使用 Spark Streaming 检测关键词
许多公司使用 Apache Hadoop 等分布式文件系统来存储和分析数据。借助脱机 Hadoop 的流式传输分析,您可存储大量的大数据并实时分析它们。本文展示了一个使用 Spark Streaming 实现实时关键词检测的例子。
Spark Streaming 是 Spark API 的一个扩展,它支持对实时数据流执行可扩展的、容错的处理。Spark Streaming 拥有丰富的适配器,允许应用程序开发人员对各种数据源读写数据,包括 Hadoop 分布式文件系统 (HDFS)、Kafka、Twitter 等。
前提条件
- 必备软件:IBM InfoSphere® BigInsights 4.0 或更高版本和 Apache Maven。
- 必备知识:中级 Java™ 开发技能,初步了解 Hadoop 和 Spark。
解决方案概述
Spark Streaming 应用程序由一个或多个互联的、离散化的流 (DStream) 组成。每个 DStream 由一系列弹性分布式数据集 (RDD,Resilient Distributed Dataset) 组成,这些数据集是不可变的分布式数据集的抽象。Spark 支持不同的应用程序开发语言,包括 Java、Scala 和 Python。对于本文,我们将使用 Java 语言逐步展示如何开发关键词检测应用程序。
图 1 显示了这个关键词检测应用程序的总体视图。
什么是弹性分布式数据集 (RDD)?
弹性分布式数据集 (RDD) 是一个不可变的对象集合。每个对象被划分到集群的节点上且并行地执行。
图 1. 关键词检测应用程序的结构图
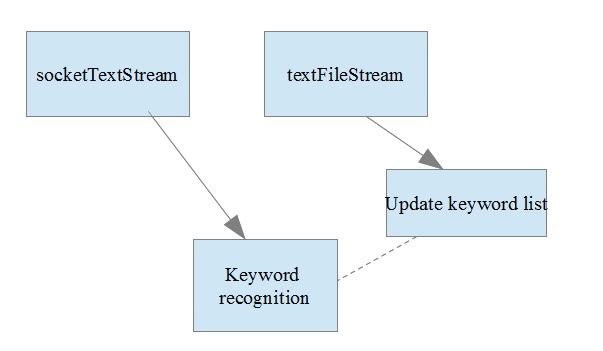
解释图 1 中的组件
SocketTextStream允许您绑定并监听一个传输控制协议 (TCP) 套接字上的消息。SocketTextStream的输出被提供给一个自定义流,后者使用当前关键词列表来查找相匹配的标记。TextFileStream用于监视 Hadoop 目录。只要它检测到一个新文件,就会读取该文件并将其转换为 DStream。使用TextFileStream读取的值和一个自定义逻辑来更新内部关键词列表。- 关键词检测逻辑使用更新后的关键词列表,所以该图使用虚线来表示此关系。
每个组件的实现细节
每个 Spark Streaming 应用程序首先都需要一个流式处理上下文,如下面的代码段所示。“上下文” 要求您传递一个持续时间参数,该参数定义一个批次。
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(5));socketTextStream 绑定到一个指定的主机接口和给定的端口号,并生成 DStream。
JavaReceiverInputDStream lines = ssc.socketTextStream( hostname, port, StorageLevels.MEMORY_AND_DISK_SER);textFileStream 使用 textFile 从 Hadoop 读取并行关键词字典文件。处理该文件后,会更新内部列表中的关键词。
JavaDStream<String> filelines = ssc.textFileStream("/tmp/Streamtest");
JavaDStream<String> updatedKeyWords = filelines.flatMap(new FlatMapFunction<String,String>() {
@Override
public Iterable<String> call(String x) {
final Pattern SPACE = Pattern.compile(" ");
String[] vec=SPACE.split(x);
List<String> ls=Arrays.asList(vec);
return ls;
}
});
updatedKeyWords.foreachRDD(new Function<JavaRDD<String>, Void> (){
public Void call(JavaRDD<String> rdd) {
rdd.foreach(new VoidFunction<String>(){
@Override
public void call(String x){
if(x!=null)
keywords.add(x);
}});
return null;
从 SocketStream 读取的 DStream 用于同关键词列表进行对比,如以下代码所示。使用命令 wordPresent.print(); 时,结果会显示在控制台上。
JavaDStream<Boolean> wordPresent = lines.map(new Function<String, Boolean>() {
@Override
public Boolean call(String x) {
return keywords.contains(x);
}
});
wordPresent.print();
下面的清单给出了本文中所用示例的完整代码。
public final class KeywordDetect { private static final Pattern SPACE = Pattern.compile(" "); public static List<String> keywords=new ArrayList<String>(); public static void main(String[] args) { if (args.length < 2) { System.err.println("Usage: KeywordDetect <hostname> <port> <words>"); System.exit(1); } SparkConf sparkConf = new SparkConf().setAppName("KeywordDetect"); JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(5)); JavaDStream<String> filelines = ssc.textFileStream("/tmp/Streamtest"); JavaReceiverInputDStream<String> lines = ssc.socketTextStream( args[0], Integer.parseInt(args[1]), StorageLevels.MEMORY_AND_DISK_SER); keywords.add("initial"); //Initialize keyword list JavaDStream<String> updatedKeyWords = filelines.flatMap(new FlatMapFunction<String,String>() { @Override public Iterable<String> call(String x) { final Pattern SPACE = Pattern.compile(" "); String[] vec=SPACE.split(x); List<String> ls=Arrays.asList(vec); return ls; } }); updatedKeyWords.foreachRDD(new Function<JavaRDD<String>, Void> (){ public Void call(JavaRDD<String> rdd) { rdd.foreach(new VoidFunction<String>(){ @Override public void call(String x){ //x=x+1; if(x!=null) keywords.add(x); //add newly read tokens to keyword list }}); return null; } }); JavaDStream<Boolean> wordPresent = lines.map(new Function<String, Boolean>() { @Override public Boolean call(String x) { return keywords.contains(x); //compare token received from socket against keywords list } }); JavaDStream<String> inputWords = lines.map(new Function<String, String>() { @Override public String call(String x) { return x; } }); wordPresent.print(); ssc.start(); ssc.awaitTermination(); } }编译并启动程序
对于本文中的示例,我们使用 Maven 来安装和构建应用程序。如果使用 Maven,请确保在 pom.xml 中添加了合适的依赖项。这些依赖项主要是 spark-core 和 spark-streaming 库。
以下代码给出了我们应用程序中使用的 pom 依赖项代码段:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.2.1</version>
</dependency>
编译应用程序并创建 jar 文件后,使用下面的命令将应用程序提交到 Spark 调度程序:
spark-submit --class "org.apache.spark.examples.streaming.KeywordDetect" --master local[4] target/KeyWord-1.0.jar rvm.svl.ibm.com 9212因为 Spark 实例在单个具有 4 个核心的单个主机上运行,所以我们为 –master 参数使用 local[4] 值。我们的应用程序接受两个参数:主机名和端口。
应用程序假设有一个服务器进程在端口 9212 上运行并发布数据。为了在测试环境中模拟一个服务器,我们使用 nc (netcat) Linux 命令:nc -l 9212。
nc 命令绑定到 9212。我们传入终端中的任何输入内容都会转发到所有正在监听端口 9212 的客户端。
所有方面都正确设置后,所提交的作业会开始运行并监听端口 9212。您应在终端上得到以下确认消息:
15/09/06 01:43:31 INFO dstream.SocketReceiver:Connecting to rvm.svl.ibm.com:9121
15/09/06 01:43:31 INFO dstream.SocketReceiver:Connected to rvm.svl.ibm.com:9121
现在,让我们更新该程序使用的内部字典。第 1.2 节中的代码可监听 Hadoop 目录 /tmp/Streamtest 中的更改事件。如果尚未创建该目录,请首先创建它,然后使用下面给出的命令上传关键词文件:
hadoop fs -mkdir /tmp/Streamtest hadoop fs -put keywords /tmp/Streamtest检测到一个新文件时,会执行后续的 RDD。
15/09/06 01:54:25 INFO dstream.FileInputDStream:New files at time 1441529665000 ms: hdfs://rvm.svl.ibm.com:8020/tmp/Streamtest/keyword
15/09/06 01:54:25 INFO storage.MemoryStore: ensureFreeSpace(272214) called with curMem=109298, maxMem=278302556
其中一个关键词是 "risk"。现在我提交 nc 中的关键词,如下面的清单所示。
[root@rvm Desktop]# nc -l 9121
risk然后,Spark 会检测到该关键词并在控制台上标记为 true。
-------------------------------------------
Time:1441529995000 ms
-------------------------------------------
true
未来增强
您可进一步增强此应用程序,从而处理完整的字符串,而不是单个标记。
您可将关键词检测状态写入到一个文件中,或者写入到一个 UI 呈现服务的端口。
异常条件
如果出现 "connection refused error",可能是因为:
- HDFS 和 Yet another resource negotiator (YARN) 未运行
- 服务器进程未在来源端口上运行。在我们的例子中,来源端口为 9121。
结束语
本文演示了如何使用 Spark Streaming 构建实时应用程序。我们还着重介绍了一个 Spark Streaming 应用程序的组成部分。使用此信息作为起点,有助于您使用 Spark Streaming 创建更复杂的应用程序。
正文到此结束
- 本文标签: root maven map 时间 list dist ACE apache 端口 HDFS 代码 key example Word update IBM 集群 API XML Connection 关键词 java Hadoop cat 大数据 实例 Developer http rmi 测试 进程 IDE parse final 主机 目录 协议 tar 数据 App 开发 core Twitter linux 编译 mina UI Apache Hadoop 参数 src scala 服务器 pom 安装 TCP 软件 lib python
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

