自己动手做聊天机器人 十一-0字节存储海量语料资源 - SharEDITor - 关注大数据技术

基于语料做机器学习需要海量数据支撑,如何能不存一点数据获取海量数据呢?我们可以以互联网为强大的数据后盾,搜索引擎为我们提供了高效的数据获取来源,结构化的搜索结果展示为我们实现了天然的特征基础,唯一需要我们做的就是在海量结果中选出我们需要的数据,本节我们来探索如何利用互联网拿到我们所需的语料资源
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
关键词提取
互联网资源无穷无尽,如何获取到我们所需的那部分语料库呢?这需要我们给出特定的关键词,而基于问句的关键词提取上一节已经做了介绍,利用pynlpir库可以非常方便地实现关键词提取,比如:
# coding:utf-8 import sys reload(sys) sys.setdefaultencoding( "utf-8" ) import pynlpir pynlpir.open() s = '怎么才能把电脑里的垃圾文件删除' key_words = pynlpir.get_key_words(s, weighted=True) for key_word in key_words: print key_word[0], '/t', key_word[1] pynlpir.close()提取出的关键词如下:
电脑 2.0 垃圾 2.0 文件 2.0 删除 1.0我们基于这四个关键词来获取互联网的资源就可以得到我们所需要的语料信息
充分利用搜索引擎
有了关键词,想获取预料信息,还需要知道几大搜索引擎的调用接口,首先我们来探索一下百度,百度的接口是这样的:
https://www.baidu.com/s?wd=机器学习 数据挖掘 信息检索
把wd参数换成我们的关键词就可以拿到相应的结果,我们用程序来尝试一下:
首先创建scrapy工程,执行:
scrapy startproject baidu_search自动生成了baidu_search目录和下面的文件(不知道怎么使用scrapy,请见我的文章 教你成为全栈工程师(Full Stack Developer) 三十-十分钟掌握最强大的python爬虫 )
创建baidu_search/baidu_search/spiders/baidu_search.py文件,内容如下:
# coding:utf-8 import sys reload(sys) sys.setdefaultencoding( "utf-8" ) import scrapy class BaiduSearchSpider(scrapy.Spider): name = "baidu_search" allowed_domains = ["baidu.com"] start_urls = [ "https://www.baidu.com/s?wd=机器学习" ] def parse(self, response): print response.body 这样我们的抓取器就做好了,进入baidu_search/baidu_search/目录,执行:
scrapy crawl baidu_search我们发现返回的数据是空,下面我们修改配置来解决这个问题,修改settings.py文件,把ROBOTSTXT_OBEY改为
ROBOTSTXT_OBEY = False并把USER_AGENT设置为:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'为了避免抓取hang住,我们添加如下超时设置:
DOWNLOAD_TIMEOUT = 5再次执行
scrapy crawl baidu_search这次终于可以看到大片大片的html了,我们临时把他写到文件中,修改parse()函数如下:
def parse(self, response): filename = "result.html" with open(filename, 'wb') as f: f.write(response.body)重新执行后生成了result.html,我们用浏览器打开本地文件如下:
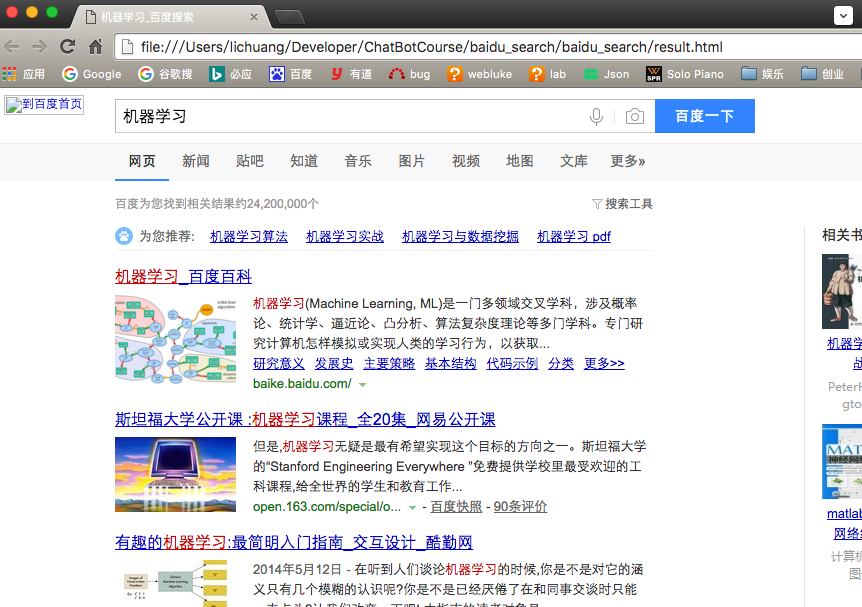
说明我们抓取到了正确的结果
语料提取
上面得到的仅是搜索结果,它只是一种索引,真正的内容需要进入到每一个链接才能拿到,下面我们尝试提取出每一个链接并继续抓取里面的内容,那么如何提取链接呢,我们来分析一下result.html这个抓取百度搜索结果文件
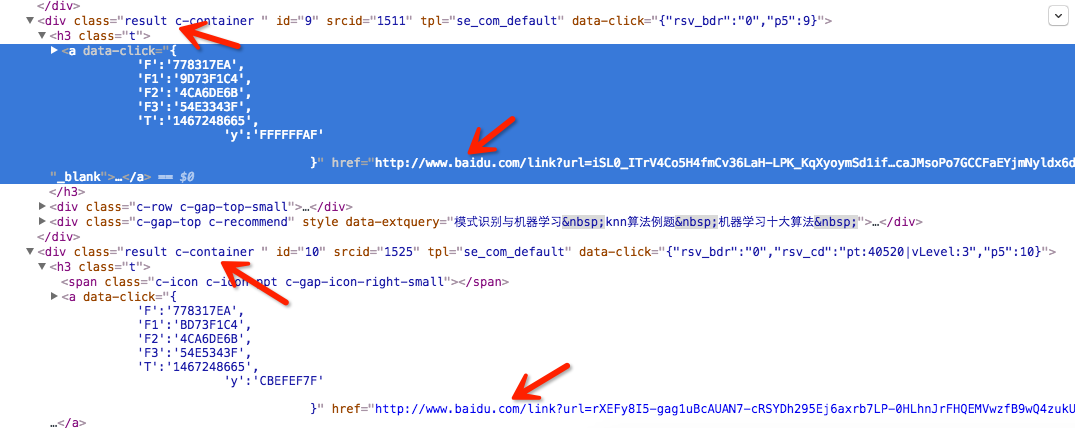
我们可以看到,每一条链接都是嵌在class=c-container这个div里面的一个h3下的a标签的href属性
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
所以我们的提取规则就是:
hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract()修改parse()函数并添加如下代码:
hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract() for href in hrefs: print href执行打印出:
…… 2016-06-30 09:22:51 [scrapy] DEBUG: Crawled (200) <GET https://www.baidu.com/s?wd=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0> (referer: None) http://www.baidu.com/link?url=ducktBaLUAdceZyTkXSyx3nDbgLHoYlDVgAGlxPwcNNrOMQrbatubNKGRElo0VWua26AC7JRD2pLxFcaUBjcOq http://www.baidu.com/link?url=PGU6qW3zUb9g5uMT3W1O4VxPmoH-Fg-jolx8rBmBAeyOuXUl0wHzzNPkX3IDS5ZFSSSHyaBTjHd5f2r8CXBFjSctF9SGKaVock5xaJNuBCy http://www.baidu.com/link?url=JMirHAkIRJWI_9Va7HNc8zXWXU7JeTYhPGe66cOV4Zi5LH-GB7IQvVng4Gn35IiVhsUYP3IFyn6MKRl4_-byca http://www.baidu.com/link?url=Et9xy9Qej4XRmLB9UdFUlWD_AugxoDxQt-BZHCFyZEDPYzEx52vL_jsr_AvkNLHC-TfLThm0dKs21IGR1QA6h_ http://www.baidu.com/link?url=Ajb1DXzWj9A6KAYicHl4wS4RV6iDuy44kP_j-G0rbOHYQy5IR5JOigxbJERsqyH3 http://www.baidu.com/link?url=uRDMnVDsmS7sD4frNv8EHd2jKSvOB5PtqxeT8Q7MFzRyHPIVTYyiWEGNReHAbRymMnWOxqF_CSQOXL87v3o4qa http://www.baidu.com/link?url=18j6NZUp8fknmM1nUYIfsmep5H0JD39k8bL7CkACFtKdD4whoTuZy0ZMsCxZzZOj http://www.baidu.com/link?url=TapnMj78otilz-AR1NddZCSfG2vqcPYGNCYRu9_z70rmAKWqIVAvjV06iJvcvuECGDbwAefdsAmGRHba6TDpFMV1Pk-_JRs_bt9iE4T3bVi http://www.baidu.com/link?url=b1j-GMumC7s5eDXTHIMPpsdL7HtxrP4Rb_kw0GNo3z2ZSlkhLVd_4aFEzflPGArPHv7VBtZ1xbyHo3JtG0PEZq http://www.baidu.com/link?url=dG3GISijkExWf6Sy6Zn1xk_k--eGPUl1BrTCLRBxUOaS4jlrpX-PzV618-5hrCeos2_Rzaqrh0SecqYPloZfbyaj6wHSfbJHG9kFTvY6Spi 2016-06-30 09:22:51 [scrapy] INFO: Closing spider (finished) ……下面我们把这些url添加到抓取队列中继续抓取,修改baidu_search.py文件,如下:
def parse(self, response): hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract() for href in hrefs: yield scrapy.Request(href, callback=self.parse_url) def parse_url(self, response): print len(response.body)抓取效果如下:
…… 2016-06-30 09:26:52 [scrapy] DEBUG: Crawled (200) <GET https://www.baidu.com/s?wd=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0> (referer: None) 2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://book.douban.com/subject/1102235/> from <GET http://www.baidu.com/link?url=S1kmtqU1ZBDaSKlVXdeKfNtyv7fErWDMC_TuOEXdedXEe2DzoMqRbMdbejbC4vts4MHm5NQUIRbk0Y0QdohY5_> 2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://www.kuqin.com/shuoit/20140512/339858.html> from <GET http://www.baidu.com/link?url=_6fKf9IjO_EJ4hw91Y6RnfXnqS5u8VmwvDsJh3tduapsgXKQb-nMjsxMRPLW1bt5JlnzJPgOobHQwyHTgkWolK> 2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://wenku.baidu.com/link?url=7pAXoiFZz4alDMOjp-41OJaONe3B86GMEiFu96bqQy8qakk37vouey5Q-SxL7oN-r9mnNukKgVjN8iOloEKQoeEmgKLzukIFkX_rpr3dhy3> from <GET http://www.baidu.com/link?url=7pAXoiFZz4alDMOjp-41OJaONe3B86GMEiFu96bqQy8qakk37vouey5Q-SxL7oN-r9mnNukKgVjN8iOloEKQoeEmgKLzukIFkX_rpr3dhy3> 2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://blog.csdn.net/zouxy09/article/details/16955347> from <GET http://www.baidu.com/link?url=5dh-19wDKE_agNpwz_9YTm01wHLJ9IxBfrZPVWo6RfFECGmIW7bt0vk6POhWDN04O4QHem_v8-iYLTzoeXmQZK> 2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://open.163.com/special/opencourse/machinelearning.html> from <GET http://www.baidu.com/link?url=ti__XlRN8Oij0rFvqxfTtJz-dLhng6NANkAVwwISlHQ4nKOhRXNSJQhzekflnnFuuW5033lDRcqywOlqrzoANUhB0yQf3Nq-pXMWmBQO7x7> 2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://www.guokr.com/group/262/> from <GET http://www.baidu.com/link?url=cuifybqWoLRMULYGe70JCzyrZMEKL9GgfAa6V7p_7ONb7Q6KzXPad5zMfIYsKqN6> 2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://mooc.guokr.com/course/16/Machine-Learning/> from <GET http://www.baidu.com/link?url=93Yp_GA3ZLnSwjN5YREAML4sP5BthETto8Psn7ty5VJHoMB95gWhKTT6iDBFHeAfHjDhqwCf-NBrgeoP7YD1zq> 2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://tieba.baidu.com/f?kw=%BB%FA%C6%F7%D1%A7%CF%B0&fr=ala0&tpl=5> from <GET http://www.baidu.com/link?url=EjCvUWhJWV1_FEgNyetjTAu6HqImgl-A2229Lp8Kl3BfpcqlrSLOUabc-bzgn6KD1Wbg_s547FunrFp79phQTqXuIx6tkn9NGBhSqxhYUhm> 2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://www.geekpark.net/topics/213883/> from <GET http://www.baidu.com/link?url=kvdmirs22OQAj10KSbGstZJtf8L74bTgd4p1AxYk6c2B9lP_8_nSrLNDlfb9DHW7> ……看起来能够正常抓取啦,下面我们把抓取下来的网页提取出正文并尽量去掉标签,如下:
def parse_url(self, response): print remove_tags(response.selector.xpath('//body').extract()[0])下面,我们希望把百度搜索结果中的摘要也能够保存下来作为我们语料的一部分,如下:
def parse(self, response): hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract() containers = response.selector.xpath('//div[contains(@class, "c-container")]') for container in containers: href = container.xpath('h3/a/@href').extract()[0] title = remove_tags(container.xpath('h3/a').extract()[0]) c_abstract = container.xpath('div/div/div[contains(@class, "c-abstract")]').extract() abstract = "" if len(c_abstract) > 0: abstract = remove_tags(c_abstract[0]) request = scrapy.Request(href, callback=self.parse_url) request.meta['title'] = title request.meta['abstract'] = abstract yield request def parse_url(self, response): print "url:", response.url print "title:", response.meta['title'] print "abstract:", response.meta['abstract'] content = remove_tags(response.selector.xpath('//body').extract()[0]) print "content_len:", len(content)解释一下,首先我们在提取url的时候顺便把标题和摘要都提取出来,然后通过scrapy.Request的meta传递到处理函数parse_url中,这样在抓取完成之后也能接到这两个值,然后提取出content,这样我们想要的数据就完整了:url、title、abstract、content
百度搜索数据几乎是整个互联网的镜像,所以你想要得到的答案,我们的语料库就是整个互联网,而我们完全借助于百度搜索引擎,不必提前存储任何资料,互联网真是伟大!
之后这些数据想保存在什么地方就看后面我们要怎么处理了,欲知后事如何,且听下回分解
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

