Language Understanding for Text-based Games using Deep Reinforcement Learning #PaperWeekly#
继上上周的机器阅读理解和上周的自动文摘分享之后,本周开始分享几篇Deep Reinforcement Learning在NLP中应用的paper。在网上看到过这样的言论,一些大牛认为深度增强学习是人工智能研究的未来,是真正的AI,还给出了一个这样的公式:DL+RL=AI。其实,增强学习一直都是机器学习中常用的一种无监督学习方法,随着deepmind公司的一些好玩的成果,比如:用程序来玩简单的video games,AlphaGo战胜李世乭等等,深度增强学习随之兴起。今天将分享的paper是 Language Understanding for Text-based Games using Deep Reinforcement Learning ,作者是来自麻省理工学院的博士生 Karthik Narasimhan 和 Tejas Kulkarni ,文章最早于2015年6月30日刊在arxiv上。
在介绍深度增强学习在NLP中的应用之前,需要简单介绍下增强学习和深度增强学习。
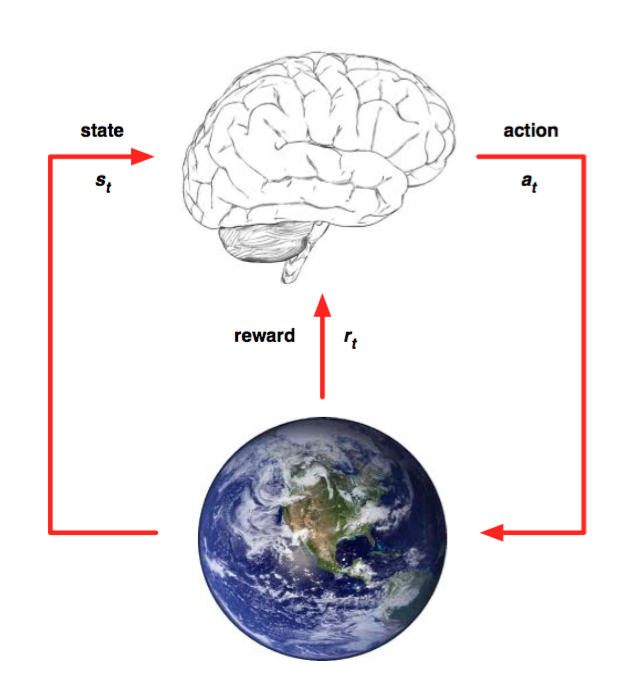
上图来自于deepmind David Silver的slide。
图中的大脑可以理解为一个agent,并且这个agent有一个action集合,地球可以理解为environment,并且environment每个time step都有一个状态state。增强学习想要做的一件事情是agent在某一个time step中接收来自environment的state,执行一个action,然后从environment中得到一个reward,根据state和reward继续选择一个action,目标是使得reward最大。整个过程是一个不断交互和反馈的控制过程,通过引入值函数Q(s,a)来计算当前state和action对应的未来所有reward的期望,这里涉及到一些细节,推荐看 智能单元知乎专栏 的系列博客《DQN从入门到放弃》,包括Bellman Equation、多种增强学习模型、ε-greedy policy等等内容。
深度增强学习,这里专指DQN(Deep Q-Network),是将深度学习模型引入到了传统的Q-Network中,用深度神经网络来近似Q函数,构造输入和输出数据,进行端到端的训练来学习这个问题。deepmind那两篇有名的paper, Playing Atari with Deep Reinforcement Learning 和 Human-level control through deep reinforcement learning ,第一篇最早提出了DQN的方法,另一篇提升了第一篇的模型,并且发表在了nature上,deepmind做的事情都是用计算机程序来玩video games,并且在多个游戏中取得了比人类玩家更好的成绩。由于都需要处理游戏画面,所以encoder部分都是采用多层CNN提取feature。
简单介绍了一些预备的内容之后,下面来介绍本文的内容。本文是基于一个文字游戏来展开的,通过text state,通常是一段比较长的介绍性文字,来给出一个合适的action进入下一个state。如下图:

上图中从state1 The old bridge 通过选择 Go east 这个动作进入了state 2 Ruined gatehouse 。
如果对DQN的相关东西有所了解的话,本文的模型就显得非常简单了。
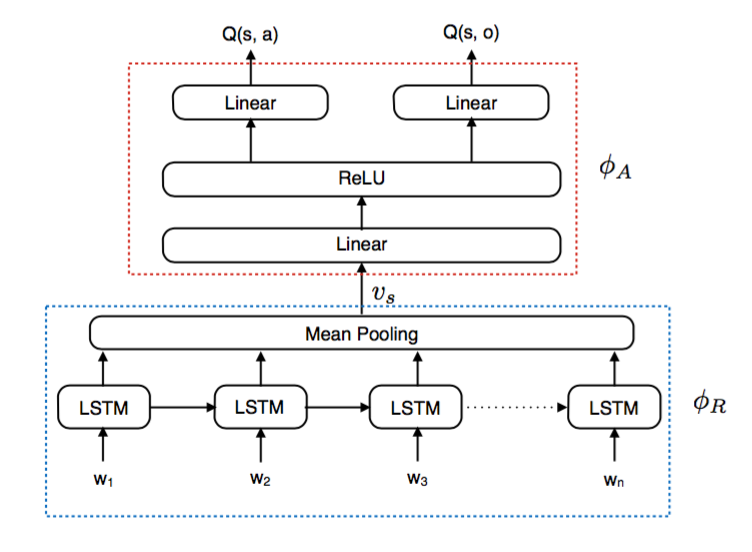
模型分为两个部分,第一部分是representation generator,将state中的text用lstm处理,每个word对应一个time step,然后将所有time step的向量做一次平均池化处理,得到该状态的表示。video games因为输入的是游戏图像,所以用cnn来处理,而text games都是文字,用rnn来处理也最合适不过的了。另外一点是,本文也考虑过用lstm的last hidden state作为state的表示,但收敛速度没有平均池化快。
第二部分是action scorer,就是一个多层的神经网络,用state的表示作为输入,得到的输出是集合中每个action的score,而不是每一对action-state的score,这样的计算效率更高一些。
由此用神经网络模型近似得到了Q函数。本文特点强调了一点,为了保证计算效果,只选取游戏命令是一个action(比如:go)和一个object(比如:east)的组合,当然这一类命令也占据了游戏命令的绝大多数。从模型图中可以看出,计算action和object是同样的结构,最终该命令的Q值由action和object的Q值由两者的平均值来代替。
关于训练方法,和DQN也区别不大。最关键的一点是构造训练数据集,每一条数据格式是(s(t-1),a(t-1),r(t-1),s(t)),每次进行游戏的时候,都会有一个当前的state、action和reward,执行完action之后会得到一个新的state,将这四个元素保存为一条数据,积累大量的类似的数据,保存到一个数据池中,每次训练的时候从池中sample出,这个池是一个FIFO的队列。具体可看下面的流程图:

这里简单地说一下ε-greedy是怎么一回事。ε通常是一个非常小的值,这种策略一般被称为exploration,探索性的策略,面对未知的情况,随机选择一个action进行执行,探索一下会有什么情况发生,这种策略容易更新Q值;greedy策略,通常称为exploitation,利用性的策略,选择令Q值最大的action,不利于更新出更好的Q值,但可以得到相对更好的测试结果。
训练的目标函数是target与近似函数的差的平方,用一般的优化方法就可以训练了。其中,近似函数是我们需要学习的模型,target是通过Bellman方程来进行计算的(这里面涉及到的概念可以参考前面提到的智能单元的博客来学习)。
读完本文,有几点思考,分享一下:
1、增强学习看着也挺像监督学习的,到底有什么优势和区别吗?
我想它最大的优势是不是在于那个动态的、大型的数据池,可以源源不断地提供样本,可以说是无穷无尽的样本,这一点比一般的监督学习更加厉害,因为毕竟监督学习需要给定一个自带标签的数据集。通过不断的学习,来得到一个不错的模型。
2、DQN和经典的增强学习相比优势在哪里?
其实这个问题从某个角度上来看可以等同于Deep Learning与经典的机器学习相比,优势在哪里?一方面是神经网络模型强大地非线性函数近似,另一方面就是不需要人工feature,所有的feature都是从data中学习来的,典型的data-driven。
3、DQN在NLP中的应用,相比于DQN几乎没有什么新的东西,只是做了一些概念的替换。比如:在生成问题上,都是计算一个P(word|context),这里将DQN中的state理解为context,将word理解为action。不过非常不同的一点是,nlp中的action space会非常大,因为对于生成问题来说,词汇表会变得非常大。这个问题该如何解决呢?大家可以期待明天的分享 Generating Text with Deep Reinforcement Learning 。
如果大家觉得有写的不够清楚的地方或者错误的地方,欢迎留言交流。
工具推荐
PaperWeekly,每周会分享N篇nlp领域好玩的paper,旨在用最少的话说明白paper的贡献,欢迎大家扫码关注。

知乎专栏 paperweekly
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

