SeimiCrawler:敏捷、独立部署、支持分布式的 Java 爬虫框架
SeimiCrawler
An agile,powerful,standalone,distributed crawler framework.
SeimiCrawler的目标是成为Java里最实用的爬虫框架,大家一起加油。
简介
SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架,希望能在最大程度上降低新手开发一个可用性高且性能不差的爬虫系统的门槛,以及提升开发爬虫系统的开发效率。在SeimiCrawler的世界里,绝大多数人只需关心去写抓取的业务逻辑就够了,其余的Seimi帮你搞定。设计思想上SeimiCrawler受Python的爬虫框架Scrapy启发很大,同时融合了Java语言本身特点与Spring的特性,并希望在国内更方便且普遍的使用更有效率的XPath解析HTML,所以SeimiCrawler默认的HTML解析器是 JsoupXpath (独立扩展项目,非jsoup自带),默认解析提取HTML数据工作均使用XPath来完成(当然,数据处理亦可以自行选择其他解析器)。
号外
- 2016.04.14
用于实现浏览器级动态页面渲染以及抓取的SeimiAgent已经发布。SeimiAgent基于Qtwebkit开发,主流浏览器内核(chrome,safari等),可在服务器端后台运行,并通过http协议发布对外调用API,支持任何语言或框架从SeimiAgent获取服务,彻底的解决动态页面渲染抓取等问题。具体可以参考SeimiAgent主页。SeimiCrawler已经在 v0.3.0 中内置支持SeimiAgent的使用并添加了demo,具体请查看demo或是官方文档。
- 2016.01.05
专门为SeimiCrawler工程打包部署的 maven-seimicrawler-plugin 已经发布可用,详细请继续参阅 maven-seimicrawler-plugin 或是下文 工程化打包部署 章节。
原理示例
基本原理
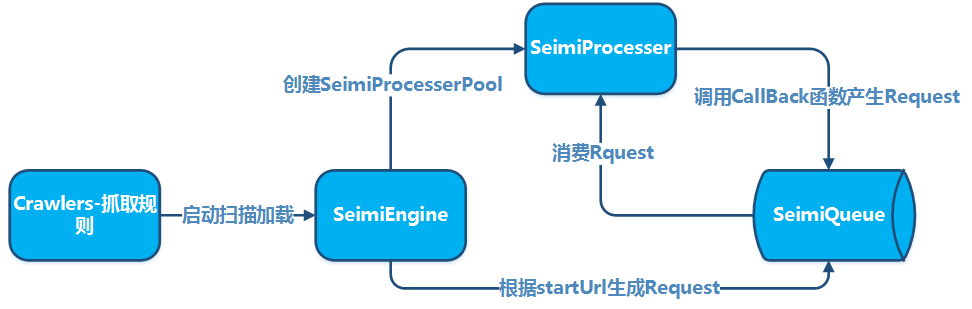
集群原理

快速开始
添加maven依赖(中央maven库最新版本1.0.0):
<dependency> <groupId>cn.wanghaomiao</groupId> <artifactId>SeimiCrawler</artifactId> <version>1.0.0</version> </dependency> 在包 crawlers 下添加爬虫规则,例如:
@Crawler(name = "basic") public class Basic extends BaseSeimiCrawler { @Override public String[] startUrls() { return new String[]{"http://www.cnblogs.com/"}; } @Override public void start(Response response) { JXDocument doc = response.document(); try { List<Object> urls = doc.sel("//a[@class='titlelnk']/@href"); logger.info("{}", urls.size()); for (Object s:urls){ push(new Request(s.toString(),"getTitle")); } } catch (Exception e) { e.printStackTrace(); } } public void getTitle(Response response){ JXDocument doc = response.document(); try { logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")); //do something } catch (Exception e) { e.printStackTrace(); } } } 然后随便某个包下添加启动Main函数,启动SeimiCrawler:
public class Boot { public static void main(String[] args){ Seimi s = new Seimi(); s.start("basic"); } } 以上便是一个最简单的爬虫系统开发流程。
工程化打包部署
上面可以方便的用来开发或是调试,当然也可以成为生产环境下一种启动方式。但是,为了便于工程化部署与分发,SeimiCrawler提供了专门的打包插件用来对SeimiCrawler工程进行打包,打好的包可以直接分发部署运行了。
pom中添加添加plugin
<plugin> <groupId>cn.wanghaomiao</groupId> <artifactId>maven-seimicrawler-plugin</artifactId> <version>1.1.0</version> <executions> <execution> <phase>package</phase> <goals> <goal>build</goal> </goals> </execution> </executions> <!--<configuration>--> <!-- 默认target目录 --> <!--<outputDirectory>/some/path</outputDirectory>--> <!--</configuration>--> </plugin> 执行 mvn clean package 即可,打好包目录结构如下:
. ├── bin # 相应的脚本中也有具体启动参数说明介绍,在此不再敖述 │ ├── run.bat #windows下启动脚本 │ └── run.sh #Linux下启动脚本 └── seimi ├── classes #Crawler工程业务类及相关配置文件目录 └── lib #工程依赖包目录 接下来就可以直接用来分发与部署了。
详细请继续参阅 maven-seimicrawler-plugin
更多文档
目前可以参考demo工程中的样例,基本包含了主要的特性用法。更为细致的文档移步 SeimiCrawler主页 中进一步查看
社区讨论
大家有什么问题或建议现在都可以选择通过下面的邮件列表讨论,首次发言前需先订阅并等待审核通过(主要用来屏蔽广告宣传等)
-
订阅:请发邮件到
seimicrawler+subscribe@googlegroups.com -
发言:请发邮件到
seimicrawler@googlegroups.com -
退订:请发邮件至
seimicrawler+unsubscribe@googlegroups.com -
QQ群:
557410934

这个就是给大家自由沟通啦
- 微信订阅号

里面会发布一些使用案例等文章,以及seimi体系相关项目的最新更新动态等。
Change log
v1.0.0
- http请求处理器重构,并默认改由
okhttp3实现,且支持通过@Crawler注解中的httpType自由切换为apache httpclient - 部分代码优化
- 支持通过seimiAgent获取页面快照(png/pdf)
这一版是SeimiCrawler比较重大的一次更新,伴之而来的亦是更强悍的抓取体验。
v0.3.2
- 优化分布式模式下与redis的连接,增强分布式可靠性
- bug fix
v0.3.0
- 内置支持SeimiAgent,完美解决动态页面渲染抓取问题
- 修复自动跳转在某些情况存在的bug
v0.2.7
- 内嵌http接口在可以接收单个Json形式Request基础上增加支持接收Json数组形式的多个Request
-
Request对象支持设置skipDuplicateFilter用来告诉seimi处理器跳过去重机制,默认不跳过 - 增加定时调度使用Demo
- 回调函数通过Request传递自定义参数值类型由Object改为String,方便明确处理
- Fix:修复一个打日志的bug
v0.2.6
- 增加统一的启动入口类,配合未来SeimiCrawler的maven构建plugin一起使用
- meta refresh方式跳转优化,设置最多上限为3次,防止遇到持续刷新页面无法跳出
- bug fix:修复在Request中自定义数据无法传向Response的问题
v0.2.5
- 增加请求遭遇严重异常时重新打回队列处理机制 当一个请求在经历网络请求异常的重试机制后依然出现非预期异常,那么这个请求会在不超过开发者设置的或是默认的最大重新处理次数的情况下被打回队列重新等待被处理,如果被打回次数达到了最大限制,那么seimi会调用开发者自行覆盖实现的
BaseSeimiCrawler.handleErrorRequest(Request request)来处理记录这个异常的请求。重新打回等待处理机制配合delay功能使用可以在很大程度上避免因访问站点的反爬虫策略引起的请求处理异常,并丢失请求的记录的情况。 - 优化去重判断
- 优化不规范页面的编码获取方式
v0.2.4
- 自动跳转增强,除301,302外增加支持识别通过meta refresh方式的页面跳转
-
Response对象增加通过getRealUrl()获取内容对应重定向以及跳转后的真实连接 - 通过注解@Crawler中'useUnrepeated'属性控制是否启用系统级去重机制,默认开启
v0.2.3
- 支持自定义动态代理 开发者可以通过覆盖
BaseSeimiCrawler.proxy()来自行决定每次请求所使用的代理,覆盖该方法并返回有效代理地址则@Crawler中proxy属性失效。 - 添加动态代理,动态User-Agent使用demo
v0.2.2
- 增强对不规范网页的编码识别与兼容能力
v0.2.1
- 优化黑白名单正则过滤机制
v0.2.0
- 增加支持内嵌http服务API提交json格式的Request请求
- 增加针对请求URL进行校验的
allowRules和denyRules的自定义设置,即白名单规则和黑名单规则,格式均为正则表达式。默认为null不进行检查 - 增加对Request的合法性的统一校验
- 增加支持请求间的delay时间设置
项目源码
Github
BTW:如果您觉着这个项目不错,到github上 star 一下,我是不介意的 ^_^
正文到此结束
- 本文标签: js build 调试 maven构建 CTO java pom 敏捷 cat src API plugin Document 服务器 Chrome, QQ群 开发者 文章 时间 spring maven Chrome 广告 lib IDE 处理器 解析 站点 https 开发 UI python 代码 目录 windows list tar dist redis QtWebkit jsoup web git 参数 配置 ACE GitHub 正则表达式 json 源码 client 数据 SeimiAgent HTML apache ip 插件 集群 http Google linux URLs 协议
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

