专访阿里云高级专家赵林:从0到1,中间件的研发运维之路
早期的中间件,起源于1968年IBM的CICS(Customer Information Control System )交易事务控制系统,是一个分布式的文件服务用来管理用户信息。中间件,英文名为Middleware,它提供应用层和系统层之间连接,是应用层实现系统资源集中调用的抽象逻辑,同时协调各个应用之间的沟通;并且自动处理分布式系统中的常见异常,最终简化大规模分布式应用的编写。
伴随着互联网发展和分布式系统的兴起,中间件的概念也在发生演变。在分布式网络环境下,中间件面临更复杂的情况:如何解决众多应用复杂依赖的问题?如何屏蔽分布式系统的技术细节?新时代的基础中间件会追求更高性能、更强的可用性和扩展性。同时,在基础中间件基础之上,需要建立分布式系统的数据化运营能力,以及整个业务系统的高可用架构设计能力。
互联网时代,大多数企业都面临着IT构架转型的阵痛。一方面,业务创新受阻:传统构架建设周期长,信息孤岛现象严重;另一方面,系统处理能力有限:如果业务发展起来,传统的集中式系统很难及时扩容,导致无法处理不断增长的并发量。分布式系统将成为不可回避的选择。
为什么阿里云把中间件作为进入企业级市场的重要武器?InfoQ就中间件的技术实现对阿里中间件高级产品专家赵林进行了采访。
受访嘉宾介绍
赵林,花名丹臣,中间件高级产品专家。2006年加入淘宝,负责淘宝产品DBA团队,维护淘宝生产数据库;2009年开始推动和设计了淘宝许多核心业务的去IOE历程; 2012年转岗到中间件团队,从0到1建立起中间件云产品团队,主导了一系列的中间件产品上云及商业化,完成了一些重要客户项目的业务拓展和项目支持。
InfoQ:可以简要介绍下阿里中间件的研发初衷和历程吗?
赵林:阿里在2003年-2006年的时候是单机的集中式的系统,采用的是IOE架构(IBM、Oracle和EMC)。随着业务的发展,传统构架的弊端逐渐显现:上线慢(高端设备的采购周期长、不能快速扩容),故障多(高并发的情况下系统的稳定性出现了多起严重的故障),成本高。技术不能束缚业务的发展,为了改变现状,2008年-2010年阿里研发基础分布式中间件三大产品,大大提升阿里的业务研发团队构建分布式系统的效率。我在阿里工作十年,前五年负责维护淘宝核心数据库,见证了淘宝从只有三个数据库演化为现在的几千个数据库;近五年都在做中间件,目前负责中间件的云产品团队。
在研究分布式系统问题域的时候,我们是从分布式系统基础中间件开始入手的。当时业界对中间件的认知和今天还不一样,可供参考的资料非常少。在2007年到2008年,我们研发了三个最早的中间件:
- RPC远程过程调用框架
初期是一个比较简单的框架,后期改进成现在的HSF框架支撑了生产环境所有系统的服务化调用。目前阿里云HSF服务框架采用了去“中心化”的系统架构,服务的提供者和调用者都直接相连,不仅去除了中心单点的风险,还能大大提高调用效率。峰值时,每分钟调用次数可以达到25亿次。 - MQ消息中间件
在传统的拓扑结构中,系统不同业务之间的依赖性过强过多。举例说明:如交易拍照、发旺旺消息等业务,依赖于下订单这个业务;数据处理流需要经过不同的业务模块,一旦其中某个模块出现问题,就会有整个网站下不了单的风险。加入消息中间件后,处理流程发生了改变:不同模块之间无直接关联,通过消息订阅的方式获取信息。交易中心只负责下订单写数据库操作,其他中心则只需订阅交易中心的消息。这很大程度上提升了分布式系统的健壮性。 -
分布式数据库
分布式系统中会有很多很小的数据库。为了减少上层应用开发难度,需要屏蔽底层数据库的形态,使得应用系统开发人员无需额外留意这些细节。设计分布式数据库需要注意三点:
- 业务拆分:根据系统的业务特性,拆分业务核心表数据,其中Partition Key的选择很重要。需要找到最适合自己的拆分方案。
- 拆分数量: 如何确定数据库和表的拆分个数?一方面需要判断业务能力的现状,这需要基于当前单个分库的业务处理能力;另一方面需要预估将来的业务,为扩展做准备。
- 存储方式:对数据库类型的选择,是常见关系型数据库(如MySQL),还是NoSQL非关系型数据库(如HBase)?数据是否可以采用高压缩存储以降低存储成本?(如日志数据、历史数据、物联网数据等,便可以采用高压缩存储)。根据不同的业务场景,选择不同的数据存储。如果业务场景于存储产品的技术特性非常契合,那么系统就可以发挥出最好的特性。
InfoQ:在中间件研发过程中,开源技术起到怎样的作用?
赵林:淘宝早期没有直接构建分布式系统有两个原因,一是自身技术积累不够,优先发展业务为主 ; 二是因为当时外界没有什么开源技术可以用。开源技术在分布式系统构建初期帮助很大;而如果后期业务发展起来了,则需要对开源产品有更多的掌控能力,最后就回归到自主研发的能力上来。
在我看来分布式系统分为三个层次:
- 简单的非大规模分布式系统
运用开源技术可以构建一个简单的分布式系统。 - 数据化运营的大规模分布式系统
构建一个更大规模的分布式系统,必须就进行数据化运营。目前大家都在讲业务如何数据化运营,其实分布式系统也需要数据化运营。第一种层次那种简单的分布式系统,近乎一个黑盒子:我们不知道它是怎么运行的,一旦出现问题,就是黑暗世界的降临。早期时,阿里的数据化运营很基础很粗糙,比如会做一个产品统计各个主要接口的访问量或者交易数据,然后与前一天的数据进行对比判断系统有没有出现问题;后期我们又将它做为实时的。数据化的好处是你可以清晰地感知变化,这对于淘宝这样大体量的公司来讲很重要,轻微的数字浮动就是很大的影响。 - 高效运维可精确定位问题的分布式系统
数据化运营可以及时发现系统问题;那么接下来如何改进这些问题,维护如此庞大系统?这时就需要借助于运维,在出现问题的时候,团队可以心里不慌,可以快速定位问题根源。我们实现了全链路跟踪系统:实现所有服务各个模块端到端的数据采集,为各个产品建立全链路的监控。(相关详情可参见2014年的 阿里云监控体系现状概览 一文。)
很多阿里自主研发的中间件现在是开源的。比如,远程过程调用Dubbo、中间件消息RocketMQ和分布式数据库Cobar等。阿里技术氛围是很开放,大家也可以看到阿里在国内外做了很多的技术分享。
InfoQ:您刚才提到了阿里云实现了全链路跟踪,最开始是怎么会想到研发分布式系统的全链路跟踪?系统实现高效运维是得益于此吗?
赵林:最早时基础中间件这一层是没有运维的,但在内部场景使用中遇到了好多问题,于是就开始开发越来越多的组件进行运维监控,组件慢慢沉淀下来就和我们中间件融合在一起。如果没有这些运维模块的话;系统是没有办法支撑起阿里如此多如此广的内部业务的,更无法谈及上云之后服务众多大中小企业。现在,经过这么多场景的历练,中间件产品已经很完整了,这层运维做得好、易用且成本低。
全链路跟踪,即从入口处开始到流经的所有系统的所有节点,都通过可视化的方式串起来。这样可以快速定位系统出现了哪些问题。
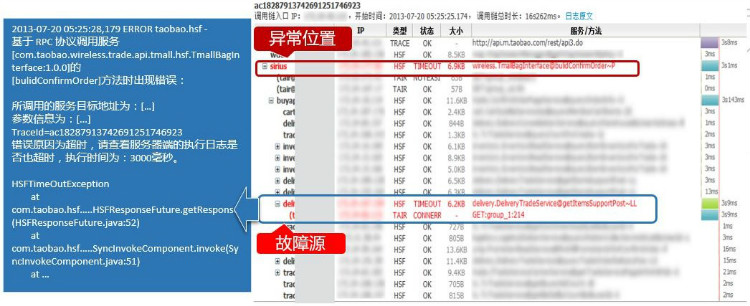
关于系统高效运维,这里再拿消息中间件的消息轨迹追踪举例:从消息的发送开始,它发到哪些topic,有哪些订阅方,订阅方有哪些机器,被哪些机器消费,最终是消费成功还是失败。如果有机器消费失败,需要再次投递到所在集群中的另外一个机器上去,直到集群中至少一台机器消费成功,才会停止投递。如果一直投递失败,就会按照一定的策略进行不断地降级投递服务。
不过,对于企业级互联网架构,只有全链路跟踪系统是不够的,还需要一个自助式的在线压测系统。如果在开发的时候做压测,得到的结果数据不是真实的,因为这个和实际的生产环境是不一样的。我们需要压测平台与中间件基础设施相结合,自动去导流量,用它去推测每个接口每个节点到底能够实现多大的业务能力,最后再清晰地算出来结果:以这个科学数字的方式合理分布资源,告知各个业务线当前业务量是多少,是否需要对一些应用进行扩容或者缩容。
InfoQ:对各个应用组件进行全链路的监控,这意味每一个产品在开发时都要实现运维部分?
赵林:是的,基础中间件都是自带运维的。比如MQ消息中间件,这是一个很广泛的产品。阿里的创新点在于实现了消息轨道追踪。消息的产生和投递、发送消息的中间件、最终投递的各个消费方、投递到消费方的哪台机器、投递次数和结果,都会清晰地显示出来。这些链路工具和MQ中间件是组合在一起,放在阿里云上提供给用户,这样用户的体验才是完整的。
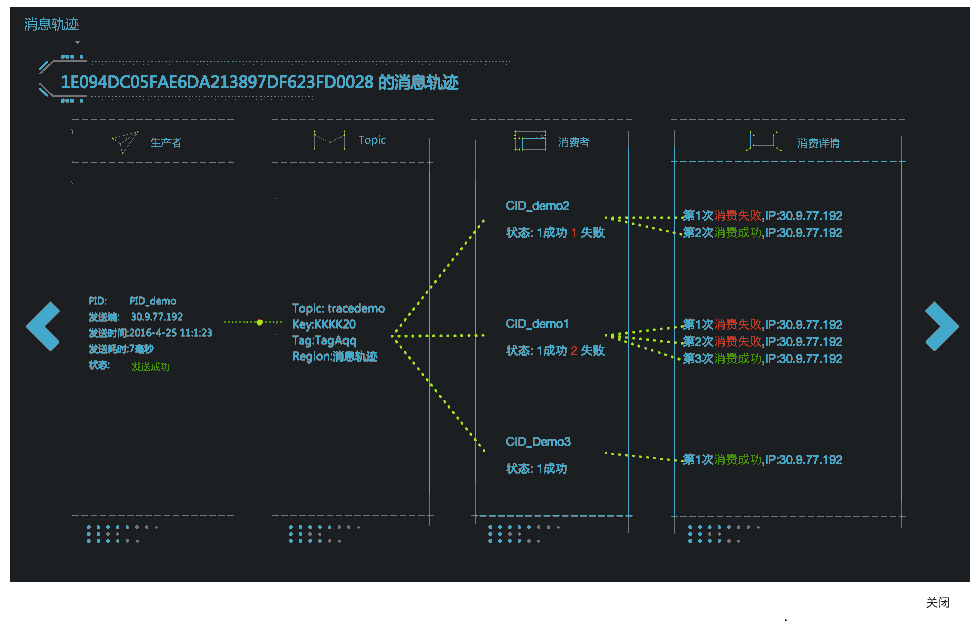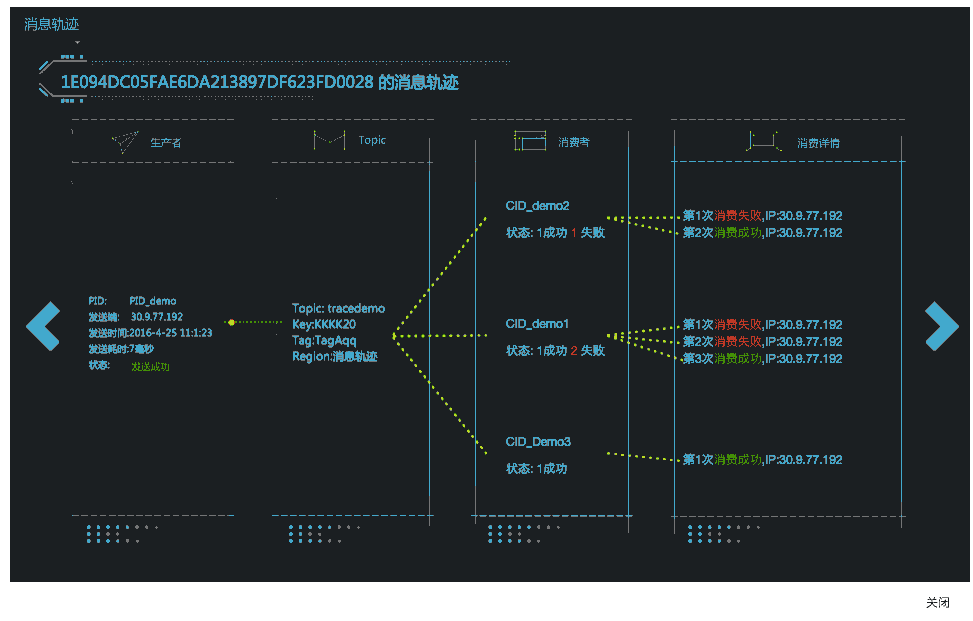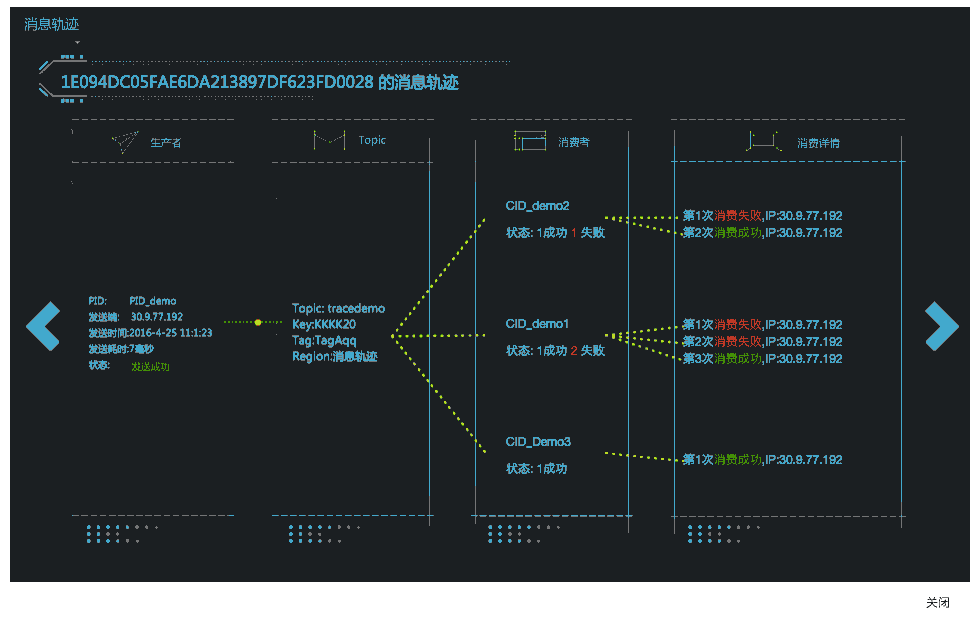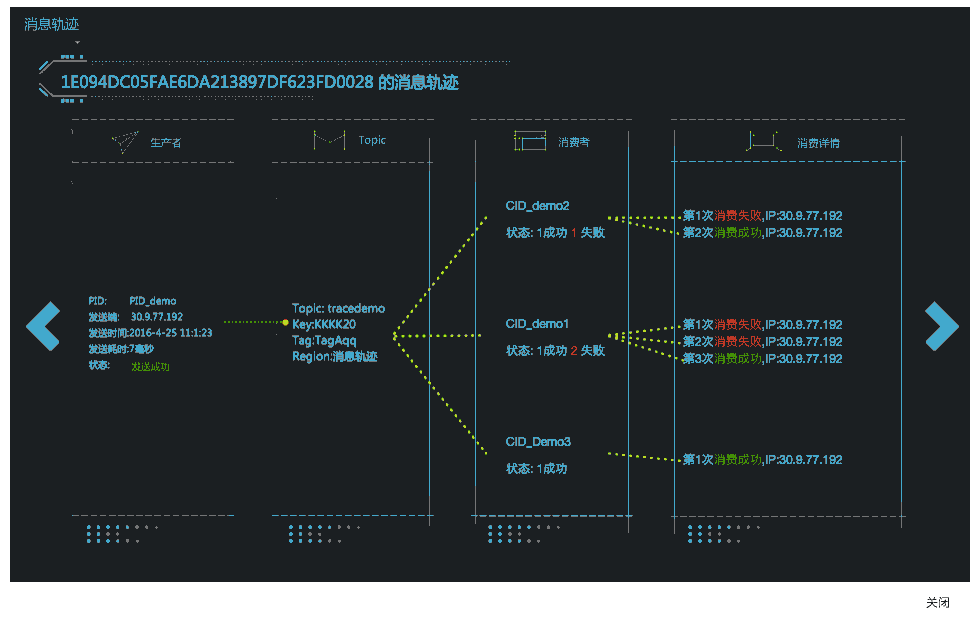
换个角度来讲,这也是阿里中间件都变成了云服务的必要条件。否则的话:一、根本无法知道问题出现在哪里;二、客户不能每次出现问题都来找我们,不能为每个客户都配备一个中间件技术专家。一个技术产品要真正变成一个云服务,方方面面都是要做细的,要让其完整并成为真正的应用服务。如果每个客户使用过程中小小的问题还需要和产品研发团队交互;那么这就是能力很弱的产品,它不能去服务越来越多的客户。
InfoQ:那阿里采用的是将开发和运维融合在一起的DevOps文化吗?
赵林:这是必须的,因为我们有太多的场景需要这个能力。我知道现在很多的大公司,基本上开发和运维还是分开的,阿里几年前也是这样的,但是现在我们在融合各个团队实现DevOps。
做产品研发,不是说只做个App就大功告成了,因为服务端还不具有这样的能力。服务端去改起来还是很麻烦的。应用集群变大之后,如果一个应用有成百上千台机器的时候,连一个简单的发布都是个问题。快速发布、快速回滚,有可能需要半天或者一天,这是一个非常现实的问题。如果想发布应用,那就必须把应用的所有管理和监控都做出来。
产品功能开发出来就需要运维,不能丢给别人去运维;其对应的运维工具本来是一个产品不可或缺的部分。打个比方,这好比生孩子容易,养孩子难。通常在开发团队在自己维护的过程中,遇到一次什么样的故障,知道整个系统中有哪里需要补,这里是不是需要加一个端对端的全天候监控,那里是不是需要补一个权限漏洞:就这样一点点地形成一个更加丰富完整的体系。真正把一个系统给运维好是需要很深厚的功力,开发运维那些周边工具所花的时间精力,很可能比研发中间件核心花的时间还要多很多。
InfoQ:阿里云的企业级互联网构架图中,在中间件的业务能力这一层,业务服务被分成了不同的模块。这些模块的拆分是出于什么考虑呢?
赵林:2008年之前业务发展很快,没有更多的研发力量投入到基础技术的研究当中。那个时候是怎样实现更快,就怎样做。
后来开始一点点将不同的业务中心拆分出来。拆分业务时,需要特别警惕一种做法:核心应用错误地依赖非核心应用,这会导致本来应该有的弱依赖成为强依赖。我建议所有的分布式系统,都应该最先拆分用户中心。现在很多公司的系统仍然没有独立用户这一块,他们面临着和阿里当初的一样的情况:在建立分布式系统时,可能各个模块都在连接底层的用户库。这时其实用户的数据安全是没有办法保障的。因为,一无法知道谁改变了用户数据、改得有没有问题;二如果有问题,想去查也不知道怎么查。
2007年我们拆分了用户中心。用户中心统一接管用户数据的所有访问,其他系统不允许连接用户数据库。此外,将用户中心独立出来,也可以做缓存等性能上的统一优化,省去了上层优化的成本。这同时解决了安全和性能的两方面问题。
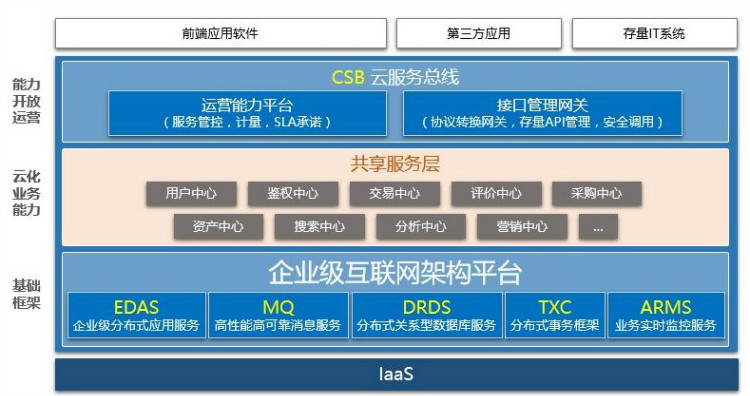
从最开始时只有两个业务系统,然后一个一个地拆分业务应用,到最后有几千个应用。在有几千个应用的时候,应用之间依赖是很复杂的,业务系统交互的流程图是画不出来的。同时随着研发人员增多,开发代码的维护也增加了不可控性。如何管理这样的系统变成了一个新的挑战,如果能把这个问题处理好了,那么我认为分布式系统一定变成个很好的东西,它可以并且一定会支撑更大的业务量。
InfoQ:几千个应用,是怎样实现持续性部署?是基于Docker做到的吗?
赵林:关于持续性部署与Docker之间关系的问题:一方面,我们中间件本身的部署,支持Docker化的部署,但是同时也支持物理机和虚拟机的部署。而另一方面,对于用户的应用,采用的是与Jenkins、SVN等工具的无缝对接,完成研发各个环节的持续集成。阿里云提供的企业级分布式应用服务EDAS,可以支持用户应用的Docker化部署。此外,为了提高开发者体验和研发效率,我们提供了许多插件。例如改变代码无需重启就可以立刻生效,这对于一些大应用的研发格外重要。
关于Docker:客观上讲,Docker只能解决一些最基本的应用部署和监控问题;但是如果你真正要把一个大型分布式系统构建并且运营起来,就需要自主研发的中间件或者利用一些成熟的开源中间件产品,因为Docker本身并不能解决这些问题。
InfoQ:研发接下来努力的方向是什么呢?
赵林:提高系统的效率。当规模小、服务器比较少的时候,优化效果不是很明显;但是当机器达到十万台以上规模的时候,优化10%就是优化了一万台机器,这就意味着可以为公司节省下来好几个亿的成本。现在很多公司不管是在线业务还是离线业务,服务器处于空跑阶段是很常见的问题。
因此利用技术手段提高资源的利用率,就成了我们一个非常重要的课题。国外像谷歌这样的公司,他们的机器利用率很高,可以达到40%-50%;我们总体上还是比他们落后一些,我们会继续不断地提高存储和计算效率。
感谢郭蕾对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

