深度学习难以加冕算法之王 3 大根本原因
(文/Ron Wilson)很多媒体报道都将深度学习算法比作当前的算法之王,尤其是卷积神经网络(CNN),似乎已经成了深度学习算法里毋庸置疑的第一名。ImageNet 视觉识别竞赛中,CNN 击败了所有其他的算法,其性能之强大,让人觉得只剩下实施的细节问题。
从自动驾驶汽车到下围棋的计算机,CNN 看起来还在一系列更实用的系统中牢牢占据了一席之地。CNN 是时下的宠儿——似乎集技术之大成,凌驾其他所有人工智能。
但在人工智能领域,所有力量都不是注定的。深度学习批评家指出,CNN 还有很多没有解决的问题。最近有讨论,机器在物体识别上的准确率超过人类究竟意味着什么。关于如何架构 CNN 以及架构好 CNN 之后,如何预测架构的准确率和性能,也存在很多未解决的问题。当神经网络的层数和节点不断增加,如何维持 CNN 的性能也是问题。还有一个更大的问题,那就是如何衡量 CNN 的准确率。
2016 年 5 月底,斯坦福大学召开了 IEEE Computer Society 2016 年认知计算会议,很多论文不但没有提及 CNN 取得的成就,反而研究了相反的问题。
CNN很少出错,但出错则造成毁灭性后果
CNN 最大的一个强项就是 ImageNet 图库识别的准确率。微软的应用几乎在所有类型的物体识别中都超过了人类。但要弄清物体分类测试的原理:算法需要检测给定图像中的物体,在周围标上框,然后从一份含有 1000 个标签的表单中,选取最能代表这一物体的 5 个标签。评分标准是看算法在物体周围画的框,与实物边缘有多近、给的标签有多准。
批评家指出,ImageNet 竞赛用于比较不同算法之间的性能可能挺管用,但比较不同算法与人类之间的区别则没多大用处。试想,在图像中找出一只猴子,估计对人类而言很简单,但又有多少人知道,那只猴子是长尾猴而不是长鼻猴呢——经过充分训练的算法可是能够做到这一点的。此外,在那些认出了是长尾猴的人当中,又有多少知道那是德赖斯长尾猴呢?
以上只是针对 ImageNet 的讨论。但放在现实生活应用场景,CNN 就会产生很现实的问题, 倒不是说错误出现概率,而是错误后果大小的问题 。一个人或许认不出路上的一只猴子是长尾猴,但她不会把这只猴子当作水坑,或者“no high-likelihood response available”,然后直接碾过去。
鉴于网络架构,人类没有办法确保 CNN 是否会在全新的情境下造成毁灭性的错误。CNN 训练好以后,无论是通过定性还是定量分析,几乎都没有办法预测网络会对新的输入产生怎样的结果。但是,我们可以根据 CNN 运行的理论,对网络的反馈有个大致的了解。
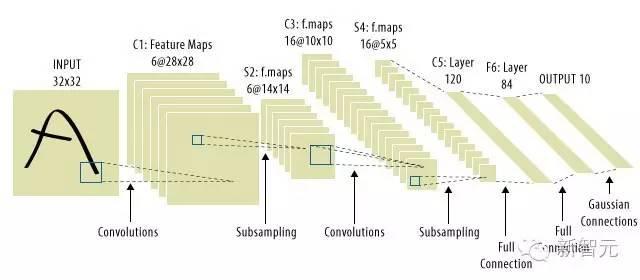
CNN 由很多层节点构成,每一层都在前一层的基础上依次形成抽象概念。
粗略讲,训练好的 CNN 的一层神经网络中,每个节点都是对一个具体命题真实性的估计,命题跟输入的数据有关。从紧挨着输入的一层到输出前的一层,命题会变得越来越抽象。
每一个抽象层中,你能得到的原子命题(atomic propositions)受制于每一层网络节点的数量。尤其是算法识别一个物体时可用的标签数量,不能大于网络最终的输出数量。
精心设计的 ImageNet 竞赛中,这个数字是 1000。开发人员发现,20 到 50 级的 CNN 适合用于 ImageNet 竞赛,这样的网络大约包含 500 万个节点,但这样规模的网络只有数据中心才有。
而且,给物体打标签的 CNN 比在现实道路上操纵一辆车的 CNN 小很多,那要有多少标签才能确保,操纵汽车的网络在遇上看不清或从未见过的物体时,不会发生差错?要评估多少个命题才能确保网络在真实世界情景中选择最优路线?还有,最关键的,怎么把只能在数据中心运行的网络放进一辆汽车里?
硬件加速,并不解决根本问题
方法之一是使用专门的硬件加速 CNN 的训练和执行。鉴于 CNN 的训练和执行都以矩阵运算为主,内存带宽高、有很多乘法器的芯片,比如 GPU 和 FPGA 都不错。
我们也充分理解了 CNN 的数学原理——除非你用下降梯度算法做强化学习。因此,可以设计一个 ASIC 处理计算,并寄希望于 CNN 的卓越性能能开创一个新的市场,由此缓解芯片开发成本高带来的压力。
这方面的典型代表是谷歌,他们推出了定制芯片 TPU。新创公司 Nervan 也推出了一款 TPU,但与谷歌的不同,这款 TPU 是由海量 RAM 组成的乘法器阵列,比 GPU 的乘法器多了 100 多倍。IBM 的 TrueNorth 芯片采用神经网络架构,TrueNorth 处理器速度与大型 CNN 相当,能耗却很少。
但是,虽然芯片能提高 CNN 的训练和执行速度,可并没有解决根本问题。
智能系统需要多种算法和数据结构
斯坦福计算机科学副教授 Sivio Savarese 表示, 物体上带的所有标签加在一起,没有任何意义 。



现在,市场上出现了对新的认知系统的需求,这些新的系统要能够赋予数据库以意义并推理得出结论,很多人担心 CNN 不足以建立这样的系统。
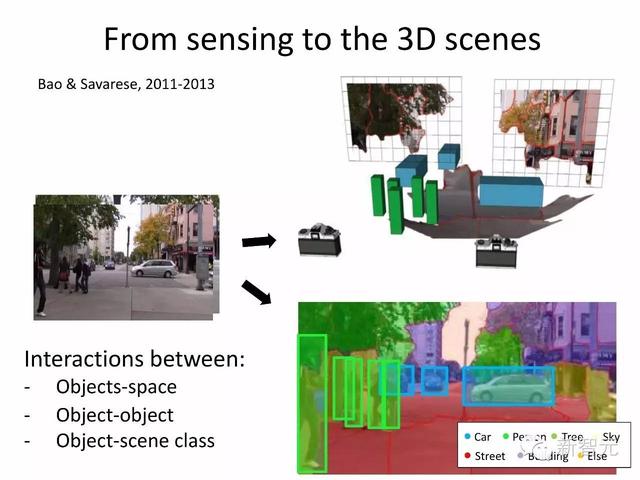
Svarese 描述了一个能在三维空间跟踪定位物体的系统。通过将位置和方向纳入一个目标的属性,系统能够推断出这些三维物体的关系。
DOCOMO 资深科学家 Sayandev Mukherjee 从自然语言处理的角度,提出了一种全新的方法。Mukherjee 的系统能够接收非结构化的语音和文本信息,再将其分解成带标签的对象,比如专有名词、普通名词、定语和表语。系统会利用这些数据建造一个知识图谱,其中节点就代表概念。
这种环境下,图像分析工具就成了推理工具,能够找到关联,进行类比、归纳和演绎,即使用到 CNN,也只会是在语音或文本识别模块的前端。和知识图谱一样,这类方法也能在空间中工作。



人类说话时带有很多模棱两可的信息。斯坦福副教授 Noah Goodman 在演讲中讨论了常识在理解模糊语言中的作用,通过在语言分析中加入条件概率,模拟不确定性(non-deterministic faculty)。
Goodman 以 Lisp 语言为此基础,加入条件概率分布和条件分布函数,设计了一种名叫 Church 的语言。Church 利用概率函数的组件,获取关于自然语言语句的大量有用信息,而且只需要少量代码就能实现。Church 看上去非常善于处理双关语、比喻等自然语言结构。






IBM 研究院的 Jeffrey Welser 认为,关于未来的发展趋势并不是逐渐建立规模更大的 CNN,也不会只使用一种通用算法。Welser 表示,系统需要很多不同的组件,每个组件都有特定的功能。
Welser 表示,从宏观层面上讲,认知系统包括对真实世界模拟建模,以及对直接从现实世界采集的非结构化数据进行大数据分析。认知系统将结合这两者并优化模型,得出一个所有可能情形的分布,并从中选择让能够自己接近目标的结论。这种模型既可以用来形容自动驾驶汽车,同样说它是辩论机器人也没问题。
而上述系统可能会将 CNN 用于视觉处理、类似目标识别和打标签。但是,CNN 还将和许多其他算法以及数据结构整合在一起。
机器智能算法世界里,还没有谁能称王。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

