类。这个特定的类是该分层结构更高层中每个类的子类。子类继承其超类的属性和行为。java.lang.Object 类位于类分层结构的顶部,意味着每个 Java 类都是 Object 的子类并继承其属性和行为。
例如,假设有一个与清单 14 的内容类似的 Person 类。
清单 14. 公共 Person 类
public class Person { public static final String STATE_DELIMITER = "~"; public Person() { // Default constructor } public enum Gender { MALE, FEMALE, UNKNOWN } public Person(String name, int age, int height, int weight, String eyeColor, Gender gender) { this.name = name; this.age = age; this.height = height; this.weight = weight; this.eyeColor = eyeColor; this.gender = gender; } private String name; private int age; private int height; private int weight; private String eyeColor; private Gender gender; 清单 14 中的 Person 类隐式地继承了 Object。因为我们会假定每个类都继承 Object,所以不需要为您定义的每个类键入 extends Object。但说一个类继承它的超类是什么意思?它表示 Person 能够访问其超类中已公开的变量和方法。在本例中,Person 可查看和使用 Object 的公共方法和变量,以及 Object 的受保护方法和变量。
定义一个类分层结构
现在假设有一个继承 Person 的 Employee 类。Employee 的类定义(或继承图)类似于这样:
public class Employee extends Person { private String taxpayerIdentificationNumber; private String employeeNumber; private BigDecimal salary; // ... }多重继承与单一继承
C++ 等语言支持多重继承 概念:在分层结构中的任一点,一个类都可继承一个或多个类。Java 语言仅支持单一继承— 意味着只能为一个类使用 extends 关键字。所以任何 Java 类的类分层结构始终包含一条一直到 java.lang.Object 的直线。但是,您在本教程后面会了解到,Java 语言支持在单个类中实现多个接口,因此为单一继承提供了一种规避方法。
Employee 继承图暗示,Employee 能够访问 Person 中的所有公共和受保护变量和方法(因为 Employee 直接扩展 Person),以及 Object 中的公共和受保护变量和方法(因为 Employee 实际上也扩展了 Object,尽管是间接扩展)。但是,因为 Employee 和 Person 都位于同一个包中,所以 Employee 也能访问 Person 中的 package-private(有时称为友好)变量。
要想深入了解类分层结构,可创建第三个扩展 Employee 的类:
public class Manager extends Employee { // ... }在 Java 语言中,任何类可拥有最多 1 个超类,但一个类可拥有任意个子类。这是 Java 语言继承分层结构方面要记住的最重要一点。
构造函数和继承
构造函数不是完整的面向对象成员,所以它们不是继承的;您必须在子类中明确地实现它们。 介绍该主题之前,我要回顾一下有关如何定义和调用构造函数的一些基本规则。
构造函数基础知识
请记住,一个构造函数的名称始终与它用于构造的类相同,而且它没有返回类型。例如:
public class Person { public Person() { } }每个类至少拥有一个构造函数,而且如果没有明确地为类定义构造函数,那么编译器会生成一个(称为默认构造函数)。前面的类定义和这个类定义具有相同的功能:
public class Person { }调用一个超类构造函数
要调用一个超类构造函数,而不是默认的构造函数,也必须明确地这么做。例如,假设 Person 拥有一个构造函数,该函数仅接受所创建的 Person 对象的名称。通过 Employee 的默认构造函数,您可调用 Person 构造函数,如清单 15 所示:
清单 15. 初始化一个新的 Employee
public class Person { private String name; public Person() { } public Person(String name) { this.name = name; } } // Meanwhile, in Employee.java public class Employee extends Person { public Employee() { super("Elmer J Fudd"); } } 但是,您可能绝对不想以这种方式初始化一个新的 Employee 对象。更熟悉面向对象的概念和一般性的 Java 语法之前,如果认为需要超类构造函数,一个不错的想法是在子类中实现它们。清单 16 在 Employee 中定义了一个与 Person 中的构造函数相似的构造函数,以便它们匹配。从维护的角度讲,这种方法要清楚易懂得多。
清单 16. 调用一个超类
public class Person { private String name; public Person(String name) { this.name = name; } } // Meanwhile, in Employee.java public class Employee extends Person { public Employee(String name) { super(name); } }声明一个构造函数
构造函数所做的第一件事就是调用其直接超类的默认构造函数,除非您 — 在该构造函数的第一行代码中 — 调用了一个不同的构造函数。例如,这两种声明具有相同的功能,所以可挑选一个:
public class Person { public Person() { } } // Meanwhile, in Employee.java public class Employee extends Person { public Employee() { } }或者:
public class Person { public Person() { } } // Meanwhile, in Employee.java public class Employee extends Person { public Employee() { super(); } }无参数构造函数
如果您提供了一个替代的构造函数,就必须明确地提供默认构造函数;否则后者将不可用。例如,以下代码会出现编译错误:
public class Person { private String name; public Person(String name) { this.name = name; } } // Meanwhile, in Employee.java public class Employee extends Person { public Employee() { } } 此示例中的 Person 类没有默认构造函数,因为它提供了一个替代性的构造函数,但没有明确地包含默认构造函数。
构造函数如何调用构造函数
一个构造函数可通过 this 关键字和一个参数列表来调用另一个类中的构造函数。像 super() 一样,this() 调用必须是构造函数中的第一行代码。例如:
public class Person { private String name; public Person() { this("Some reasonable default?"); } public Person(String name) { this.name = name; } }您会经常看到此用法,其中一个构造函数委托给另一个构造函数,如果调用后者,则传入一个默认构造函数。向一个类添加一个新构造函数,同时最大限度减少对已使用旧构造函数的代码的影响,这也是一种不错的方式。
构造函数访问级别
构造函数可拥有您想要的任何访问级别,并且会应用一些可见性规则。表 1 总结了构造函数访问规则。
表 1. 构造函数访问规则
| 构造函数访问修饰符 | 描述 |
|---|---|
public | 任何类都可调用构造函数。 |
protected | 只能由同一个包或任何子类中的类调用构造函数。 |
| 无修饰符(package-private) | 同一个包中的任何类都可调用构造函数。 |
private | 只能由定义构造函数的类调用该构造函数。 |
您可能想到了将构造函数声明为 protected 甚至是 package-private 的用例,不过 private 构造函数有何用处?比如说在实现工厂模式时,我不允许通过 new 关键字直接创建对象,此时就使用了私有构造函数。在这种情况下,我会使用一个静态方法来创建类的实例,而且该方法 — 包含在该类中 — 将允许调用这个私有构造函数。
继承和抽象
如果一个子类覆盖了超类中的一个方法,该方法在本质上是隐藏的,因为通过对子类的引用来调用它时,会调用该方法的子类版本,而不是超类版本。这并不是说,无法再访问超类方法。子类可在方法名称前添加 super 关键字来调用超类方法(与构造函数规则不同,这可从子类方法的任何行中执行,甚至可在一个不同的方法内执行)。默认情况下,如果通过对子类的引用来调用子类方法,那么 Java 程序会调用它。
这同样适用于变量,前提是调用方能够访问该变量(也就是变量对尝试访问它的代码是可见的)。随着您逐渐精通 Java 编程,此细节可能会让您非常伤心。但是,Eclipse 提供了大量的警告来提示您正在隐藏来自超类的变量,或者方法调用没有调用您认为它应调用的实体。
在 OOP 上下文中,抽象是指将数据和行为一般化为某种类型,这种类型在继承分层结构中比当前类具有更高的层级。将变量或方法从一个子类移动到一个超类时,就可以说是在抽象化这些成员。这么做的主要目的是,通过将通用的代码推送到分层结构中尽可能高的层级,从而重用这些代码。将通用的代码放在一个位置也更容易维护。
抽象类和方法
有时,您希望创建一些仅用作抽象,而不是必需实例化的类。这些类称为抽象类。出于同样的原因,有时需要以不同的方式为每个实现超类的子类实现某些方法。这些方法是抽象方法。以下是抽象类和抽象方法的一些基本规则:
- 可将任何类声明为
abstract。 - 无法实例化抽象类。
- 抽象方法不能包含一个方法主体。
- 任何包含抽象方法的类都必须声明为
abstract。
使用抽象
假设您不允许直接实例化 Employee 类。使用 abstract 关键字声明它即可:
public abstract class Employee extends Person { // etc. }如果尝试运行此代码,会出现一个编译错误:
public void someMethodSomwhere() { Employee p = new Employee();// compile error!! } 编译器抱怨 Employee 是抽象的,因此无法实例化。
抽象的力量
假设您需要一个方法来检查 Employee 对象的状态并确保该对象是有效的。此需求似乎在所有 Employee 对象中很常见,但它的行为在所有完全无法重用它的潜在子类中具有巨大的差别。在这种情况下,可将 validate() 方法声明为 abstract(强制所有子类实现它):
public abstract class Employee extends Person { public abstract boolean validate(); }Employee 的每个直接子类(比如 Manager)现在必须实现 validate() 方法。但是,一旦一个子类实现了 validate() 方法,该子类的所有子类都不需要实现它了。
例如,假设您拥有一个扩展了 Manager 的 Executive 对象。此定义是有效的:
public class Executive extends Manager { public Executive() { } }何时(不)抽象化:两条规则
首个经验规则是,不要在初始设计中抽象化。在设计工作的早期使用抽象类会迫使您进入某条路径,而且这可能对应用程序造成限制。请记住,始终可在继承图中的更高层级上重构共有的行为(这是拥有抽象类的唯一理由)。发现您的确需要重构时,最好进行重构。Eclipse 对重构提供了极好的支持。
第二,尽管抽象类很强大,但一定要抵制住诱惑。除非超类包含大量相同的行为,而且该行为本身没有意义,否则要保持它们非抽象化。层次较深的继承图可能使代码维护工作变得很困难。要在超级大类与可维护的代码之间实现一种平衡。
赋值:类
您可将一个引用从一个类赋给某个类型的变量(属于另一个类),但要遵守一些规则。看看这个示例:
Manager m = new Manager(); Employee e = new Employee(); Person p = m; // okay p = e; // still okay Employee e2 = e; // yep, okay e = m; // still okay e2 = p; // wrong!
目标变量必须是属于来源引用的类的超类型,否则编译器会报错。基本来讲,赋值等式的右侧必须是左侧实体的子类或同一个类。如果不是,可将具有不同继承图的对象(比如 Manager 和 Employee)的赋值赋给错误类型的变量。 现在考虑这个示例:
Manager m = new Manager(); Person p = m; // so far so good Employee e = m; // okay Employee e = p; // wrong!
尽管 Employee 是一个 Person,但它几乎肯定不是 Manager,而且编译器会保持这种差别。
接口
在本节中,您开始学习接口,并开始在 Java 代码中使用它们。
定义一个接口
接口是实现者必须提供其代码的一组指定的行为(或常量数据元素)。接口指定该实现所提供的行为,而不是如何完成该行为。
定义接口非常简单:
public interfaceinterfaceName { returnType methodName(argumentList); } 接口声明看起来很像类声明,不过要使用 interface 关键字。可将接口命名为想要的任何(符合语言规则的)名称,但根据约定,接口名称要与类名称类似。
接口中定义的方法没有方法主体。接口的实现者负责提供方法主体(与抽象方法一样)。
定义接口的分层结构时也与类一样,但一个类可实现任意多个想要的接口。(请记住,一个类只能扩展一个类。)如果一个类扩展了另一个类并实现了一个或多个接口,这些接口会在扩展的类后面列出,类似这样:
public class Manager extends Employee implements BonusEligible, StockOptionRecipient { // Etc... }标记接口
接口完全不需要拥有任何主体。举例而言,完全可以接受下面的定义:
public interface BonusEligible { }一般而言,这些接口称为标记接口,因为它们将一个类标记为实现该接口,但未提供任何特殊的显式行为。
了解这一点后,实际定义接口就很轻松了:
public interface StockOptionRecipient { void processStockOptions(int numberOfOptions, BigDecimal price); }实现接口
要使用一个接口,需要实现它,这意味着要提供一个方法主体来进一步提供可履行接口契约的行为。可使用 implements 关键字来实现接口:
public class className extends superclassName implements interfaceName { // Class Body } 假设您在 Manager 类上实现 StockOptionRecipient 接口,如清单 17 所示:
清单 17. 实现一个接口
public class Manager extends Employee implements StockOptionRecipient { public Manager() { } public void processStockOptions (int numberOfOptions, BigDecimal price) { log.info("I can't believe I got " + number + " options at $" + price.toPlainString() + "!"); } } 实现该接口时,需要提供该接口上的一个或多个方法的行为。必须使用与接口上的签名相匹配的签名来实现这些方法,还需要添加 public 访问修饰符。
在 Eclipse 中生成接口
如果您确定您的一个类应该实现一个接口,Eclipse 可轻松地为您生成正确的方法签名。只需更改类签名来实现该接口。Eclipse 在该类下面添加了一条红色的波浪线,将它标记为错误,因为该类没有提供接口上的方法。单击类名,按 Ctrl + 1,Eclipse 会提供“快速修复”建议。在这些建议中,选择 Add Unimplemented Methods,Eclipse 就会生成这些方法,将它们放在源文件的底部。
抽象类可以声明它实现了一个特定的接口,但不需要您实现该接口上的所有方法。 不需要抽象类提供它们声称要实现的所有方法的实现。但是,第一个具体的类(也就是第一个可实例化的类)必须实现分层结构没有实现的所有方法。
使用接口
接口定义了一种全新的引用数据类型,在您要引用类的任何地方,可使用该类型引用接口。声明一个引用变量或从一种类型转换为另一种类型时可使用该功能,如清单 18 所示。
清单 18. 将一个新 Manager 实例赋给 StockOptionEligible 引用
package com.makotojava.intro; import java.math.BigDecimal; import org.junit.Test; public class ManagerTest { @Test public void testCalculateAndAwardStockOptions() { StockOptionEligible soe = new Manager();// perfectly valid calculateAndAwardStockOptions(soe); calculateAndAwardStockOptions(new Manager());// works too } public static void calculateAndAwardStockOptions(StockOptionEligible soe) { BigDecimal reallyCheapPrice = BigDecimal.valueOf(0.01); int numberOfOptions = 10000; soe.awardStockOptions(numberOfOptions, reallyCheapPrice); } } 如您所见,可以有效地将一个新的 Manager 实例赋给一个 StockOptionEligible 引用,以及将一个新的 Manager 实例传递给一个想要 StockOptionEligible 引用的方法。
赋值:接口
可以将来自一个类(实现了一个接口的)的引用赋给一个接口类型的变量,但要遵守一些规则。从清单 18 中可以看到,将一个 Manager 实例赋给 StockOptionEligible 变量引用是有效的。原因是 Manager 类实现了该接口。但是,以下赋值无效:
Manager m = new Manager(); StockOptionEligible soe = m; //okay Employee e = soe; // Wrong!
因为 Employee 是 Manager 的超类型,所以此代码最初看起来没有问题,但其实不然。因为 Manager 是一个特殊化的 Employee,所以它是不同的,而且在这个特定的例子中实现了一个 Employee 没有的接口。
像这样的赋值应遵守您在“继承”节中看到的赋值规则。而且与类一样,只能将一个接口引用赋给一个具有相同类型或超接口类型的变量。
嵌套类
在本节中,您将学习嵌套类,在何处以及如何使用它们。
在何处使用嵌套类
顾名思义,嵌套类是在一个类中定义的另一个类。这是一个嵌套类:
public class EnclosingClass { ... public class NestedClass { ... } } 与成员变量和方法一样,也可在任何范围内定义 Java 类,包括 public、private 或 protected。如果希望以一种面向对象的方式执行类中的内部处理,嵌套类可能很有用,但此功能仅限于需要它的类。
通常,需要一个与定义它的类紧密耦合的类时,可使用嵌套类。嵌套类能够访问包含它的类中的私有数据,但此结构会带来一些负面影响,开始使用嵌套(或内部)类时这些影响并不明显。
嵌套类中的范围
因为嵌套类具有范围,所以它受范围规则的约束。例如,只能通过该类的实例(对象)访问一个成员变量。嵌套类也是如此。
假设在 Manager 和一个名为 DirectReports 的嵌套类之间具有以下关系,后者是一个向 Manager 报告工作情况的 Employee 集合:
public class Manager extends Employee { private DirectReports directReports; public Manager() { this.directReports = new DirectReports(); } ... private class DirectReports { ... } } 就像每个 Manager 对象表示一个唯一的人一样,DirectReports 对象表示一组向经理报告工作情况的真实的人(员工)。在不同的 Manager 之间 DirectReports 是不同的。在本例中,仅在包含 DirectReports 嵌套类的 Manager 实例中引用该类是合理的,所以我将它声明为 private。
公共嵌套类
因为 DirectReports 是 private,所以只有 Manager 可创建 DirectReports 实例。但是假设您想为一个外部实体提供创建 DirectReports 实例的能力。在这种情况下,似乎可以为 DirectReports 类提供 public 范围,然后任何外部代码即可创建 DirectReports 实例,如清单 19 所示。
清单 19. 创建 DirectReports 实例:第一次尝试
public class Manager extends Employee { public Manager() { } ... public class DirectReports { ... } } // public static void main(String[] args) { Manager.DirectReports dr = new Manager.DirectReports();// This won't work! }清单 19 中的代码无法工作,而且您可能知道原因是什么。 问题(和它的解决方案)依赖于在 Manager 中定义 DirectReports 的方式,以及范围规则。
再讲讲范围规则
如果有一个 Manager 的成员变量,您会认为编译器会要求您拥有 Manager 对象的引用,然后才能引用它,对吧?DirectReports 也是如此,至少您在清单 19 中定义它时是这样。
要创建一个公共嵌套类的实例,需要使用 new 运算符的一个特殊版本。结合使用对一个外部类的封闭实例的引用,new 允许创建嵌套类的实例:
public class Manager extends Employee { public Manager() { } ... public class DirectReports { ... } } // Meanwhile, in another method somewhere... public static void main(String[] args) { Manager manager = new Manager(); Manager.DirectReports dr = manager.new DirectReports(); } 请注意封闭实例引用的语法调用:加上一个点和 new 关键字,后跟想要创建的类。
静态内部类
有时,您想创建一个(在概念上)与另一个类紧密耦合的类,但范围规则比较宽松,不需要封闭实例的引用。这时就需要静态内部类发挥作用了。一个常见的示例是实现一个 Comparator,用于比较同一个类的两个实例,通常用于对类进行排序(或分类):
public class Manager extends Employee { ... public static class ManagerComparator implements Comparator<Manager> { ... } } // Meanwhile, in another method somewhere... public static void main(String[] args) { Manager.ManagerComparator mc = new Manager.ManagerComparator(); ... } 在本例中,您不需要封闭实例。静态内部类的行为与它们的对应常规 Java 类类似,而且仅在需要将一个类与它的定义紧密耦合时才使用静态内部类。显然,对于像 ManagerComparator 这样的实用程序类,创建外部类没有必要,而且可能让代码库变的很乱。将这些类定义为静态内部类是一种解决办法。
匿名内部类
使用 Java 语言时,您可在任何地方声明类,如有必要,甚至可在一个方法内声明,而且甚至无需为类提供名称。此功能基本来讲是一种编译器窍门,但有时拥有匿名内部类很方便。
清单 20 构建于清单 17 中的示例之上,添加了一个默认方法来处理不属于 StockOptionEligible 的 Employee 类型。该清单首先显示 HumanResourcesApplication 中一个处理库存选项的方法,然后是一个驱动该方法的 JUnit 测试:
清单 20. 处理不属于 StockOptionEligible 的 Employee 类型
// From HumanResourcesApplication.java public void handleStockOptions(final Person person, StockOptionProcessingCallback callback) { if (person instanceof StockOptionEligible) { // Eligible Person, invoke the callback straight up callback.process((StockOptionEligible)person); } else if (person instanceof Employee) { // Not eligible, but still an Employee.Let's cobble up a /// anonymous inner class implementation for this callback.process(new StockOptionEligible() { @Override public void awardStockOptions(int number, BigDecimal price) { // This employee is not eligible log.warning("It would be nice to award " + number + " of shares at $" + price.setScale(2, RoundingMode.HALF_UP).toPlainString() + ", but unfortunately, Employee " + person.getName() + " is not eligible for Stock Options!"); } }); } else { callback.process(new StockOptionEligible() { @Override public void awardStockOptions(int number, BigDecimal price) { log.severe("Cannot consider awarding " + number + " of shares at $" + price.setScale(2, RoundingMode.HALF_UP).toPlainString() + ", because " + person.getName() + " does not even work here!"); } }); } } // JUnit test to drive it (in HumanResourcesApplicationTest.java): @Test public void testHandleStockOptions() { List<Person> people = HumanResourcesApplication.createPeople(); StockOptionProcessingCallback callback = new StockOptionProcessingCallback() { @Override public void process(StockOptionEligible stockOptionEligible) { BigDecimal reallyCheapPrice = BigDecimal.valueOf(0.01); int numberOfOptions = 10000; stockOptionEligible.awardStockOptions(numberOfOptions, reallyCheapPrice); } }; for (Person person : people) { classUnderTest.handleStockOptions(person, callback); } } 在这个示例中,我提供了两个使用匿名内部类的接口实现。首先是 StockOptionEligible 的两个不同实现 — 一个用于 Employee,另一个用于 Person(以便符合接口要求)。然后是一个 StockOptionProcessingCallback 实现,用于处理 Manager 实例的库存选项。
需要一定的时间才能掌握匿名内部类,但它们使用起来非常方便。我一直在 Java 代码中使用它们。而且随着您作为 Java 开发人员不断进步,我相信您也会这么做。
正则表达式
正则表达式基本来讲是一种模式,描述一组具有该共同模式的字符串。如果您是 Perl 程序员,应该非常熟悉 Java 语言中的正则表达式 (regex) 模式语法。但是,如果您不习惯使用正则表达式语法,它可能看起来很怪异。本节指导您在 Java 程序中使用正则表达式。
Regular Expressions API
下面是一组具有某些共性的字符串:
- A string
- A longer string
- A much longer string
请注意,这些字符串中的每一个都以 a 开头,以 string 结尾。Java Regular Expressions API 可帮助您将这些元素提取出来,查看它们之间的模式,然后使用已收集的信息做有趣的工作。
Regular Expressions API 有 3 个您几乎总是在使用的核心类:
Pattern描述一种字符串模式。Matcher测试一个字符串,查看它是否与模式匹配。PatternSyntaxException告诉您,无法接受您尝试定义的模式的某个方面。
很快您就会开始使用简单的正则表达式模式,该模式使用了这些类。但是在这么做之前,看看 regex 模式语法。
regex 模式语法
regex 模式描述字符串的结构,表达式会尝试在输入字符串中查找该结构。这是正则表达式可能看起来有点奇怪的地方。但是,一旦您理解了该语法,就可以更轻松地解释它。表 2 列出了在模式字符串中使用的一些最常见的 regex 构造:
表 2. 常见 regex 构造
| Regex 构造 | 符合匹配条件的内容 |
|---|---|
| . | 任何字符 |
? | 前面的零 (0) 或一 (1) 个字符或数字 |
* | 前面的零 (0) 或更多个字符或数字 |
+ | 前面的一 (1) 或更多个字符或数字 |
[] | 一个字符或数字范围 |
^ | 后面的条件的否定(即“非后面的条件”) |
/d | 任何数字(也可表示为 [0-9]) |
/D | 任何非数字(也可表示为 [^0-9]) |
/s | 任何空格字符(也可表示为 [/n/t/f/r]) |
/S | 任何非空格字符(也可表示为 [^/n/t/f/r]) |
/w | 任何单词字符(也可表示为 [a-zA-Z_0-9]) |
/W | 任何非单词字符(也可表示为 [^/w]) |
前几种构造称为量词,因为它们对之前的内容进行量化。/d 等构造是预定义的字符类。任何在一种模式中没有特殊含义的字符都是文字并与自身匹配。
模式匹配
掌握表 2 中的模式语法后,就能理解清单 21 中的简单示例了,这个示例使用了 Java Regular Expressions API 中的类。
清单 21. 使用 regex 进行模式匹配
Pattern pattern = Pattern.compile("a.*string"); Matcher matcher = pattern.matcher("a string"); boolean didMatch = matcher.matches(); Logger.getAnonymousLogger().info (didMatch); int patternStartIndex = matcher.start(); Logger.getAnonymousLogger().info (patternStartIndex); int patternEndIndex = matcher.end(); Logger.getAnonymousLogger().info (patternEndIndex); 首先,清单 21 调用 compile()(Pattern 上的一个静态方法)来创建一个 Pattern 类,并使用一个字符串文字来表示想要匹配的模式。该文字使用了 regex 模式语法。在本例中,该模式的中文翻译为:
找到一个具有以下形式的字符串:a 后跟零或更多个字符,然后是 string。
匹配方法
接下来,清单 21 在 Pattern 上调用 matcher()。该调用创建一个 Matcher 实例。 然后 Matcher 搜索您传入的字符串,寻找与您在创建 Pattern 时使用的模式字符串相匹配的结果。
每个 Java 语言字符串都是一个带索引的字符集合,索引从 0 开始,到字符串长度减 1 结束。Matcher 从 0 开始解析该字符串,寻找与它匹配的结果。处理完成后,Matcher 包含有关在输入字符串中找到(或未找到)匹配结果的信息。可在 Matcher 上调用各种方法来访问该信息:
matches()告诉您整个输入序列是否与该模式准确匹配。start()告诉您匹配的字符串在输入字符串中开始处的索引值。end()告诉您匹配的字符串在输入字符串中结束处的索引值加 1 的结果。
清单 21 找到了一个从 0 开始,到 7 结束的匹配结果。因此,调用 matches() 会返回 true,调用 start() 会返回 0,调用 end() 会返回 8。
lookingAt() 与 matches()
如果字符串中的元素比搜索模式中的字符要多,可使用 lookingAt() 代替 matches()。lookingAt() 搜索与给定模式匹配的子字符串。例如,考虑下面这个字符串:
Here is a string with more than just the pattern.
您可在此字符串中搜索 a.*string,而且如果使用 lookingAt(),就会获得一个匹配结果。但是如果使用 matches(),就会返回 false,因为字符串中包含的内容比模式中的多。
regex 中的复杂模式
可使用 regex 类轻松完成简单的搜索,同时也可使用 Regular Expressions API 执行非常复杂的操作。
Wiki(允许用户修改页面的、基于 Web 的系统)几乎完全基于正则表达式。Wiki 内容基于用户的字符串输入,并且使用正则表达式来解析和格式化该输入。 任何用户都可输入一个 wiki 词组,从而在 wiki 中创建另一个主题的链接,这个词组通常是一系列串联的单词,每个单词以一个大写字母开头,类似这样:
MyWikiWord
假设一个用户输入下面这个字符串:
Here is a WikiWord followed by AnotherWikiWord, then YetAnotherWikiWord.
您可使用 regex 模式在这个字符串中搜索 wiki 单词,类似这样:
[A-Z][a-z]*([A-Z][a-z]*)+
下面是搜索 wiki 单词的代码:
String input = "Here is a WikiWord followed by AnotherWikiWord, then SomeWikiWord."; Pattern pattern = Pattern.compile("[A-Z][a-z]*([A-Z][a-z]*)+"); Matcher matcher = pattern.matcher(input); while (matcher.find()) { Logger.getAnonymousLogger().info("Found this wiki word:" + matcher.group()); }运行此代码,应在控制台中看到 3 个 wiki 单词。
替换字符串
搜索匹配内容很有用,但也可在找到匹配字符串后操作它们。您可将匹配的字符串替换为其他字符串,就像在文字处理程序中搜索一些文本并将它替换为其他文本一样。 Matcher 有两个替换字符串元素的方法:
replaceAll()将所有匹配值替换为一个指定的字符串。replaceFirst()仅将第一个匹配值替换为一个指定的字符串。
使用 Matcher 的 replace 方法很简单:
String input = "Here is a WikiWord followed by AnotherWikiWord, then SomeWikiWord."; Pattern pattern = Pattern.compile("[A-Z][a-z]*([A-Z][a-z]*)+"); Matcher matcher = pattern.matcher(input); Logger.getAnonymousLogger().info("Before:" + input); String result = matcher.replaceAll("replacement"); Logger.getAnonymousLogger().info("After:" + result); 与之前一样,此代码会查找 wiki 单词。Matcher 找到一个匹配值时,它会将该 wiki 单词文本替换为相应的替换值。运行该代码时,可在控制台上看到以下消息:
Before:Here is WikiWord followed by AnotherWikiWord, then SomeWikiWord. After:Here is replacement followed by replacement, then replacement.
如果使用 replaceFirst(),则会看到此消息:
Before:Here is a WikiWord followed by AnotherWikiWord, then SomeWikiWord. After:Here is a replacement followed by AnotherWikiWord, then SomeWikiWord.
匹配和操作分组
搜索一个 regex 模式的匹配结果时,可获得有关找到的结果的信息。您已在 Matcher 的 start() 和 end() 方法上看到过该功能。但也可以通过捕获分组来引用匹配值。
在每种模式中,通常通过将模式的各部分放在圆括号中来创建分组。分组从左向右编号,从 1 开始编号(分组 0 表示完整的匹配结果)。清单 22 中的代码将每个 wiki 单词替换为一个“包含”该单词的字符串:
清单 22. 匹配分组
String input = "Here is a WikiWord followed by AnotherWikiWord, then SomeWikiWord."; Pattern pattern = Pattern.compile("[A-Z][a-z]*([A-Z][a-z]*)+"); Matcher matcher = pattern.matcher(input); Logger.getAnonymousLogger().info("Before:" + input); String result = matcher.replaceAll("blah$0blah"); Logger.getAnonymousLogger().info("After:" + result);运行清单 22 代码,应获得以下控制台输出:
Before:Here is a WikiWord followed by AnotherWikiWord, then SomeWikiWord. After:Here is a blahWikiWordblah followed by blahAnotherWikiWordblah, then blahSomeWikiWordblah.
另一种匹配分组的方法
清单 22 通过在替换字符串中包含 $0 来引用整个匹配结果。$ int 格式的替换字符串的任何部分引用该整数所标识的分组(所以 $1 引用分组 1,依此类推)。换句话说,$0 等效于 matcher.group(0);。
也可使用其他方法实现同样的替换目标。无需调用 replaceAll(),可以这样做:
StringBuffer buffer = new StringBuffer(); while (matcher.find()) { matcher.appendReplacement(buffer, "blah$0blah"); } matcher.appendTail(buffer); Logger.getAnonymousLogger().info("After:" + buffer.toString());也会获得同样的结果:
Before:Here is a WikiWord followed by AnotherWikiWord, then SomeWikiWord. After:Here is a blahWikiWordblah followed by blahAnotherWikiWordblah, then blahSomeWikiWordblah.
泛型
JDK 5 中引入的泛型标志着 Java 语言的一次巨大进步。如果使用过 C++ 模板,会发现 Java 语言中的泛型与其很相似,但并非完全相同。如果未使用过 C++ 模板,不要担心:本节将概括介绍 Java 语言中的泛型。
什么是泛型?
随着 JDK 5 的发布,Java 语言中突然出现了陌生且令人兴奋的新语法。基本来讲,一些熟悉的 JDK 类被替换为了等效的泛型。
泛型是一种编译器机制,您可获取通用的代码并参数化(或模板化)剩余部分,从而以一种一般化的方式创建(和使用)一些实体类型(比如类或接口)。
泛型实战
要了解泛型有何作用,可考虑一个在 JDK 中存在已久的类示例: java.util.ArrayList,它是一个由数组支持的 Object 的 List。
清单 23 展示了如何实例化 java.util.ArrayList。
清单 23. 实例化 ArrayList
ArrayList arrayList = new ArrayList(); arrayList.add("A String"); arrayList.add(new Integer(10)); arrayList.add("Another String"); // So far, so good. 可以看到,ArrayList 具有不同的形式:它包含两个 String 类型和一个 Integer 类型。在 JDK 5 之前,Java 语言对此行为没有任何约束,这导致了许多编码错误。举例而言,在清单 23 中,目前为止看起来一切正常。但要访问 ArrayList 中的元素怎么办,清单 24 尝试采用哪种方法?
清单 24. 尝试访问 ArrayList 中的元素
ArrayList arrayList = new ArrayList(); arrayList.add("A String"); arrayList.add(new Integer(10)); arrayList.add("Another String"); // So far, so good. *processArrayList(arrayList); *// In some later part of the code... private void processArrayList(ArrayList theList) { for (int aa = 0; aa < theList.size(); aa++) { // At some point, this will fail... String s = (String)theList.get(aa); } } 如果以前不知道 ArrayList 中包含的内容,就必须检查要访问的元素,看看您是否能处理其类型,否则可能遇到 ClassCastException。
借助泛型,可指定将哪些类型的内容放入 ArrayList。清单 25 展示了如何执行该操作。
清单 25. 第二次尝试使用泛型
ArrayList<String> arrayList = new ArrayList<>(); arrayList.add("A String"); arrayList.add(new Integer(10));// compiler error! arrayList.add("Another String"); // So far, so good. *processArrayList(arrayList); *// In some later part of the code... private void processArrayList(ArrayList<String> theList) { for (int aa = 0; aa < theList.size(); aa++) { // No cast necessary... String s = theList.get(aa); } }迭代泛型
通过用特殊的语法来处理您常常希望逐个元素处理的实体(比如 List),泛型让 Java 语言变得更强大。举例而言,如果想迭代 ArrayList,可将清单 25 中的代码重写为:
private void processArrayList(ArrayList<String> theList) { for (String s : theList) { String s = theList.get(aa); } } 此语法适用于任何 Iterable(也就是实现了 Iterable 接口)的对象类型。
参数化的类
参数化的类对于集合非常有用,所以使用集合时可考虑使用这种类。考虑(真实的)List 接口,它表示一个有序的对象集合。在最常见的用例中,您向 List 中添加项,然后按索引或通过迭代 List 来访问这些项。
如果考虑参数化一个类,可考虑是否满足以下条件:
- 一个核心类位于某种包装器的中心。也就是位于类中心的“东西”可能应用很广泛,并且其特性(例如属性)是相同的。
- 相同的行为:无论类中心的“事务”是什么,您都会执行完全相同的操作。
根据这两个条件,显然集合满足要求:
- 这个“事务”就是组成集合的类。
- 操作(比如
add、remove、size和clear)完全相同,无论集合由哪些对象组成都是如此。
一个参数化的 List
在泛型语法中,创建 List 的代码类似于:
List<E> listReference = new concreteListClass<E>();
E(代表元素)是我之前提到的“事务”。concreteListClass 是您正在实例化的 JDK 的类。该 JDK 包含多个 List<E> 实现,但您使用 ArrayList<E>。您可能看到的泛型类的另一种形式为 Class<T>,其中 T 代表类型。在 Java 代码中看到 E 时,它通常是指一个某种类型的集合。看到 T 时,它表示一个参数化的类。
所以,要创建一个由 java.lang.Integer 组成的 ArrayList,可以这么做:
List<Integer> listOfIntegers = new ArrayList<Integer>();
SimpleList:一个参数化的类
现在假设您想创建自己的参数化类 SimpleList,该类包含 3 个方法:
add()将一个元素添加到SimpleList的末尾。size()返回SimpleList中当前的元素数量。clear()完全清除SimpleList的内容。
清单 26 给出了参数化 SimpleList 的语法:
清单 26. 参数化 SimpleList
package com.makotojava.intro; import java.util.ArrayList; import java.util.List; public class SimpleList<E> { private List<E> backingStore; public SimpleList() { backingStore = new ArrayList<E>(); } public E add(E e) { if (backingStore.add(e)) return e; else return null; } public int size() { return backingStore.size(); } public void clear() { backingStore.clear(); } }可使用任何 Object 子类来参数化 SimpleList。要创建并使用一个由 java.math.BigDecimal 对象组成的 SimpleList,可以这样做:
package com.makotojava.intro; import java.math.BigDecimal; import java.util.logging.Logger; import org.junit.Test; public class SimpleListTest { @Test public void testAdd() { Logger log = Logger.getLogger(SimpleListTest.class.getName()); SimpleList<BigDecimal> sl = new SimpleList<>(); sl.add(BigDecimal.ONE); log.info("SimpleList size is :" + sl.size()); sl.add(BigDecimal.ZERO); log.info("SimpleList size is :" + sl.size()); sl.clear(); log.info("SimpleList size is :" + sl.size()); } }而且会得到此输出:
Sep 20, 2015 10:24:33 AM com.makotojava.intro.SimpleListTest testAdd INFO:SimpleList size is:1 Sep 20, 2015 10:24:33 AM com.makotojava.intro.SimpleListTest testAdd INFO:SimpleList size is:2 Sep 20, 2015 10:24:33 AM com.makotojava.intro.SimpleListTest testAdd INFO:SimpleList size is:0
enum 类型
在 JDK 5 中,Java 语言新添了一种名为 enum 的数据类型。不要与 java.util.Enumeration 混淆,enum 表示一组与某个特定概念相关的常量对象,每个对象表示该集合中一个不同的常量值。将 enum 引入 Java 语言之前,必须按如下方式为一个概念(比如性别)定义一组常量值:
public class Person { public static final String MALE = "male"; public static final String FEMALE = "female"; }引用该常量值所需的代码可以像这样编写:
public void myMethod() { //... String genderMale = Person.MALE; //... }使用 enum 定义常量
使用 enum 类型让常量的定义更加正式,而且更强大。这是 Gender 的 enum 定义:
public enum Gender { MALE, FEMALE } 此示例仅简单介绍了 enum 用途的一点皮毛。事实上,enum 非常像类,所以它们可拥有构造函数、属性和方法:
package com.makotojava.intro; public enum Gender { MALE("male"), FEMALE("female"); private String displayName; private Gender(String displayName) { this.displayName = displayName; } public String getDisplayName() { return this.displayName; } } 类与 enum 的一个区别在于,enum 的构造函数必须声明为 private,而且它无法扩展(或继承自)其他 enum。但是,一个 enum可实现一个接口。
enum 实现一个接口
假设您定义了一个接口 Displayable:
package com.makotojava.intro; public interface Displayable { public String getDisplayName(); }Gender enum 可像这样实现这个接口(以及生成一个友好显式名称所需的其他任何 enum):
package com.makotojava.intro; public enum Gender implements Displayable { MALE("male"), FEMALE("female"); private String displayName; private Gender(String displayName) { this.displayName = displayName; } @Override public String getDisplayName() { return this.displayName; } }I/O
本节将概述 java.io 包。您将学习如何使用它的一些工具来收集和操作各种不同来源的数据。
处理外部数据
在 Java 程序中使用的数据常常来自外部数据源,比如数据库、通过套接字进行的直接字节传输或文件存储。Java 语言提供了许多工具从这些来源获取信息,其中大部分工具都位于 java.io 包中。
文件
在所有 Java 应用程序可用的数据源中,文件是最常见的,常常也是最方便的。如果想在 Java 应用程序中读取一个文件,必须使用流将传入的字节解析为 Java 语言类型。
java.io.File 是一个类,它在您的文件系统上定义资源并以一种抽象的方式表示该资源。创建 File 对象很容易:
File f = new File("temp.txt"); File f2 = new File("/home/steve/testFile.txt");File 构造函数接受它所创建的文件的名称。第一个调用在指定的目录中创建一个名为 temp.txt 的文件。第二个调用在我的 Linux 系统上的具体位置创建一个文件。您可将任何 String 传递至 File 的构造函数,只要文件名对 OS 而言是有效的,无论它引用的文件是否存在都是如此。
此代码向新创建的 File 对象询问该文件是否存在:
File f2 = new File("/home/steve/testFile.txt"); if (f2.exists()) { // File exists.Process it... } else { // File doesn't exist.Create it... f2.createNewFile(); }java.io.File 拥有其他方便的方法来删除文件;创建目录(通过将一个目录名称作为参数传递至 File 的构造函数);确定一个资源是文件、目录还是符号链接;等等。
Java I/O 的实际操作是写入和读取数据源,这时就需要使用流。
在 Java I/O 中使用流
可以使用流来访问文件系统上的文件。在最低限度上,流允许程序从来源接收字节或将输出发送至目标。一些流可处理所有类型的 16 位字符(Reader 和 Writer 类型)。其他流只能处理 8 位字节(InputStream 和 OutputStream 类型)。这些分层结构中包含多种风格的流,它们都可在 java.io 包中找到。在最高的抽象级别上是字符流和字节流。
字节流读(InputStream 和子类)和写(OutputStream 和子类)8 位字节。换句话说,可将字节流看作一种更加原始的流类型。下面总结了两种常见的字节流及其用法:
- FileInputStream / FileOutputStream: 从文件读取字节,将字节写入文件
- ByteArrayInputStream / ByteArrayOutputStream:从内存型数组读取字节,将字节写入内存型数组
字符流
字符流读(Reader 和它的子类)和写(Writer 和它的子类)16 位字符。下面是一个字符流清单及其用法:
StringReader/StringWriter:在内存中的String中读取以及向其中写入字符。InputStreamReader/InputStreamWriter(和子类FileReader/FileWriter):衔接字节流和字符流:Reader喜欢从字节流读取字节并将其转换为字符。Writer喜欢将字符转换为字节,从而将它们放在字节流上。- BufferedReader / BufferedWriter: 在读取或写入另一个流时缓冲数据,使读写操作更高效。
我不会介绍所有流,而是主要介绍读写文件时推荐使用的流。在大多数情况下,这些都是字符流。
从 File 读取数据
可通过多种方式从 File 读取数据。无疑最简单的方法是:
- 在想要从中读取数据的
File上创建一个InputStreamReader。 - 调用
read()可一次读取一个字符,直至到达文件末尾。
清单 27 是一个从 File 读取数据的示例:
清单 27. 从 File 读取数据
public List<Employee> readFromDisk(String filename) { final String METHOD_NAME = "readFromDisk(String filename)"; List<Employee> ret = new ArrayList<>(); File file = new File(filename); try (InputStreamReader reader = new InputStreamReader(new FileInputStream(file))) { StringBuilder sb = new StringBuilder(); int numberOfEmployees = 0; int character = reader.read(); while (character != -1) { sb.append((char)character); character = reader.read(); } log.info("Read file:/n" + sb.toString()); int index = 0; while (index < sb.length()-1) { StringBuilder line = new StringBuilder(); while ((char)sb.charAt(index) != '/n') { line.append(sb.charAt(index++)); } StringTokenizer strtok = new StringTokenizer(line.toString(), Person.STATE_DELIMITER); Employee employee = new Employee(); employee.setState(strtok); log.info("Read Employee:" + employee.toString()); ret.add(employee); numberOfEmployees++; index++; } log.info("Read " + numberOfEmployees + " employees from disk."); } catch (FileNotFoundException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "Cannot find file " + file.getName() + ", message = " + e.getLocalizedMessage(), e); } catch (IOException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "IOException occurred, message = " + e.getLocalizedMessage(), e); } return ret; }写入 File
与从 File 读取一样,可通过多种方式将数据写入 File。我会再次介绍一下最简单的方法:
- 在想要写入数据的
File上创建一个FileOutputStream。 - 调用
write()写入字符序列。
清单 28 是一个将数据写入 File 的示例:
清单 28. 写入 File
public boolean saveToDisk(String filename, List<Employee> employees) { final String METHOD_NAME = "saveToDisk(String filename, List<Employee> employees)"; boolean ret = false; File file = new File(filename); try (OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(file))) { log.info("Writing " + employees.size() + " employees to disk (as String)..."); for (Employee employee : employees) { writer.write(employee.getState()+"/n"); } ret = true; log.info("Done."); } catch (FileNotFoundException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "Cannot find file " + file.getName() + ", message = " + e.getLocalizedMessage(), e); } catch (IOException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "IOException occurred, message = " + e.getLocalizedMessage(), e); } return ret; }缓冲流
逐个字符地读和写字符流并不是高效的,所以在大部分情况下,您可能希望使用缓冲的 I/O。要使用缓冲的 I/O 从文件读取数据,代码与清单 27 中所示的类似,但要将 InputStreamReader 包装在一个 BufferedReader 中,如清单 29 所示。
清单 29. 使用缓冲的 I/O 从 File 读取数据
public List<Employee> readFromDiskBuffered(String filename) { final String METHOD_NAME = "readFromDisk(String filename)"; List<Employee> ret = new ArrayList<>(); File file = new File(filename); try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file)))) { String line = reader.readLine(); int numberOfEmployees = 0; while (line != null) { StringTokenizer strtok = new StringTokenizer(line, Person.STATE_DELIMITER); Employee employee = new Employee(); employee.setState(strtok); log.info("Read Employee:" + employee.toString()); ret.add(employee); numberOfEmployees++; // Read next line line = reader.readLine(); } log.info("Read " + numberOfEmployees + " employees from disk."); } catch (FileNotFoundException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "Cannot find file " + file.getName() + ", message = " + e.getLocalizedMessage(), e); } catch (IOException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "IOException occurred, message = " + e.getLocalizedMessage(), e); } return ret; } 使用缓冲的 I/O 将数据写入文件的过程相同:将 OutputStreamWriter 包装在一个 BufferedWriter 中,如清单 30 所示。
清单 30. 使用缓冲的 I/O 将数据写入 File
public boolean saveToDiskBuffered(String filename, List<Employee> employees) { final String METHOD_NAME = "saveToDisk(String filename, List<Employee> employees)"; boolean ret = false; File file = new File(filename); try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file)))) { log.info("Writing " + employees.size() + " employees to disk (as String)..."); for (Employee employee : employees) { writer.write(employee.getState()+"/n"); } ret = true; log.info("Done."); } catch (FileNotFoundException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "Cannot find file " + file.getName() + ", message = " + e.getLocalizedMessage(), e); } catch (IOException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "IOException occurred, message = " + e.getLocalizedMessage(), e); } return ret; }我仅简单介绍了这个基础 Java 库大量用途的一点皮毛。您可自行将所学的相关文件知识应用到其他数据源。
Java 序列化
Java 序列化是 Java 平台的另一个基础库。 序列化主要用于对象持久化和对象远程传输,在这两种用例中,都需要能够获取对象状态的快照,这样在以后能重新构成它们。本节大体介绍 Java Serialization API,展示如何在程序中使用它。
什么是对象序列化?
在序列化过程中,会以一种特殊的二进制格式存储一个对象及其元数据(比如对象的类名称及其属性名称)的状态。将对象存储为此格式 —序列化它 — 可保留在需要时重新构成(或反序列化)该对象所必需的全部信息。
对象序列化有两种主要用例:
- 对象持久化— 将对象的状态存储在一种永久的持久性机制中,比如数据库
- 对象远程传输— 将对象发送至另一个计算机或系统
java.io.Serializable
实现序列化的第一步是让对象能够使用该机制。希望能够序列化的每个对象都必须实现一个名为 java.io.Serializable 的接口:
import java.io.Serializable; public class Person implements Serializable { // etc... }Serializable 接口将 Person 类 — 和 Person 的每个子类 — 向运行时标记为 serializable。
如果 Java 运行时尝试序列化对象,无法序列化的对象的每个属性都会导致运行时抛出 NotSerializableException。可使用 transient 关键字来管理此行为,告诉运行时不要尝试序列化某些属性。在此情况下,您要负责确保这些属性能被恢复,以便对象能正常运行。
序列化一个对象
现在我们通过一个示例,尝试将刚学到的 Java I/O 知识与现在学习的序列化知识结合起来。
假设您创建并填充一个包含 Employee 对象的 List,然后希望将该 List 序列化为一个 OutputStream,在本例中是序列化为一个文件。 该过程如清单 31 所示。
清单 31. 序列化一个对象
public class HumanResourcesApplication { private static final Logger log = Logger.getLogger(HumanResourcesApplication.class.getName()); private static final String SOURCE_CLASS = HumanResourcesApplication.class.getName(); public static List<Employee> createEmployees() { List<Employee> ret = new ArrayList<Employee>(); Employee e = new Employee("Jon Smith", 45, 175, 75, "BLUE", Gender.MALE, "123-45-9999", "0001", BigDecimal.valueOf(100000.0)); ret.add(e); // e = new Employee("Jon Jones", 40, 185, 85, "BROWN", Gender.MALE, "223-45-9999", "0002", BigDecimal.valueOf(110000.0)); ret.add(e); // e = new Employee("Mary Smith", 35, 155, 55, "GREEN", Gender.FEMALE, "323-45-9999", "0003", BigDecimal.valueOf(120000.0)); ret.add(e); // e = new Employee("Chris Johnson", 38, 165, 65, "HAZEL", Gender.UNKNOWN, "423-45-9999", "0004", BigDecimal.valueOf(90000.0)); ret.add(e); // Return list of Employees return ret; } public boolean serializeToDisk(String filename, List<Employee> employees) { final String METHOD_NAME = "serializeToDisk(String filename, List<Employee> employees)"; boolean ret = false;// default: failed File file = new File(filename); try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream(file))) { log.info("Writing " + employees.size() + " employees to disk (using Serializable)..."); outputStream.writeObject(employees); ret = true; log.info("Done."); } catch (IOException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "Cannot find file " + file.getName() + ", message = " + e.getLocalizedMessage(), e); } return ret; } 第一步是创建这些对象,在 createEmployees() 中使用 Employee 的特殊化构造函数和一些属性值来完成该工作。接下来创建一个 OutputStream(在本例中为 FileOutputStream),然后在该流上调用 writeObject()。 writeObject() 是一个方法,它使用 Java 序列化将一个对象序列化为流。
在此示例中,您将 List 对象(以及它包含的 Employee 对象)存储在一个文件中,但同样的技术可用于任何类型的序列化。
要成功运行清单 31 中的代码,可使用 JUnit 测试,如下所示(来自 HumanResourcesApplicationTest.java):
public class HumanResourcesApplicationTest { private HumanResourcesApplication classUnderTest; private List<Employee> testData; @Before public void setUp() { classUnderTest = new HumanResourcesApplication(); testData = HumanResourcesApplication.createEmployees(); } @Test public void testSerializeToDisk() { String filename = "employees-Junit-" + System.currentTimeMillis() + ".ser"; boolean status = classUnderTest.serializeToDisk(filename, testData); assertTrue(status); } }反序列化对象
序列化对象的唯一目的就是为了能够重新构成或反序列化它。清单 32 读取刚序列化的文件并对其内容反序列化,然后恢复 Employee 对象的 List 的状态。
清单 32. 反序列化对象
public class HumanResourcesApplication { private static final Logger log = Logger.getLogger(HumanResourcesApplication.class.getName()); private static final String SOURCE_CLASS = HumanResourcesApplication.class.getName(); @SuppressWarnings("unchecked") public List<Employee> deserializeFromDisk(String filename) { final String METHOD_NAME = "deserializeFromDisk(String filename)"; List<Employee> ret = new ArrayList<>(); File file = new File(filename); int numberOfEmployees = 0; try (ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream(file))) { List<Employee> employees = (List<Employee>)inputStream.readObject(); log.info("Deserialized List says it contains " + employees.size() + " objects..."); for (Employee employee : employees) { log.info("Read Employee:" + employee.toString()); numberOfEmployees++; } ret = employees; log.info("Read " + numberOfEmployees + " employees from disk."); } catch (FileNotFoundException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "Cannot find file " + file.getName() + ", message = " + e.getLocalizedMessage(), e); } catch (IOException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "IOException occurred, message = " + e.getLocalizedMessage(), e); } catch (ClassNotFoundException e) { log.logp(Level.SEVERE, SOURCE_CLASS, METHOD_NAME, "ClassNotFoundException, message = " + e.getLocalizedMessage(), e); } return ret; } }同样,要想成功运行清单 32 中的代码,可使用一个类似这样的 JUnit 测试(来自 HumanResourcesApplicationTest.java):
public class HumanResourcesApplicationTest { private HumanResourcesApplication classUnderTest; private List<Employee> testData; @Before public void setUp() { classUnderTest = new HumanResourcesApplication(); } @Test public void testDeserializeFromDisk() { String filename = "employees-Junit-" + System.currentTimeMillis() + ".ser"; int expectedNumberOfObjects = testData.size(); classUnderTest.serializeToDisk(filename, testData); List<Employee> employees = classUnderTest.deserializeFromDisk(filename); assertEquals(expectedNumberOfObjects, employees.size()); } } 对于大多数应用程序的用途,将对象标记为 serializable 是执行序列化工作时唯一需要担心的问题。需要明确地序列化和反序列化对象时,可使用清单 31 和清单 32 中所示的技术。但是,随着应用程序对象不断演变,以及在它们之中添加和删除属性,序列化会变得更加复杂。
serialVersionUID
回想中间件和远程对象通信的发展初期,开发人员主要负责控制其对象的“连接格式”,随着技术开始演变,这引发了大量头疼的问题。
假设您向一个对象添加了一个属性,重新编译了它,然后将该代码重新分发到一个应用程序集群中的每个计算机上。该对象存储在一个具有某种代码版本的计算机中,但其他可能具有不同代码版本的计算机访问该对象。这些计算机尝试反序列化该对象时,常常会发生糟糕的事情。
Java 序列化元数据 — 所包含的二进制序列化格式的信息 — 很复杂,而且解决了困扰早期中间件开发人员的许多问题。但它并非能解决所有问题。
Java 序列化使用一个名为 serialVersionUID 的特性来帮助您处理序列化场景中的不同对象版本问题。不需要在对象上声明此特性;默认情况下,Java 平台会使用一种算法并根据类的属性、它的类名称以及在庞大的本地集群中的位置来计算值。在大多数情况下,该算法都能正常运行。但是,如果添加或删除一个属性,这个动态生成的值就会发生变化,而且 Java 运行时会抛出 InvalidClassException。
要想避免这种情况,可养成明确声明 serialVersionUID 的习惯:
import java.io.Serializable; public class Person implements Serializable { private static final long serialVersionUID = 20100515; // etc... } 我建议您为 serialVersionUID 版本号使用某种模式(我在前面的示例中使用了当前日期)。而且应将 serialVersionUID 声明为 private static final 和 long 类型。
您可能想知道何时应更改此特性。简单的答案是,只要对类执行了不兼容的更改(这通常意味着删除了一个属性),就应该更改它。如果在一台计算机上拥有该对象的一个已删除了某个属性的版本,而且将该对象远程传输至一台计算机,其中包含的对象版本需要该属性,此时就会发生怪异的事情。这时就可以使用 Java 平台的内置 serialVersionUID 进行检查。
作为一条经验规则,任何时候添加或删除一个类特性(也就是属性和方法),都需要更改它的 serialVersionUID。在连接的另一端获得一个 InvalidClassException,比由不兼容的类更改导致应用程序错误要更好一些。
第 2 部分的小结
Java 编程简介教程介绍了 Java 语言的大量知识,但该语言博大精深。一部教程无法涵盖所有内容。
随着您继续学习 Java 语言和平台,您可能希望进一步研究正则表达式、泛型和 Java 序列化等主题。最终,您可能还想探索这部介绍性教程中未涵盖的主题,如并发性和持久化。参见参考资料,可以了解有关学习 Java 编程概念的一些入门知识,包括太高级而无法在本介绍性教程中探讨的概念。
正文到此结束
- 本文标签: 需求 解析 final 删除 ORM linux 测试 https 配置 代码 HTML 开发 http message 中文翻译 struct 安装 API 程序员 参数 src Logging 翻译 ip 集群 管理 App 软件 build 2015 编译 eclipse cat IDE CTO list schema 下载 web db 数据库 CEO value 工资 招聘 java windows Oracle 数据 空间 XML Developer ACE 目录 IBM find 调试 时间 实例 总结 Word 自动生成 正则表达式 tab tar UI
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

