Treq: 高性能网络库简明教程
Treq on Twisted简介
Treq是一个HTTP客户端库,参考了Requests库的设计思路,基于Twisted的模式进行了实现,具有Twisted典型的强大能力: 处理网络 I/O 时它是异步且高度并发的方式。 它是写高并发HTTP客户端的好工具,擅长网页抓取。Treq很优雅、易于使用且强大。这是一个例子:
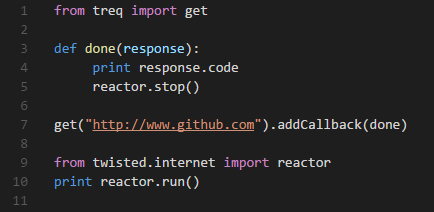
这个例子里面,使用Treq进行网络请求,就像 requests 一样的简单直接。后面章节, 介绍 treq 的使用方法。
Auth 认证
base64认证方法通过auth参数来使用:
def main(reactor, *args): d = treq.get( 'http://httpbin.org/basic-auth/treq/treq', auth=('treq', 'treq') ) d.addCallback(print_response) return d |
Redirect 重定向
treq 默认是自己处理重定向。也可以通过 allow_redirects=False 来禁止默认的行为。Response 对象的 history 方法可以查询出全部定向路径。
def main(reactor, *args): d = treq.get('http://httpbin.org/redirect/1') d.addCallback(print_response) return d react(main, []) |
def main(reactor, *args): d = treq.get('http://httpbin.org/redirect/1', allow_redirects=False) d.addCallback(print_response) return d react(main, []) |
def main(reactor, *args): d = treq.get('http://httpbin.org/redirect/1') def cb(response): print 'Response history:', response.history() return print_response(response) d.addCallback(cb) return d |
使用 Cookie
和 requests 一致,treq 的 cookie 也支持 dict 和 cooklib.CookieJar 两种格式, 传递个 cookies 参数即可。请求的响应中,条用 cookies 方法可以获取服务器返回的 cookies 。
def main(reactor, *args): d = treq.get('http://httpbin.org/cookies/set?hello=world') def _get_jar(resp): jar = resp.cookies() print 'The server set our hello cookie to: {0}'.format(jar['hello']) return treq.get('http://httpbin.org/cookies', cookies=jar) d.addCallback(_get_jar) d.addCallback(print_response) return d |
请求参数 QueryParameters
请求中加上 params 参数,treq 会自动将这下参数通过 urlencode 之后再添加到参数列表中。params 参数支持 dict 类型或者 满足 (key, value) 格式的列表(包括元组)。
@inlineCallbacks def main(reactor): print 'List of tuples' resp = yield treq.get('http://httpbin.org/get', params=[('foo', 'bar'), ('baz', 'bax')]) content = yield treq.content(resp) print content print 'Single value dictionary' resp = yield treq.get('http://httpbin.org/get', params={'foo': 'bar', 'baz': 'bax'}) content = yield treq.content(resp) print content print 'Multi value dictionary' resp = yield treq.get('http://httpbin.org/get', params={'foo': ['bar', 'baz', 'bax']}) content = yield treq.content(resp) print content print 'Mixed value dictionary' resp = yield treq.get('http://httpbin.org/get', params={'foo': ['bar', 'baz'], 'bax': 'quux'}) content = yield treq.content(resp) print content print 'Preserved query parameters' resp = yield treq.get('http://httpbin.org/get?foo=bar', params={'baz': 'bax'}) content = yield treq.content(resp) print content |
Stream 响应
treq 支持流式下载响应, treq 提供了 treq.collect 方法,该方法接收 response 和 一个处理函数, 每收到一份数据, 处理函数都能获取到最新的数据并进行处理。样例:
def download_file(reactor, url, destination_filename): destination = file(destination_filename, 'w') d = treq.get(url) d.addCallback(treq.collect, destination.write) d.addBoth(lambda _: destination.close()) return d |
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

