基于内容推荐的个性化新闻阅读实现(二):基于SVD的推荐算法
一、前言
SVD前面已经说了好多次了,先不论其信息检索被宣称的各种长处如何如何,在此最主要的作用是将稀疏的term-doc矩阵进行降维,当一篇篇文章变成简短的向量化表示后,就可以用各种科学计算和机器学习算法进行分析处理了。
之前的推荐算法的设计是用的最大熵估计,他和诸如朴素贝叶斯、逻辑回归等,本质就是根据文章词汇信息把文章作为一个二类归类问题来解决的。根据自己以前的经验,这种方法是最简单,效果也还是比较理想的,而且相比现在设计的越来越复杂的算法,也有坚实的数理做依据的。
这次,尝试一个新的推荐方式,我的思路是这样的:如果你SVD分解降维后取n_topics=2,那么这些文章最后就都映射成了二维向量,可以把这些二维向量看作平面中的坐标,那么每篇文章其实就是这个平面上的点了。一般来说,文章越相似,那么他们的向量就越相近,然后映射到坐标空间中两者的欧式距离也就越短。反应到我们的推荐阅读中,如果一个人可能有几个兴趣点,那么他喜欢的文章在空间位置就应该聚成以这几个簇的形式展现出来。当然n_topics=2肯定不能用在实践中应用的,否则会丢失大量的特征信息,但是很容易将这个想法推广到多维的超平面上,基本原理都是一样的。
这个方法在实现中考虑到的缺陷有:浮点向量没法保存到数据库,只能驻留内存和dump到文件系统了;计算速度肯定比贝叶斯要慢很多,但是绝大多数推荐系统不都是定时进行数据线下计算线上加载的么;目前只考虑点赞的,不考虑踩的负样本的影响了,或许这也不是什么优劣势,负样本本来就可以在所有样本中采样来进行平衡。
二、算法实现流程
具体实现流程步骤设计如下:
(1) 设置n_topics参数,然后对历史的文章进行SVD奇异值分解,生成LSI空间参数;
(2) 针对每一个用户,取出其历史点赞的文章,用LSI浮点向量表示后,把每篇文章两两计算其余弦值相似度,形成各个文章间的相似度矩阵;
(3) 设定阈值范围factor(比如0.5,其值也可以根据后面的计算结果动态反馈修改),然后遍历所有点赞的文章,如果其阈值范围内的点赞文章数目达到三篇及以上,那么创建其为一个兴趣点,平均化兴趣点中所有文章的特征向量得到中心特征向量,其兴趣权重正比于其兴趣点中所包含的文章的数目;
(4) 细心的读者可能发现,这样肯定会产生很多个覆盖有重叠的兴趣点。可不是嘛!所以这里还需要一步额外的迭代:选取权重最高的兴趣点,确定之后将包含的所有文章排除掉,然后再在剩余的文章中选择最高权重的兴趣点,依次下来直到没有新的兴趣点或者达到指定要求的兴趣点,迭代结束;
(5) 每当有当日新的文章到来,通过之前SVD参数计算其在当前空间中的表示向量,然后按照其到各个兴趣点特征向量距离并乘上兴趣点的权重,得到推荐分数,以最高分数作为这篇文章的最终推荐分数。
三、效果评价
通常算法的评价一般需要用标注数据和预测推荐进行验证。一天几百篇文章我也懒得过一遍再标注了,就偷点懒,用之前最大熵估计的推荐分数和本文算法的推荐结果进行一个对比吧!
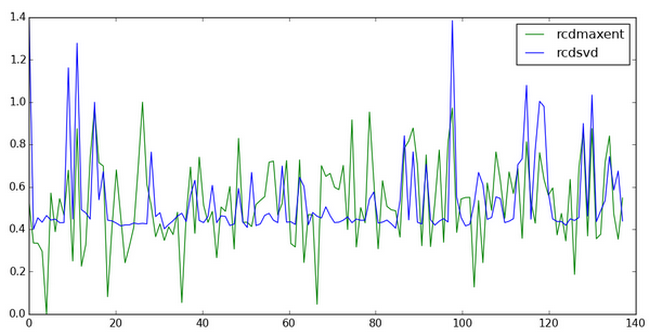
感觉效果还不是特别的明显,是数据的原因么?
四、后注
这只是自己凭空想出来的推荐,自我觉得还是有道理的吧。
项目代码还是老地方 readmeinfo ,因为词ID用gensim的库做了,所以运行新代码前记得删除dump缓存目录所有的缓存数据,同时数据库的site_rcd这个表记得添加double类型的recsvd字段。
本来打算部署到我的512M的VPS上的,但是上面服务太多已经很慢了,后面居然给我报内存错误,看来MaxEnt和SVD都是消耗内存的大户啊,所以上面的数据是把服务器的数据导下来用本地笔记本跑的结果,当然这些数据我也上传到代码库了,感兴趣的可以自己验证!同时由于荒芜了一段时间(最主要还是移动端UI做烂了,自己都懒得看啊),历史好评数据不够多,所以就产生了一个兴趣点,不排除多个兴趣点的情况下还有Bug,欢迎反馈!
真心想,如果有足够数据,做个协同过滤CF还是多爽的,不然枉费搞过推荐系统了~
本文完!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

