相关搜索 --- 离线和在线的结合
前面说了相关搜索底层的算法逻辑,本篇会继续以相关搜索为例子介绍一下相关搜索的的在线部分架构和一种常规的算法类系统的工程化方式。
0. 前面的话
在说正题之前还是先来闲扯一下,都说产品经理的想象和最后工程师的实现之间差了十万八千里,同样的,算法的模型和最后的工程化部分也是差了十万八千里。看到一个好的算法的论文,一看卧槽这么牛逼,感觉能解决一切问题,于是想尽一切办法想要用到系统中,发现实现的过程中坑无数,这样的例子数不胜数。
比如说推荐系统中经常使用的SVD矩阵分解,看上去很美好,但是实际工程化中发现计算量实在是太大,大数据规模下计算量特别大,算出来以后调个参数,又几天过去了,这样的话,需要快速上一个算法项目很难的,论文的算法很多是没考虑工程化情况的,虽然现在有hadoop,有spark,但是有些算法真算起来还是很耗时间的,所以对算法的改进很重要。
拿到一个算法,对算法的评估很重要,而且需要找到一个能够快速验证算法有效性的方法,不至于做无用功,最好的评估办法是什么呢?呵呵,就是使用成熟的算法,大家都用过的,效果总不至于太差,比如 协同过滤 这种推荐算法,用了这么多年了,工程应用也很多,怎么也不会太差。
本篇是 相关搜索 的整体设计,我会从 算法预研,算法选择和评估,离线算法设计,在线服务设计,整体设计,工程化实现 几个部分来说说一个包含算法的系统的工程化实现过程。
1. 算法预研
其实上一篇【相关搜索】介绍的那些个算法就算是算法预研了,算法的预研实际上是比较考验经验和技术实力的。
-
首先,你需要有一定的技术积累,你才知道哪些个算法和方法可以解决目前的这个问题,像上一篇的很多相关的算法,比如
协同过滤,文本相似性计算,word2vec词向量这些东西,是需要平时的积累和理解才能知道是否能用在目前的这个场景中的。 -
其次,如果有相关的经验的话那就更省事一点了,现在的互联网的技术栈,哪怕是这类算法类的技术栈,也基本上是有人实现过的,很少能看到一个完全全新的领域需要你去做,所以如果有相关的经验的话,预研阶段肯定是事半功倍了。
-
一般情况下,预研阶段还需要查阅一些资料或者论文,上网搜一搜别人都怎么做的,然后总结出来一些个方法,这些就是你预研阶段的成果了。拿着这些东西到下一步做进一层的选择了。
预研阶段一般不需要写代码,大概想想这个算法的模型就差不多了,也就说在这个阶段,你的脑子里面应该有各种算法的模型可供下一步的选择。
2. 算法选择和评估
预研阶段会得到一批备选的技术方案,在这一步的评估阶段就要对这些算法进行更加深层一点的评估了,找到最适合当前场景的技术方案,然后写一些代码来帮助进行评估,比如对于 相关搜索 ,我们在预研阶段已经找到了一些技术方案,假设我们找到了 通过后继词直接匹配 , 通过搜索词协同过滤 , 通过点击的结果集协同过滤 , 通过后继词的word2vec方法 这四个方案,如何来选择呢?
-
成本,作为一个工程项目,成本永远是不可忽视的部分,工程项目不像科研项目可以不计成本的进行研究,工程项目都是有最后期限的,所以成本就显得很重要了,上面四个方案中。
-
第一个的成本最低,基本上就是一个统计逻辑
-
第二个和第三个稍微复杂点,需要实现一下协同过滤算法,但这个算法本身还是很容易的,所以成本稍微比第一个高一点。
-
第四个方案如果没有现成的代码库可用的话,成本是最高的,因为你必须先彻底的了解word2vec这套算法,这套算法不是像协同过滤那么简单就可以了解的,然后还需要实现它,并且还要保证正确性,最后实现出来还要保证性能,这实际上是很难的。
-
-
工程化可能性,就是这些个算法有没有工程化的可能性或者说好不好进行工程化,在这里的四个技术方案,都是可以方便的进行工程化的,所以在
相关搜索中,不存在这个工程化可能性的问题,但是在有一些项目中,真会遇到算法无法进行工程化的情况,无法进行工程化的情况很多,经常遇到的就是计算资源不够,比如你在一小公司,一共就那么几台小内存的云主机,你一定要弄一个牛逼的算法,算法中有很多大矩阵相乘的运算,这种就属于不可能工程化的情况,还有就是你的团队技术能力不够,无法把一个复杂的算法进行工程化的编程,别说,这种情况也不占少数,现在是有各种各样的开源算法库支持,把开发的难度降低了不少,不然有些复杂算法实现起来还是比较困难的。 -
效果预估,这个是最难的,因为算法类的系统,除非你之前做过类似的系统,不到最后上线以后A/B测试,都不知道效果会如何。这里我们粗略的估计一下
-
通过后继词直接匹配,由于单个用户的数据毕竟有限,随机性太强,所以直接使用这个的话,估计效果不会太好。
-
后面两个协同过滤中,用户的点击数据不管怎么说,都比直接使用结果集要靠谱点吧,因为用户的点击行为多少代表了用户当时场景下的意图,所以第三个方案
通过结果集的协同过滤比较好一点 -
而第四个方案属于把
word2vec进行了一下领域的改变,所以效果好不好不太好直观感觉,这个只有做了才知道好不好。
-
通过之前的成本评估,虽然 word2vec 的方案实现起来很复杂,但是目前有针对这个的开源实现,所以对于 word2vec 而言,开发成本没那么高,可以放入考虑中,这么算下来,最后确定使用 通过结果集的协同过滤 和 word2vec 两个方案进行系统开发。
3. 离线算法设计
确定好算法以后,就要开始漫漫的离线算法设计之路了,其实离线算法设计基本上算工程化的一部分了,验证的过程中整体的流程就需要设计好了,哪些需要在线处理的,哪些是离线处理的,这些在离线算法设计的阶段就要进行考虑了,主要是为了后续的架构设计更加顺畅。
算法类的系统,流程架构基本上有以下三种
-
第一种是最简单的,直接出
结果数据,然后把结果数据推到在线服务上,生成合适的数据结构,前端来的请求直接查询数据结构获取数据,返回前端,这种适用于结果集变化不是很大的情况,比如我们的相关搜索,每个人搜索关键词出来的相关搜索结果都是一样的。 -
第二种稍微复杂点,离线部分生成的除了
结果数据,还有个计算模型,把两者都推送到在线服务上,提供服务的时候除了直接获取结果以外,还需要使用计算模型在线算一下结果,对结果集进行一下微调,然后在返回前端,这种主要适用于结果集改变比较频繁的场景,比如推荐广告系统,有个初步的结果集,会根据每个用户的标签,把结果集再排排序之类的。 -
第三种只生成
计算模型,所有的结果都由在线部分实时完成,这样的场景其实不是很多,主要应用在一些个性化非常明显的场景中,比如智能问答系统,每个问题的解答实际上是根据当时的情况实时计算出来,然后再给出结果的。当然,我这里把产出归纳成
结果数据和计算模型两种,实际的情况中比这复杂一些,但基本上思想就是上面说的这样子。
好了,我们来看看相关搜索的离线算法设计部分吧。
上一节我们说了使用 通过结果集的协同过滤 和 word2vec 这两个方案,那么如何来设计这个流程完成这两个算法的验证呢?
对于数据的处理,一般有两种形式,一种是 状态机模式 ,就是根据条件在各个条件在各个状态之间跳转,还有一种是 流式处理模式 ,就是直接一步一步往下走,算法类的离线处理流程尽量做到 流式处理,树形结构 ,因为方便进行任务分配,不同人可以写不同的模块,组合起来也很容易,而且方便进行数据验证,每一步都可以单独进行验证,并且如果目前是单机的运算,数据量大了以后,也方便进行hadoop的移植,基于这个原则,我们可以按照以下图形来设计这个算法流程。

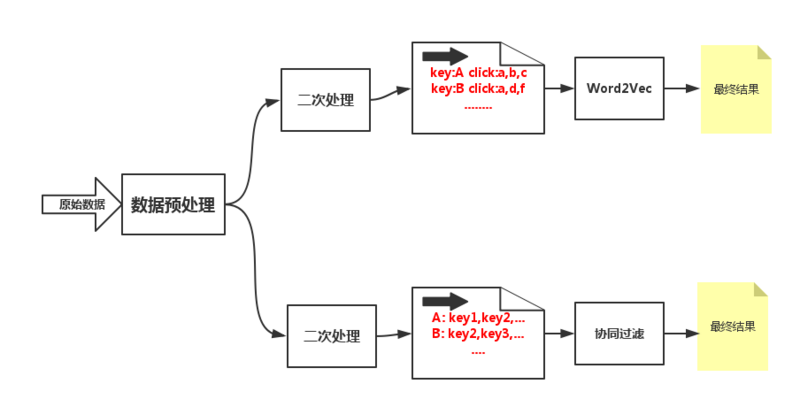
-
首先,原始数据来源需要做预处理,生成一个统一的数据结构供后续的节点使用,这个相当于原始数据。
-
从原始数据出来以后会分成两组数据进入不同的节点,下面这个节点用来做
协同过滤的,先对数据进行二次加工,上面这个节点用来做word2vec,也是对数据进行二次加工,加工成算法需要的数据格式。 -
第三层节点就是具体的算法模块了,数据按照格式要求输入,然后输出成需要的数据格式供在线平台使用。
这个流程画的比较简单,不过整个相关搜索也不复杂啦,大概的数据处理流程也就是这样子,只不过算法模块有些不同而已。
在离线算法设计这个环节中,如果你有资源,并且数据量比较大的话,当然可以直接用hadoop进行验证,也推荐这么做,毕竟这样和最后的工程化的差异比较小,如果你的资源有限,呵呵,那就本机验证吧,用类似 python mapper.py | sort | python reducer.py > res.txt 这样的脚本来验证算法吧,哈哈。。。
离线算法设计的最后产出就是最后的数据集合了,这也是最后在线部分的基础数据了。
4. 在线服务设计
离线部分设计完了,也验证了算法了,那么就得开始在线服务部分的设计了,离线部分得到的数据是一个类似KV形式的数据集合,那么很明显,最简单的在线服务就是把这一堆数据存到redis中,然后在线服务根据搜索的query在redis中查询数据返回结果就行了。
作为一个高端的设计人员,这么干显然不符合我的一贯作风啊。
-
首先,即便是离线计算出来的,也是有很多搜索词覆盖不到的,所以对这部分要在线处理一下。
-
第二,使用一个redis集群多耗资源啊,直接在本机用一个本地的kv存储就能解决,没必要上redis啊。
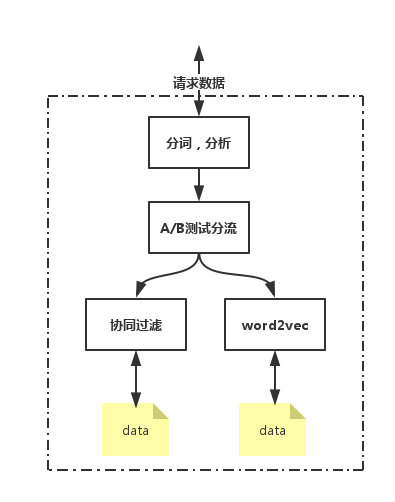
对于第一种情况,可以先分词,然后找到中心词(这部分可以在搜索的query分析统一来做),用中心词就行推荐,比如搜索 女士黄色碎花连衣裙加大码 这种搜索词,很可能因为太长尾了,没有数据支持,所以得不到相关搜索,我们可以在在线服务的时候把这个搜索词改成 女士连衣裙 ,这样就有相关搜索的推荐了,虽然相关性没那么高,但是聊胜于无吧,这种就属于在线算法部分了。
在线算法还有一个功能就是做A/B测试,看看哪种算法的效果更好,或者是一共10个结果,前5个是 协同过滤的 ,后5个是 word2vec的 ,把那种算法的结果排在前面效果更好,这种的话,通过一个流量的切分来可以看到两种算法的效果。
关于A/B测试,可以专门写一篇文章,这里简单的说一下,流量切分一般有两种,一种是和用户相关的,就是对于某一个用户,你就想让他看到A版本或者B版本;还有一种是用户无关的,只是把所有的请求流量切到A版本或者B版本。使用哪一个需要根据业务场景来决定。一般情况下,为了用户体验,都会使用用户切分的方式,因为你让一个用户先看到一种版本的结果,刷新一下页面就看到另外一个版本,总感觉怪怪的。A/B测试最基本的办法就是通过用户id取模,然后分发到不同的版本上去。
对于算法类的系统,因为是机器算出来的效果,还有一个很重要的功能就是 人工干预 了,当看到badcase以后可以迅速先解决掉,记录下badcase,积攒到一定程度,找到规律,然后再去修改算法,既然要先解决掉,那么就直接人工干预就行了,对于 相关搜索 ,人工干预也很容易,把某个搜索词的 相关搜索 推荐结果直接人填写就行了,把在线服务加一个post的请求接口就可以搞定了。
综合上面的所有因素,我们可以将在线服务设计成下面这个样子,具体就不描述了,大家看看图吧,有问题可以留言。

5. 整体设计
离线和在线部分都已经设计好了,那么把他们串起来就是整体设计了,但是整体设计的时候更多的需要考虑外围的因素了。
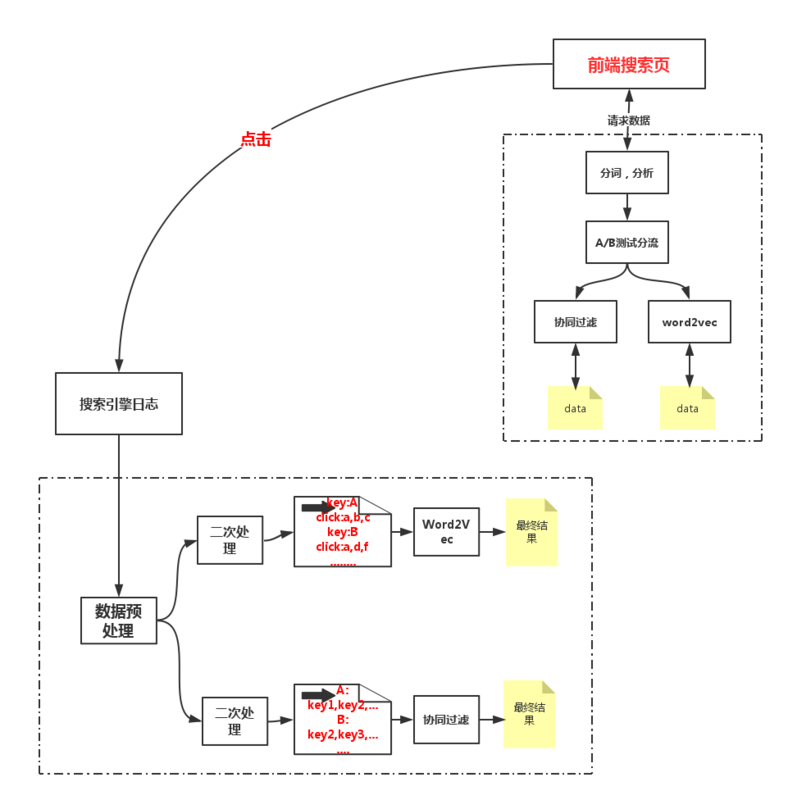
外围的因素在这里就是原始日志的收集,这一部分在离线和在线部分都没涉及到,但是真正工程化的时候是需要考虑的,比如多久整合一次日志啊,日志从什么渠道推送到离线平台啊,这些都是整体设计的时候考虑的,因为我们的系统并不需要实时计算,所以对于日志的处理,可以每天从各个服务器直接拉取了,也不需要什么 Kafka 了,直接wget过来就行了,当然,一般需要做 相关搜索 的公司,都是搜索有一定的规模了,对于日志早都有统一的处理的平台了,日志早就按时同步到HDFS上了,你只需要直接处理就行了。
整体设计中还有一个环节就是怎么把离线数据推送到在线服务中,这也是两个模块的连接点,凡是这种分为在线和离线两部分的系统都有这么一个过程,最简单的就是写个脚本 rsync 啦,别觉得low啊,rsync还是简单有效的,至少传输的时候不会出错,或者说出错的概率比你自己通过tcp传输要低得多。还有就是启一个http的服务,在线模块wget这份离线数据啊。再高端点,自己实现一个同步数据的协议来进行同步啊。
在数据传输中,也会遇到一个小坑,就是 推模型 和 拉模型 的选择,个人觉得 拉模型 比较合适,因为在线服务一般是一个集群,要是用推模型挨个去推,一个失败了还要不停的尝试从新推,推到一半失败了下次是断点续传还是从新来过也是个问题,这样会对离线端产生很多复杂逻辑,还有如果在线集群增加或者减少了机器,还需要通知到离线端,如果是 拉模型 就好多了,离线端产生了数据以后就不用管了,前面的集群爱什么时候拉取数据就什么时候拉取,离线端完全不用操心。
所以,把两个线上和线下系统串起来以后,就是下面这个样子了,可以说是 一个搜索词的轮回 ,从搜索引擎产生搜索词的日志,到最后又变成了一个个的推荐搜索词,然后这些个搜索词又可以进入到搜索日志中,继续优化这个系统。
6. 后记
一个小小的 相关搜索 ,虽然简单,但是基本上涵盖了一个算法类系统的所有部分,从算法选型,算法验证,然后是工程化过程中的离线算法部分和在线服务设计,还要包括A/B测试,在线部分和离线部分结合架构设计。
大部分的算法类系统,都有离线部分,有在线部分,两个部分各自分担一部分算法逻辑,最后把两部分结合起来就是整体的系统了,离线部分负责复杂的算法,在这一块中,你可以使用各种高端算法,各种机器学习算法,关键是要尽可能的给在线服务分担计算压力,最后要生成一个够简单的数据给在线服务,在线服务负责性能,如何能更快的响应客户的请求是这部分需要重点考虑的问题。
哦了,相关搜索部分就写完了,从头到尾应该没有什么难点,要是你,看了这个设计,能撸出代码来么?
如果你觉得不错,欢迎转发给更多人看到,也欢迎关注我的公众号,主要聊聊搜索,推荐,广告技术,还有瞎扯。。文章会在这里首先发出来:)扫描或者搜索微信号XJJ267或者搜索西加加语言就行

正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

