海量高性能列式数据库HiStore技术架构解析
HiStore是阿里中间件团队研发的数据库产品,是一款基于独特的知识网格技术的列式数据库,定位于海量数据高压缩比列式存储,是低存 储成本,低维护成本,海量数据OLAP存储引擎;有效的解决了海量数据存储的成本问题,以及在百亿数据场景下支持实时高效的多维度自 由组合的检索。
关键字: 列式,分布式,高压缩比;
一.HiStore
HiStore 专门针对OLAP应用程序进行设计和优化,在常规X86服务器上,HiStore可以在百亿数据场景下进行高性能,多维度自由组合 的adhoc查询. 相对比常规事务引擎,其查询速度提升了数倍甚至数十倍。此外HiStore完全兼容MySQL通讯协议和SQL语法,可以支持客户端 无代码修改进行迁移,并且无缝配合现有的MySQL客户端工具以及中间件数据层产品.
HiStore经过多个版本的迭代和深度定制化开发.现在HiStore各项指标(查询性能,数据装载效率)均超过原始版本,此外HiStore还增加了批量 数据Load,并发查询以及数据块复制等自研技术. 在我们团队所测试过的同类产品中(InfiniDB,Infobright等),HiStore的单机性能处于领先地位。
1.1 Histore 技术特性
- 海量数据背景: 实测单机可以支持百亿+ 数据量的秒级查询.
- 大数据量查询性能强劲、响应时间稳定.
- 支持任意字段组合(adhoc)的复杂聚合类查询.
- 数据库维护成本低, 在没有专职DBA维护索引/配置的情况下性能依然稳定.
- 低存储成本:高压缩比数据存储, 极大节省磁盘空间. 平均压缩比>10:1, 最高甚至可以达到 40:1
- 迁移成本低,无其它依赖独立部署,mysql工具及应用可直接无缝运行其上;
1.2 Histore适用场景
- 日志/事件管理系统: 日志数据存储与分析, 系统/网络安全审计记录.
- 数据仓库/数据集市: 低成本数据汇聚与存储,高性能数据导入和查询支持;
- 实时展示统计分析后数据;便于用户根据统计结果做决策。
- 大数据量的分析应用: 移动app数据存储与分析,客户行为分析,营销和广告数据.
- 物联网/机器采样数据: 传感器、射频设备等采集上报的原始样本值以]及状态信息等,用于后期统计处理.
- 关系型OLAP应用: HiStore作为一套完整的数据库系统,可以支撑与实时报表,决策管理及商业智能等海量数据相关的业务系统.
1.3 外部同类产品
- Infobright
- InfiniDB
- Pivotal Greenplum
- Amazon RedShift
- Teradata DB
- HP Vertica
- SAP HANA
- IBM Netezza
- 神舟通用,kstore
- 华为高斯DB
- 达梦数据库DM7
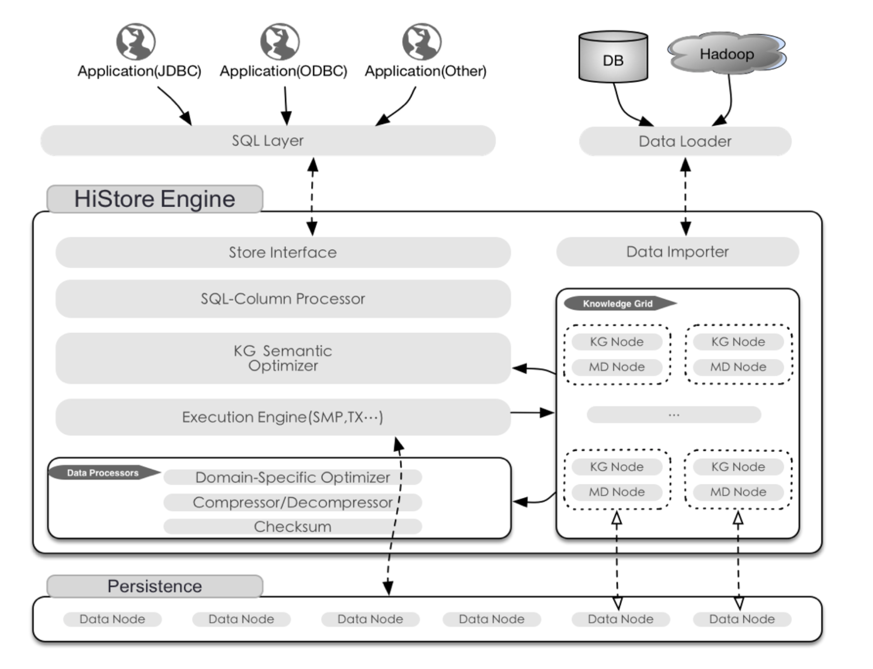
二.HiStore 技术架构
2.1 HiStore 引擎
HiStore 采用基于知识网格分析和SMP优化的列式存储引擎. 该引擎为海量数据背景下的分析型(OLAP)应用而设计, 通过列式数据存储,知 识网格过滤,高效数据压缩和并行查询等特性, 为应用提供低成本和高性能的数据查询支持.
2.2 基于列(Column)的数据存储
在描述HiStore的列存技术之前,可以先看看常见的行(row)式存储引擎的实现方式. 以MySQL为例,常见的事务引擎(InnoDB,TokuDB等)均采用基于ROW的存储模型:
-
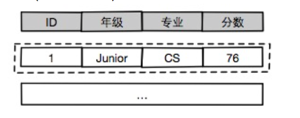
记录(Record/Row)作为数据库中最小的逻辑存储单元, 每条记录包含了Table中各列的值.
-
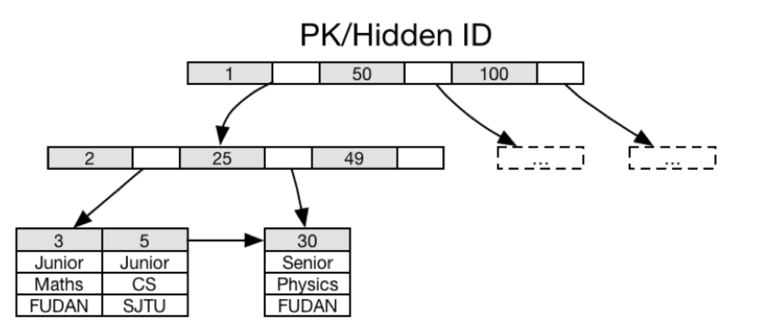
通过PK(或Hidden ID)来标识唯一Row.
-
大部分存储引擎都采用基于B+树(或其变种)的聚簇存储(即row中的相关数据会与ID存储在一起). 此时各条记录在磁盘上的存储位置是相 邻的. 数据查询时直接从磁盘读取,不需要在内存中组装数据.
-
一般而言,每条记录总数据量不宜过大, 引擎会以记录为单位在内存中进行读写.
- 数据库引擎一般通过批量预读以及缓存来提高性能.
- 在设计上要求范式化,减少冗余数据,通过多表join来构建完整视图(雪花模型).
- 采用索引(Index)来增加对特定列的查找速度.
总结一下行(row)式存储引擎的适用场景:
- 适合典型的OLTP场景:
- 活动数据集不会过多(一般小于500GB), 历史数据会归档储存.
- 细粒度事务处理(row level locking).
- 单表查询只需扫描部分数据, 一般通过多表join构建完整查询视图.
- 查询请求通常在Row中选取所有列.
- 频繁的插入或更新操作: 更新操作的成本只与索引和Row大小相关.
但是针对海量数据背景的OLAP应用,随着数据量不断增长,行(row)式存储会出现诸如查询性能,存储效率和数据库维护等一系列问题:
-
数据仓库的构建以及海量数据下的OLAP查询:
- 海量数据存储(TB ~ PB级别): 索引的维护会占用可观的资源.
- 缺少高效的压缩机制, 物理存储利用率较低.
- 常见聚簇存储,即使只需要选择部分字段,也会浪费IO操作去读取所本记录中有字段的值.
- 举例:
select sum(score) from table;假设该表中包含1M记录, 每条记录平均长度为1KB. 而 score 这个column为8字节. 在Row- based的存储中, 为了获取大概8M的数据,需要消耗大概 1GB的IO资源.
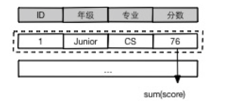
-
包含任意字段组合的
adhoc查询,需要遍历大量数据(例如多维分析型查询):- 查询的列组合不可预测, DBA无法事先增加合适的索引来增强查询性能.
-
ad-hoc查询不可避免的会造成全表扫描: why? 不可能在Row-based engine中对所有列都添加索引!
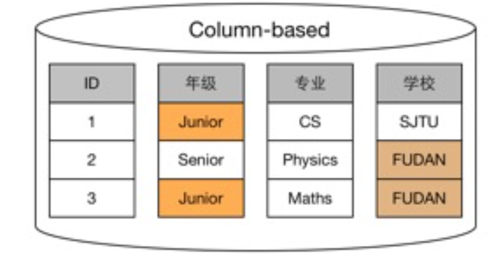
如上述所,在海量数据背景下,行(row)式存储引擎无法从引擎自身解决查询性能和维护成本等问题.与行(row)式存储不同,HiStore引擎将数据按照关系列(Column)进行存储,每列占用单独的物理存储空间,查询时在内存中高效组装各列的值,最 终形成关系记录集:
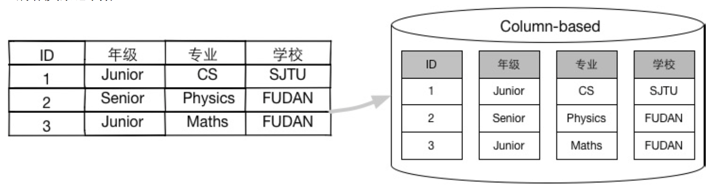
数据按照列(Column)进行存储,每个列所对应的单元值(Cell)是最小的逻辑存储单元.
- 查询过程中,针对各列的运算并发执行,最后在内存中聚合完整记录集.
- HiStore 引擎基于知识网格来在数据列中高效查找数据. 无需维护索引,支持任意Column组合的adhoc查询.
- 高效压缩支持: 因为各列独立存储,且数据类型已知. 可以进行针对该列的数据类型,数据量大小等因素动态选择压缩算法.
当数据记录按行式存储,应用程序必须读取每一条完整记录;当数据记录按列式存储,数据库只返回与部门相关的值。在分析应用程序中(不可 预测的ad-hoc查询),列式存储的方法可以显著减少IO消耗和降低查询响应时间,特别是大数据量查询和用户创建复杂即席查询的情况下:
- 海量数据下的OLAP应用(分析引擎, 报表等):
- 并发数据处理(SMP): 最大可能降低查询响应时间.
- 高效的压缩机制, 提高物理存储利用率.
- 查询过程中能够尽量减少无关IO,避免全表扫描.
-
任意列组合的adhoc 查询(BI系统等):
- 查询性能基于知识网格而不是索引, 无索引维护成本(DBA调优).
- Column-based的存储只需要访问相关列的数据即可, 显著减少所需IO资源. 适合基于关系模型实现的OLAP应用(ROLAP: 星型模 型/带字段冗余的大表).
- 基于知识网格的智能查询优化,能显著降低查询响应时间.
- 举例: select sum(score) from table; 假设该表中包含1M记录, 每条记录平均长度为1KB. 而 score 这个column为8字 节. 在列存 中, 只需要访问大概8M数据获取结果.
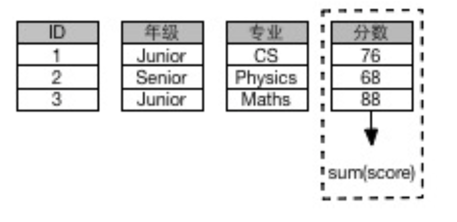
最后提一下列(Column)存的不适用场景:
- 事务交易场景: 数据需要频繁更新.
- 表中列(Column)较少,或数据量固定时(常量表), 列存并没有明显优势.
2.3 数据组织结构与知识网格
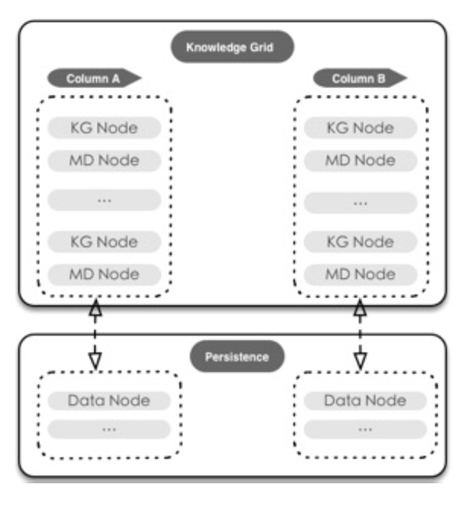
为了达到合理利用IO资源,且高效,快速查找所需数据的目标. HiStore引擎将数据组织为两个层次:
- 物理存储介质上的的块数据(Data Node, DN).
-
知识网格(Knowledge Grid, KG).
物理数据块(DN)
数据块是存储的最低层,列中每份大小固定的单元组成一个数据块。数据块比列更小,具有更好的压缩比率;又比磁盘默认存储单元单元更大,具有更好的查询性能。
- 物理数据按固定数据块存储(Data Node).
- 数据块大小固定(典型值128KB),优化IO效率.
- 提供基于块(Block)的高效压缩/加密算法.
知识网格(KG)
HiStore引擎利用知识网格架构来对查询优化器,计划执行和压缩算法等提供支持. 知识网格是HiStore 引擎进行快速数据查询的关键.在查询计划分析与构建过程中,通过知识网格可以消除或大量减少需要解压的数据块,降低IO消耗,提高查询响应时间和网络利用率。 对于大部分统计/聚合性查询, HiStore引擎往往只需要使用知识网格就能返回查询结果(而不需要读取数据), 这种情况下在1s时间内就可 以返回查询结果。
HiStore 知识网格由数据元信息节点(MD)和知识节点(KN)组成:
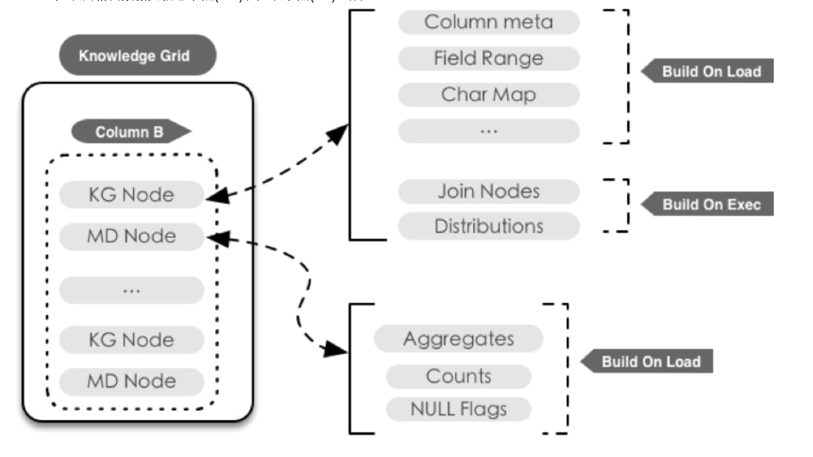
- 数据元信息节点(MD)与数据节点(DN)之间保持1:1关系,元信息节点中包含了其对应数据块中数据的相关信息:
- 数据聚合函数值(MIN,MAX,SUM,AVG等).
- 记录数量(count)
- 数据中的null记录标记.
- 元信息节点在数据装载的时候就会构建. MD为数据压缩, 聚合函数即席查询等技术提供了支持.
-
知识节点(KN)除了基础元数据外,还包括数据特征以及更深度的数据统信息. 知识节点在数据查询/装载过程中会动态计算.
- 该列的数据类型定义,约束条件等基础信息.
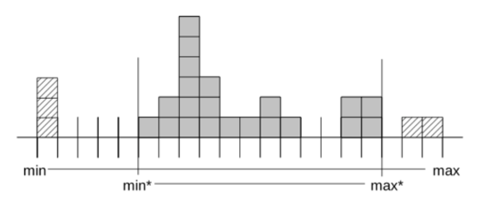
- 数据节点(DN)中记录值范围段的标识BitMap.针对数值类型的记录(date/time, integer, decimal…), 范围段可以用来快速确认当前对 应DN是否包含所需数据. 例如对于整数类型, Field Range的大致组成如下:

- 从MD中获取数据块的MAX与MIN,并将MAX-MIN划分为固定段(例如1024).
-
每个段中分别使用1个bit标识是否有记录存在与该范围内.
-
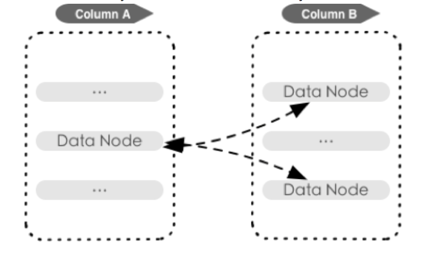
关系位图记录多表join中关联的DN信息: 显著提高join查询性能,减少无效DN扫描.
-
- 统计当前Column中各记录的值分布信息.
- 基于统计信息,HiStore引擎可以提供近似值查询(Approximate Query)支持, 对于某些对数据精确性要求不高的场景(例如海量 数据下求 top 10), 近视值查询可以利用统计信息去除大量不影响最终结果的数据节点,显著提升查询性能.
- 知识网格存储在内存中,方便快速查询.
通过知识网格, HiStore 引擎无需通过传统数据索引、数据分区、预测、手动调优或特定架构等方式就能高速处理复杂的分析查询。
2.3 计算引擎
知识网格优化器
对于来自客户端的查询请求,首先由查询优化器进行基于知识网格的优化,产生执行计划后再交给执行引擎去处理.
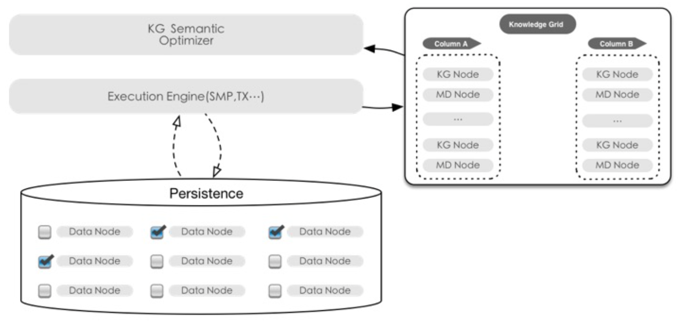
- 基于知识网格中的信息进行粗燥集(Rough Set)构建, 并确定此次请求所需使用到的数据节点.
- 基于KN和MD,确定查询涉及到的DN节点集合,并将DN节点归类:
- 关联DN节点:满足查询条件限制的数据节点.
- 不确定性DN节点: 数据节点中部分数据满足查询条件.
- 非关联DN节点: 与查询条件完全不相关.
- 执行计划构建时, 会完全规避非关联DN, 仅读取并解压关联DN, 按照特定情况决定是否读取 不确定的DN:
- 基于KN和MD,确定查询涉及到的DN节点集合,并将DN节点归类:
- 如果查询请求的结果可以直接从元信息节点(MD)中产生(例如count, max, min等操作),则直接返回元信息节点中的数据,无需访问物理数 据文件.
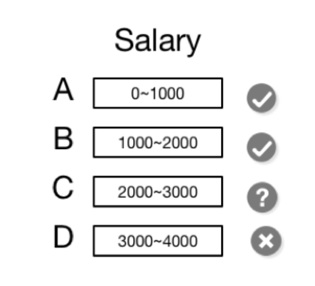
例子: 对于一个查询请求, 通过KG可以确定3个关联性DN和1个不确定性DN:
SELECT count(*) FROM employees where salary < 2500
- 如果此请求包含聚合函数. 此时只需要解压不确定性DN并计算聚合值, 再结合3个关联性DN中MD上的统计值即可得出结果.
- 如果此请求需要返回具体数据, 那么无论关联性DN还是不确定性DN, 都需要读取数据块并解压缩,以获得结果集.
执行引擎
- 执行计划解析与执行
- 执行计划解析
- IO线程池维护
- 内存分配与管理
- 事务支持(redo/undo log, double write…)
- SMP支持(并发查询)
- 物理文件管理
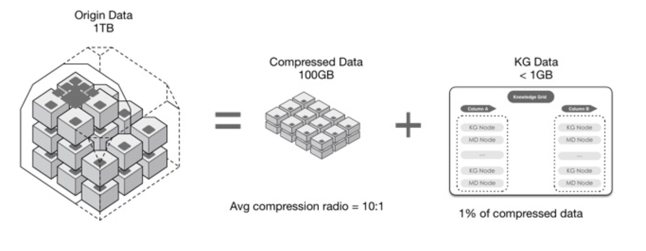
2.4 高效数据压缩
HiStore 基于列数据类型和特定领域优化的高效压缩技术能提高查询速度,降低数据库磁盘容量。HiStore 引擎通过优化后的高效压缩处 理,可以在没有特意数据库调优和管理情况下确保性能需求;随着数据量的增长,可以最小化所需的存储和服务器容量,从而节约成本,达到具有 高性能、低成本的解决方案。
-
基于列进行数据压缩
- 列中所有记录的类型一致,可以根据数据类型选择对应的高效压缩算法.
- 列中重复值出现概率高,压缩效果明显.
- 数据节点大小固定,可以最大化压缩性能和效率.
-
字符串压缩: PPM 算法.
- 数值类型压缩(int,float,date/time等): PPM预测, 找到最优分割位,把数据分成高位部 分和低位部分. 分别对分割后的数据执行Carryless RangeCoder 编码.
- 除了常规数据类型外,可以针对一些特定业务场景开发高效压缩算法, 例如Email 地址, IP地址,URL等.
2.5 其他特性
预处理数据导入

针对异构数据源背景海量数据背景, HiStore还提供了外部预处理导入支持,方便客户端应用在不增加HiStore 负载的情况下告诉导入外部 数据.
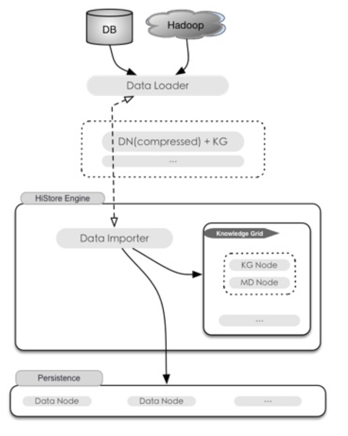
- 提供独立的数据导入客户端:
- 支持不同的数据源环境: Hbase, DB等环境.
- 客户端控制异构数据源与关系Schema的映射.
- 支持多语言架构.
- 数据预处理
- 导入客户端在外部处理数据块的压缩以及知识节点的构建.
- 数据预处理完成后, 可以直接归档进入HiStore引擎.无需再次执行SQL解析,数据验证以及 事务处理等操作.
- 优点:
- 数据在外部完成预处理,直接使用二进制导入.
- 无需通过SQL文本来表达数据,这很适合数据量小但是插入频繁的场景.
- 避免SQL解析,数据验证等操作对服务器造成性能冲击.影响服务器吞吐量.
- 拥有异构数据源以及多语言支持, 客户端可以不再通过拼装SQL语句的方式来导入数据.
- 高速的导入支持: 可以达到2TB/小时的处理量,适合面向批量处理的系统.
- 数据在外部完成预处理,直接使用二进制导入.
近似查询(Approximate Query)
近视值查询依据存储在知识网格中每个数据节点的概率样本值, 进一步过滤不会对最终查询结果造成重点影响的数据节点(DN). 对于某些 对数据精确性要求不高的场景,近视值查询可以利用统计信息去除大量不影响最终结果的数据节点,显著提升查询性能.常见的近似查询场景: 海量数据下查询 top 10 记录.
2.6 HiStore 架构总结
- 关键字: 低存储成本,低维护成本, 海量数据背景下的OLAP存储引擎.
- 低存储成本: 高效数据压缩,提高磁盘存储空间利用率.
- 低维护成本: 基于自动构建的知识网格,无需DBA手动创建索引来提升查询速度.
- 海量数据背景下的OLAP存储引擎:
- 为OLAP型应用而优化, 通过知识网格、SMP、近视查询等特性; 最大化查询性能.
- 基于关系列(Column)的存储模型,只查询所需数据,并提供任意列组合的ad-hoc查询支持.
三.HiStore未来规划
3.1 HiStore 管控平台
HiStore引擎可以提供强大的数据查询和低成本的数据存储. 但是其自身的安装和管理需要一定的学习曲线. 为了更有效的推广HiStore存 储引擎,我们团队也正在开发配套的HiStore引擎管控平台. 通过HiStore管控平台,用户可以直接部署HiStore引擎到指定目标机器上. 目前这一 块正在和UDP团队合作,其最终目标为打造成为一款集HiStore Engine自动部署,实例管控,运行时监控,数据备份/恢复以及自动化运维的一体化产品.

3.2 HiStore 高可用集群
HiStore 本身与常见关系数据库的高可用架构一样(例如MySQL),为了保证强一致性,都会将数据更新在Master上执行,然后通过复制技术 将副本导入到Slave节点.
但是与MySQL标准的binlog 复制不同. HiStore引擎中存储的不是原始数据,而是压缩后的数据块(DN).此时如果使用binlog的方式来进行复制, 会导致网络上产生大量数据流量.
为了解决这一点, HiStore目前正计划实现基于压缩后DP块的高效数据复制支持.相对于binlog复制,该技术可以大大降低网络传输所需的数据 量.
此外, HiStore也会可选地支持透明的读写分离,方便客户端在不修改的代码的情况下,扩展查询性能.
最后提一下, HiStore后续的集群技术将会朝Share-nothing的方向发展(自动处理数据分片与事务一致性),这部分的架构设计目前也正在团 队中进行技术讨论与原型验证.
3.3 HiStore Roadmap
- Hybrid Engine: 热点数据存储在Row-engine中,历史数据自动转储到Column-engine.
- 数据验证:可支持自动校验数据,以此确保服务器异常退出时数据的完整性。
- 外部数据导入工具: 支持从HDFS,ODPS中导入数据到HiStore.
- 知识网格管理/Rebuilder: 为管理员提供针对知识网格的在线管控支持.
此外我们团队也正在讨论和验证HiStore引擎/集群与中间件团队其他产品结合的可能.
四.相关参考
术语解释:
OLAP
: OLAP is an acronym for Online Analytical Processing. OLAP performs multidimensional analysis of business data and provides the capability for complex calculations, trend analysis, and sophisticated data modeling.
OLTP
: Online transaction processing, or OLTP, is a class of information systems that facilitate and manage transaction-oriented applications, typically for data entry and retrieval transaction processing.
DN
: Data Node: 数据节点. 数据块是存储的最低层,列中每份大小固定的单元组成一个数据块。
MD

: Meta data: 数据元信息节点(MD)与数据节点(DN)之间保持1:1关系,元信息节点中包含了其对应数据块中数据的相关信息.
KN
: Knowledge Node: 知识节点(KN)除了基础元数据外,还包括数据特征以及更深度的数据统信息. 知识节点在数据查询/装载过程中会动态计算.
KG
: Knowledge Grid: 知识网格是HiStore 引擎进行快速数据查询的关键. 在查询计划分析与构建过程中,通过知识网格可以消除或大量减少需要 解压的数据块,降低IO消耗,提高查询响应时间和网络利用率。
正文到此结束
- 本文标签: 协议 mail 集群 UI 时间 实例 core Action 服务器 自动化 cat 配置 需求 Select src 物联网 备份 db 产品 安装 代码 遍历 build 营销 mysql node 线程 map 管理 解析 schema 线程池 IBM 广告 sql 大数据 App Amazon mmm tab 数据库 HBase NSA 智能 总结 http 测试 安全 IDE 空间 开发 推广 定制 ip HDFS 数据 UDP 组织 统计 ORM
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

