哈夫曼编码 —— Lisp 与 Python 实现
SICP 第二章主讲对数据的抽象,可以简单地理解为 Lisp 语言的数据结构。当然这样理解只可作为一种过渡,因为 Lisp 中并不存在数据与过程的差别,也就完全不需要一个额外的概念来描述这种对数据抽象的过程。 2.3.4 以哈弗曼编码为例展示了如何在 Lisp 中实现哈夫曼二叉树数据结构的表示与操作,本文在完成该小节习题(完整的哈夫曼编码树生成、解码与编码)的基础上,将 Lisp(这里用的是 DrRacket 的 #lang sicp 模式,即近似于 Scheme )与 Python 版本的程序进行对比。
1. 哈夫曼树
哈夫曼编码基于加权二叉树,在 Python 中表示哈夫曼树:
class Node(object): def __init__(self, symbol='', weight=0): self.left = None self.right = None self.symbol = symbol # 符号 self.weight = weight # 权重 Lisp 通过列表(List)表示:
(define (make-leaf symbol weight) (list 'leaf symbol weight)) (define (make-tree left right) (list left right (append (symbols left) (symbols right)) ; 将叶子的字符缓存在根节点 (+ (weight left) (weight right))) ) ;; methods (define (leaf? object) (eq? (car object) 'leaf)) (define (symbol-leaf leaf) (cadr leaf)) (define (weight-leaf leaf) (caddr leaf)) (define (symbols tree) (if (leaf? tree) (list (symbol-leaf tree)) (caddr tree))) (define (weight tree) (if (leaf? tree) (weight-leaf tree) (cadddr tree))) 2. 哈夫曼算法
为了生成最优二叉树,哈夫曼编码以字符出现的频率作为权重,每次选择目前权重最小的两个节点作为生成二叉树的左右分支,并将权重之和作为根节点的权重,按照这一贪婪算法,自底向上生成一棵带权路径长度最短的二叉树。
依据这一算法,可以从“字符-频率”的统计信息中建立一棵哈夫曼树,在 Python 实现中,只需要每次对所有节点重新按照权重排序即可:
# frequency = {'a': 1, 'b': 3, 'c': 2} def huffman_tree(frequency): SIZE = len(frequency) nodes = [Node(char, frequency.get(char)) for char in frequency.keys()] for _ in range(SIZE - 1): nodes.sort(key=lambda n: n.weight) # 对所有节点按照权重重新排序 left = nodes.pop(0) right = nodes.pop(0) parent = Node('', left.weight + right.weight) parent.left = left parent.right = right nodes.append(parent) return nodes.pop() Lisp 通常采用递归的过程完成循环操作,一种类似插入排序的有序集合实现如下:
(define (adjoin-set x set) (cond ((null? set) (list x)) ((< (weight x) (weight (car set))) (cons x set)) (else (cons (car set) (adjoin-set x (cdr set)))))) 下面这段与 Python 列表推断功能相似的过程,这也许可以让你更加感受到 Python 的简洁与美妙:
(define (make-leaf-set pairs) (if (null? pairs) '() (let ((pair (car pairs))) (adjoin-set (make-leaf (car pair) (cadr pair)) (make-leaf-set (cdr pairs)))))) 最后,基于“字符-频率”的有序集合生成哈夫曼编码树:
(define (generate-huffman-tree pairs) (define (successive-merge leaf-set) (cond ((null? leaf-set) '()) ((null? (cdr leaf-set)) (car leaf-set)) (else (successive-merge (adjoin-set (make-code-tree (car leaf-set) (cadr leaf-set)) (cddr leaf-set)))) )) (successive-merge (make-leaf-set pairs))) 3. 编码与解码
有了哈夫曼树之后,可以进行编码和解码。编码过程需要找到字符所在的叶子节点,以及从根节点到该叶子节点的路径,每次经过左子树搜索记作 "0" ,经过右子树记作 "1" ,因此可以利用二叉树的先序遍历,递归地找到叶子节点和路径:
def encode(symbol, tree): bits = None def preOrder(tree, path): if tree.left: preOrder(tree.left, path + "0") if tree.right: preOrder(tree.right, path + "1") if tree.isLeaf() and tree.symbol == symbol: nonlocal bits bits = path preOrder(tree, "") return bits Lisp 的二叉树中每层根节点缓存了所有子树中的出现的字符,以空间换取时间:
(define (left-branch tree) (car tree)) (define (right-branch tree) (cadr tree)) (define (encode-symbol char tree) (cond ((null? char) '()) ((leaf? tree) '()) ((memq char (symbols (left-branch tree))) (cons 0 (encode-symbol char (left-branch tree)))) ((memq char (symbols (right-branch tree))) (cons 1 (encode-symbol char (right-branch tree)))) (else (display "Error encoding char ")))) 解码过程更直接一些,只要遵循遇到 "0" 取左子树,遇到 "1" 取右子树的规则即可:
def decode(bits, tree): result = "" root = tree for bit in bits: if bit == "0": node = root.left elif bit == "1": node = root.right else: return "Code error: {}".format(bit) if node.isLeaf(): result += node.symbol root = tree else: root = node return result 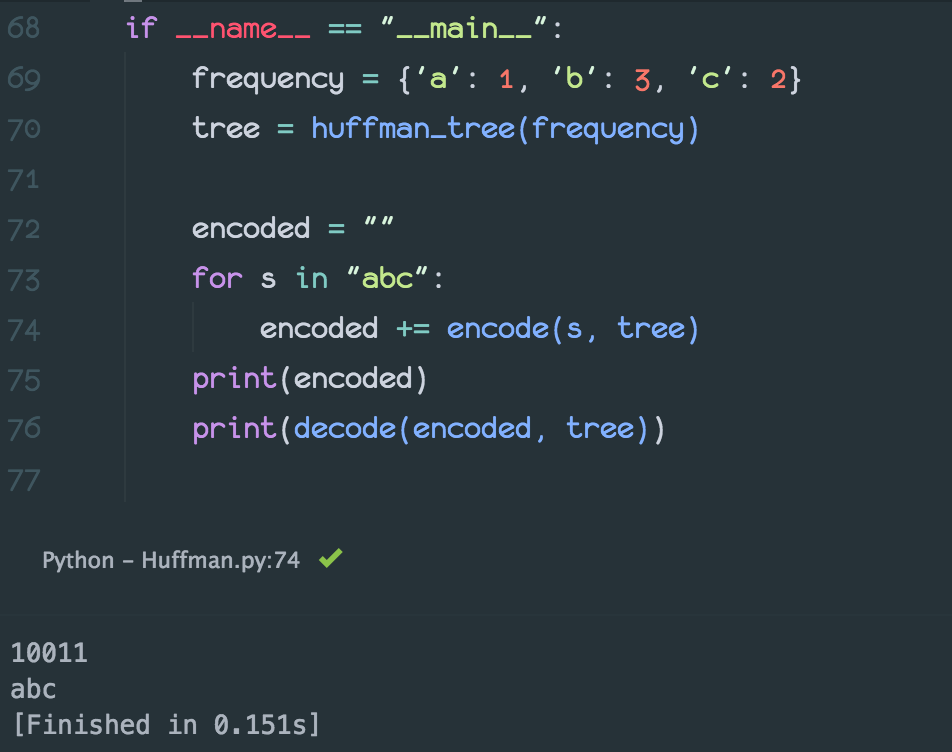
(define (choose-branch bit branch) (cond ((= bit 0) (left-branch branch)) ((= bit 1) (right-branch branch)) (else (display "bat bit: CHOOSE-BRANCH" bit)))) (define (decode bits tree) (define (decode-1 bits current-branch) (if (null? bits) '() (let ((next-branch (choose-branch (car bits) current-branch))) (if (leaf? next-branch) (cons (symbol-leaf next-branch) (decode-1 (cdr bits) tree)) (decode-1 (cdr bits) next-branch))))) (decode-1 bits tree)) 
需要注意的是上面的算法并不能保证每次生成的哈夫曼树都是唯一的,因为可能出现权值相等以及左右子树分配的问题,但是对于同一棵树,编码和解码的结果是互通的。
4. 总结
虽然未必会用到 Lisp 作为开发语言,但并不妨碍我们学习、吸收其中优秀的思想。SICP 前两章分别介绍了对过程的抽象和对数据的抽象,其中一个重要的思想就是编码的本质是对计算过程的描述,而这种描述并不拘泥于某种特定的语法或数据结构;对过程的抽象(例如 (define (add a b) (+ a b)) )与对数据的抽象(例如 (define (make-leaf symbol weight) (list 'leaf symbol weight)) )之间并没有本质的差异。
Python 在确保简介、优雅的同时也拥有惊人的灵活性,我们甚至可以模仿 Scheme 的语法来完成上面的所有程序:
def make-leaf(symbol, weight): return ['leaf', symbol, weight] def leaf?(obj): return obj[0] == 'leaf' 虽然像上面这样做毫无意义,但是将对过程的描述抽象到函数层面,然后对函数进行操作的思想在 Python 中同样非常重要。
上面的代码大部分是在旅途中的火车或汽车上完成的,少有这样的机会体验一下离线编程的“乐趣”, sort 和 nonlocal 的用法还要多亏写 PyTips 时的总结,因此还是希望有时间可以写满 0xFF 。
Python , SICP , 算法
- END -
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

