Trie 树结构
之前说搜索提示的时候留了一个尾巴,就是Trie树的结构没有说,这一篇简单的说一下Trie树的实现方式。
1. Trie树是什么
在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。 Trie这个术语来自于retrieval。根据词源学,trie的发明者Edward Fredkin把它读作英语发音:/ˈtriː/ "tree"。但是,其他作者把它读作英语发音:/ˈtraɪ/ "try" 以上文字来自 维基百科
2. 应用范围
搜索提示和分词是Trie树的经典应用范围。
3. 基本Trie树实现
Trie树 又叫 字典树 ,本质上是一个多叉树,每一个节点就是一个多叉的结构,如果是英文的匹配,那么是一个 26叉树 ,每个节点一个26长度的数组,每个节点的数据结构如下
type TrieNode struct{
flag bool
hasNext bool
nexts [26]*TrieNode
} 其中 flag 保存的是当前节点是否已经是一个完整字符串了。 hasNext 表示是否还有下一节点,而 Trie树 画出来就是下面这个样子。 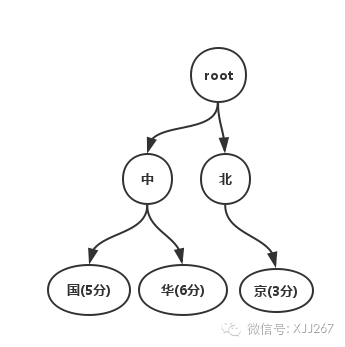 从画出来的图,很直观的可以看出来这棵树的构造方法和遍历方法,因为每个节点都有一个26长度的数组,来了一个字符,通过字符的编号直接就可以遍历到下一个节点,查找的时候复杂度就是O(K),K表示查找的字符串长度,这种数据结构简单明了,实现起来也很容易。 但是这种数据结构有个问题,就是内存使用得太多了,如果是中文查找的话,需要把所有的中国字都编号到这个数组中,于是有一种优化方法,就是把数组变成变长的,如果按照二分进行每个节点的查找的话,每个节点的查找时间变成了O(lg(n)),整体的查找时间变成K*O(log(n)),n是数组平均长度,这样的话,虽然内存的使用上降低了,但是查找速度变长了,而且插入的时候需要按序插入,插入也变慢了。 按照真正的树形结构,通过各种指针满天飞的形式来实现Trie树,基本上属于新人练手的水平,纯粹为了了解这个数据结构或者大学生做做课程设计,工程化的可能性几乎为0。
从画出来的图,很直观的可以看出来这棵树的构造方法和遍历方法,因为每个节点都有一个26长度的数组,来了一个字符,通过字符的编号直接就可以遍历到下一个节点,查找的时候复杂度就是O(K),K表示查找的字符串长度,这种数据结构简单明了,实现起来也很容易。 但是这种数据结构有个问题,就是内存使用得太多了,如果是中文查找的话,需要把所有的中国字都编号到这个数组中,于是有一种优化方法,就是把数组变成变长的,如果按照二分进行每个节点的查找的话,每个节点的查找时间变成了O(lg(n)),整体的查找时间变成K*O(log(n)),n是数组平均长度,这样的话,虽然内存的使用上降低了,但是查找速度变长了,而且插入的时候需要按序插入,插入也变慢了。 按照真正的树形结构,通过各种指针满天飞的形式来实现Trie树,基本上属于新人练手的水平,纯粹为了了解这个数据结构或者大学生做做课程设计,工程化的可能性几乎为0。
4. 双数组Trie树
正因为有上面的各种问题,于是有人发明了 双数组Trie树 ,其实在这个之前还有个 三数组的Trie树 ,为了不让大家更迷糊,我们直接来看看双数组的形式吧。 所谓双数组Trie树,当然就是通过两个数组来实现这棵树了,这两个数组分别叫 base数组 和 check数组 ,一个是基础数组,一个是检查数组,Suggestion服务对Trie树的操作基本上需要有Trie树的构建部分和Trie树的查询部分,插入操作基本上很少使用,后面说数据部分的时候会说到为什么。 Trie树实际上是一种 有限状态机 ,通过 状态转移矩阵 在各个状态之间跳转,我们不去管这两个概念,会越说越糊涂,如果你实在是有兴趣,可以自己去查查资料,我们直接来点实在的,用一个例子来看看 双数组Trie树 是如何工作的。
4.0 前提场景
假设我们的词库里面有这么一些词, 中国,北京,中华,华北 这几个词语,需要构建一棵 Trie树 ,构建好了以后,用户输入 中 字的时候,能把 中国,中华 都给提示出来。这里的例子直接使用了中文是为了更直观,省得都是abc这种例子容易乱,虽然最后的处理上中文有点特殊,但不影响算法描述。
4.1 Trie树构建
首先,拿到这些个词以后,第一步就要构建这棵Trie树了,构建之前,我们先对每一个字进行编号一下,这个只是为了方便描述, 中:1,国:2,北:3,京:4,华:5 。
初始化
-
初始化空数组,初始化base和check两个空数组。
-
base的元素为1表示是开始位偏移为1,为-1表示没有数据。
-
check的元素中,-1表示没有数据,-2表示这是一个词结束了,-3表示是根节点,如下图所示
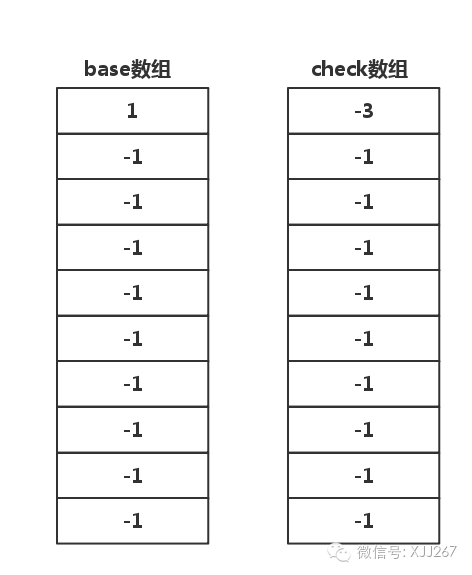
初始化好了以后就可以开始依次读取数据了,先读取出 中国 两个字,开始插入
插入 中国 这个词
插入 中 字
-
从根节点开始,base[0]=1,插入位置为
base[0]+中,中的编号为1,所以是base[0]+1=1+1=2,于是得到应该插入到base[2]的位置。 -
检查
check[2],看到check[2]为-1,表示base[2]没有数据,可以插入 -
更新
check[2]为上一个节点的base数组的下标,上一个节点是base[0],所以更新为0 -
更新
base[2]为上一个节点的base数组的值,上一个节点base[0]的值是1,所以更新为1
按照上面的四个步骤更新完了以后,整个数组变成下面这个样子,对着图可以仔细想想整个过程,然后你想想伪代码是什么样子的,再想想如何编程。 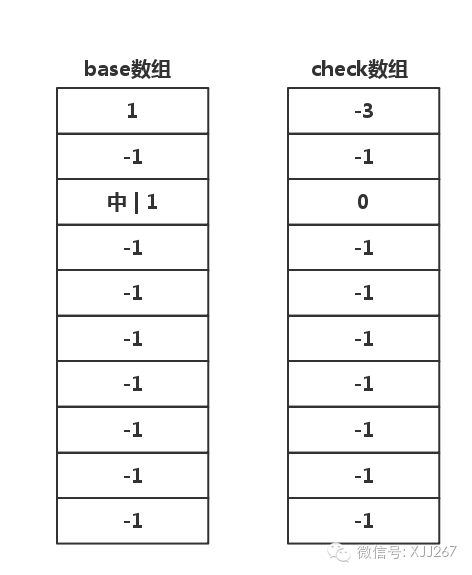
插入 国 字
-
由于这个词语还没结束,所以从base[2]开始继续往下走
-
从base[2]开始,插入位置为
base[2]+国,国的编号是2,所以是base[2]+2=1+2=3,应该插入到base[3]中 -
检查
check[3],看到check[2]为-1,表示base[2]没有数据,可以插入 -
更新
check[3]为上一个节点的base数组下标,上一个是base[2],所以更新为2 -
更新
base[3]为上一个节点的base数组的值,上一个节点base[2]的值是2,所以更新为2
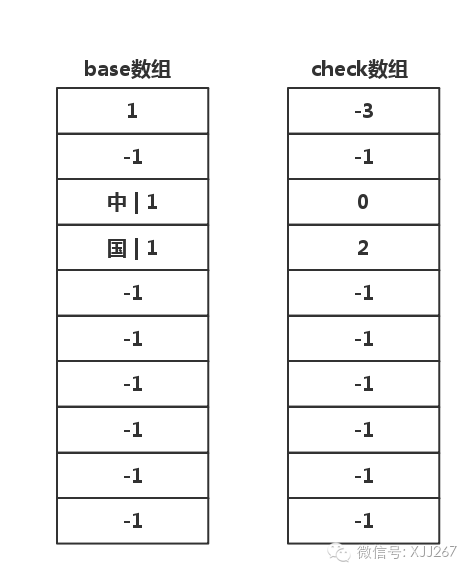
插入 北京 和 中华 这个词
大家可以自己插入一下 北京 和 中华 这两个词,插入以后结构变成下面的样子 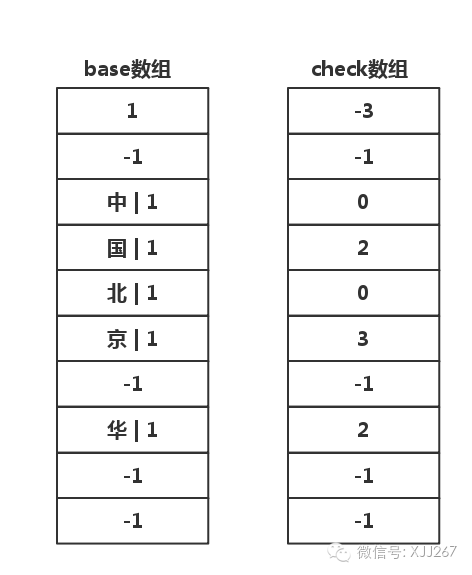
插入 华北 这个词
到现在一切都很顺利,接下来插入 华北 这个词,这里就会遇到冲突了,遇到冲突以后,进行如下算法
插入 华 字
这个插入正常,最后图像如下所示 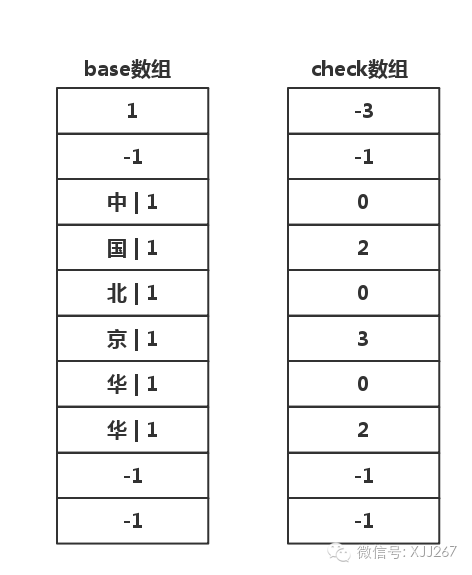
插入 北 字
-
由于这个词语还没结束,所以从base[6]开始继续往下走
-
从base[6]开始,插入位置为
base[2]+北,国的编号是3,所以是base[6]+3=1+3=4,应该插入到base[4]中 -
检查
check[4],看到check[2]为0,表示base[4]有数据,产生冲突!! -
从base[6]往后找空闲空闲,空闲空间的概念是两个数组都是-1
-
找到base[8]和check[8]为空闲空间
-
更新check[8]为上一节点的值,6
-
计算base[6]应该的值为8-北=8-3=5,更新base[6]为5,
解决冲突!!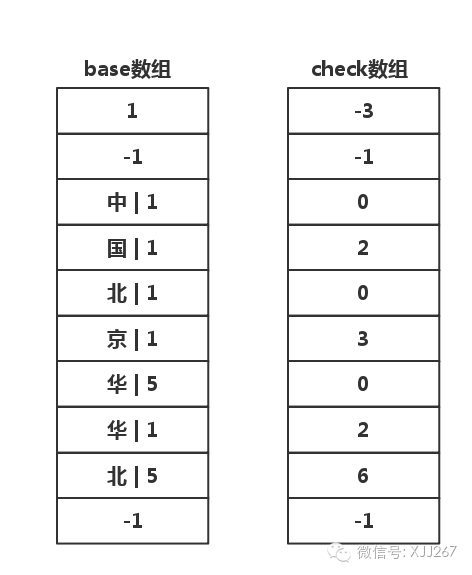
5. 查询
要进行查询,就相对简单了,拿到一个词,比如 中华 ,先确定每个字的编号,然后按照两个数组去遍历,就知道这个词在不在这个Trie树中了,复杂度就是词的长度。
6. 总结
本篇比较简单,就是上次搜索提示的一个小尾巴,后面会说到分词的技术,这个Trie树也是分词的主要数据结构。
如果你觉得不错,欢迎转发给更多人看到,也欢迎关注我的公众号,主要聊聊搜索,推荐,广告技术,还有瞎扯。。文章会在这里首先发出来:)扫描或者搜索微信号 XJJ267 或者搜索中文 西加加语言 就行

相关阅读: 坑系列 --- 时间和空间的平衡
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

