小米风控实践
邓文俊,小米高级研发工程师,2013 年加入小米,参与了数据后台,风控系统,支付等系统的研发工作。
我来自小米支付,今天分享的主题是小米风控实践。为什么选风控这个题目?其实在我看来风控对互联网金融来说,风控就像是内裤,每个人都有,但是不会把它秀给别人看。对其他人来说风控是很神秘,今天带给大家看看小米我们怎么是一步步走过来,在风控方面做了哪些工作。 小米风控可以分为三个历程,尝试、发展和扩展。

一、尝试
2014 年的时候我们发行我们米币短信充值渠道坏账率非常高,高到我们几乎赚不到钱。米币像 QQ 一样,是虚拟币,用米币可以在小米生态圈内购买所有服务。短信什么渠道呢?用户用短信发一条短信给运营商,运营商就会从它的帐户里面扣钱转给我们。运营商每个月给我们结一次钱,他会告诉我们有一些帐是坏账,他不会把钱给我们。他也不会告诉你哪些是坏账,哪些是好帐。我们要自己想办法解决坏账问题,让自己有钱可赚。
我们设定两种风控规则,这是第一种规则,我们叫限额、限次、限频规则。设备、帐户、手机号是一个标识类。另外一个纬度是限制类,限制交易范围,比如时间、业务、渠道等等。最后还有限制方法。我们的版本里面一个规则包括三个部分,一个是标识,一个是范围,一个是限制方法。

一个帐户一天之内他的消费金额上限是 100 米币。还有一种情况是策略,大家支付都是用手机,这个设备每小时某个业务交易次数可以限制。还有交易的频率,比如一个帐户这次交易跟上次交易要超过,不然很可能是机器行为。一般用户不会频繁交易,除非你是玩游戏非常上瘾,一般不会出现这样情况。
第二类规则限制是标识属性之间的关系,比如我们一般认为一个帐户只会登录到有限几个设备,不会登录太多。反过来能够登录设备也是有性质,要排除测试情况。有了这两个规则之后,我们迅速开始开发,以互联网的模式用了四周就迅速开发,完成了这样的规则引擎在控制台,控制台可以修改规则也可以看到实时效果。开发完了之后我们没有立刻上线,先试运行 2 周,过程是什么?
试运行过程中规则并没有真正的生效。只记录一些交易,会被哪些拦截不成功,有了这些数据之后,我们可以条件规则这些顺序以及阈值,使我们的规则达到最佳效果。运行两周之后有信心,才能真正起来。
上线之后的效果,首先上线一个月之后,运营商一个月之后给我们结钱。一个月之后我们才知道我们的风控效果。上线之后我们发现我们的坏账率比之前最高峰的时候低 1/3。比历史上的坏账率低 1/2。我们渠道成本占到 1/2,我们可以赚钱了。我们一个月的收入多了 50% 左右的增长。
通过这次风控实践尝试,我们有一些经验。第一不要小看简单规则,我们开始的时候我们认为最简单,效果相当好。风控是平衡的,我们目标是达到一种平衡。我们的交易额和我们坏账率之间达到平衡,使我们收益率是最高的。为了达到这个平衡,我们需要不断的利用云的手段,分析数据,调整规则,这是我们决定风控成败很重要的关键。
2014 年底,我们有很多小米用户,如何给小米用户打分,可以是信用分,风险分。信用分可以用于信贷,风险分可以用交易时风险控制。数据有限,我们用米币的形式做模型。
我们用三个纬度建立模型:
- 还款能力 ,包括用户最近三个月的消费额、消费次数以及累计消费次数还有他的消费情况。比如他在游戏、阅读、视频等不同业务说消费情况怎么样。
- 依赖性 ,对小米生态圈多么依赖,会不会上瘾,如果走了会不会很痛苦。我们在依赖性方面选取他的注册时间,活跃度,每天花多长时间,还有他使用 App 的情况,最长使用 App 有哪些,频率怎么样。
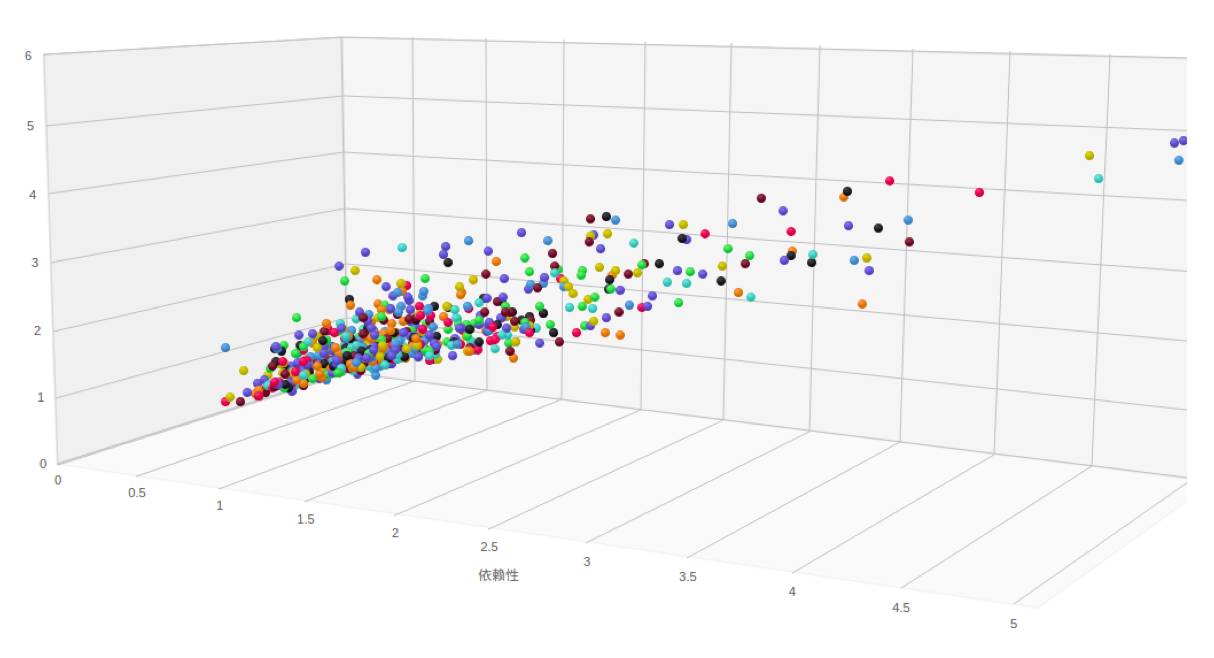
- 正常度 ,我们看这个人绝大部分正常,也有不正常。我们用之前积累,使用等待充值频率,等待有风险。类似这样的属性,我们给用户进行打分,这个是打分的图,横轴是依赖性,纵轴往上是它的还款能力。X 轴是依赖性,Y 轴是还款能力,Z 轴是正常度。
 (点击图片全屏缩放)
(点击图片全屏缩放)
大家可以看到用户分布是非常集中的。我们本来想通过这个图能不能发现一批还款能力、依赖性和正常度都比较高的用户,最后可以做我们的优质用户,作为未来信贷基础。但是很遗憾,我们数据有限,我们没有找到这样的用户。我们只是发现一个事实,我们绝大多数的用户都是还款能力和依赖度很高的正常用户。
二、发展
我们再看 2015 年之后,我们开始了开发自己的第三方支付。我们为小米网、小米生活等小米生态内的其他业务进行金融服务。我介入服务越来越多,我们发现我们遇到的问题越来越多,我们有时候会遇到突发事件,有了方案之后我需要能够迅速上线一些风控规则。因为我们发现每晚一天可能我们的损失都是百万级,希望快速创建风控规则。
业务越来越多,规则越来越多,规则之间的次序都是有严格的要求。制定规则越来越麻烦,越来越容易出错,如何解决这两个问题?我们最后选择了一个开源 Drools,第一它是开源可以免费使用,第二它是 Java 可以很方便扩展,开发自如,进入自己的系统,第三它非常齐全。

这是 Drools 的例子,规则分为三部分,第一是规则名称和它的一些配置属性。第二部分是描述什么事件下会触发这个规则。第三是规则理由。
基于 Drools,我们重新搭建了我们的风控系统,风控系统分成了三个部分,普通规则、CEP 规则和管理后台。
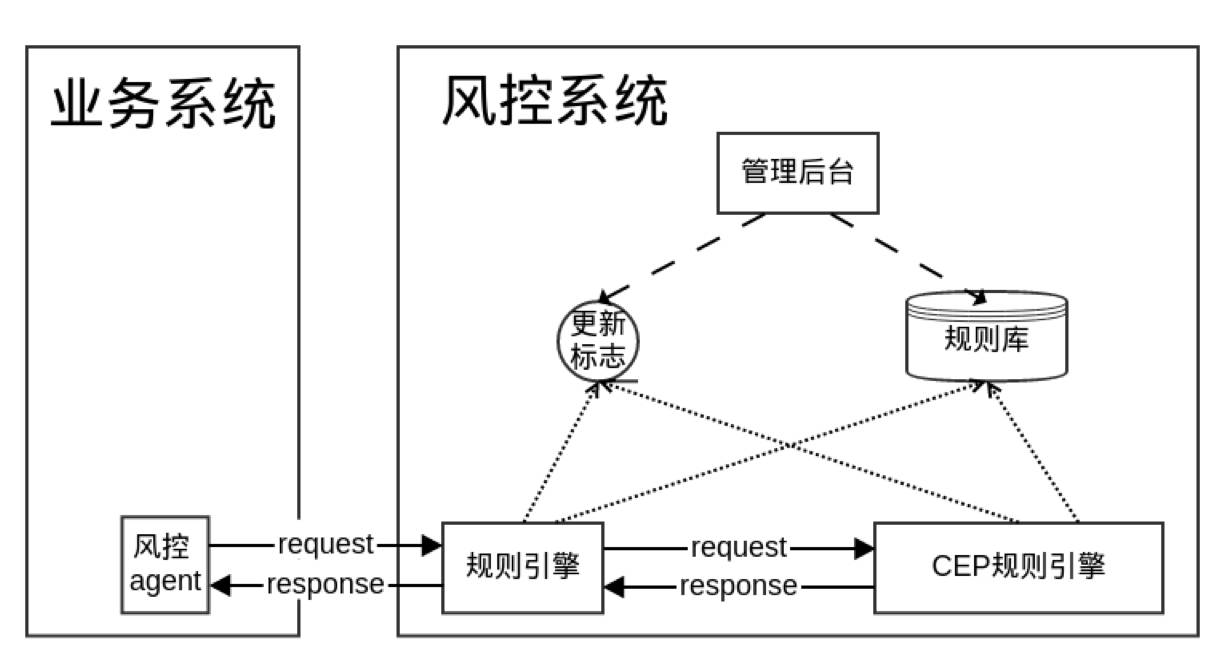
CEP 规则引擎和普通规则引擎区别是它是一种状态,能够缓存数据。刚才大家看到规则,数据实施同步到规则引擎中去。
使用了新的风控系统以后,我们的开发效率和我们运营效率明显提升。5 分钟上线规则,迅速止损。新规则上线到上线调整一周到一天。现在规则非常简单,他们也可以来调整规则。业务同学可以调整规则。
当然规则的调整变容易之后,也是把双刃剑,带来一些其他的问题,有时候规则上线,没有经过严格测试,也没有注意观察规则上的效果,只出现过一两次的事故带来一些小的损失。我们之后为了解决这个问题,我们重新搭建了一个灰度风控系统,这个系统上上线新的规则,利用历史订单验证规则效果,验证成功测试再把放在上面去,这个效果非常好。
风控打点,应用系统要主动调用风控,所以风控在业务系统中需要打点,打点多少位置有技巧,太多风控系统有很多数据低于自己的分析,对业务系统来说非常麻烦。我们采取一般打两个点够了,第一是交易前创建订单之前进行第一次调用,第二次是订单完成之后,只需要调用两次就可以了。
虽然我们有了新的风控系统之后,开发效率、研发效率提高,运行效率没有达到我们期望。我们因为风控系统要为业务系统提供服务,风控系统响应时间过长,会影响业务响应时间,会影响用户的体验。第二,我们现在专门的数据缓存,我们数据都放在 CEP 系统中,拿不出来,无法做后续分析。为了解决这两个问题,替换 CEP 系统,自建一个数据累计服务搜集数据。并且对于非实时性其他数据,我们采用日志方式,离线去进行分析。
上图是我们之前的风控系统,下图是我们修改之后的风控系统。同时在服务里面把数据导出来实时监控每天每分钟,我们整天的拦截率。
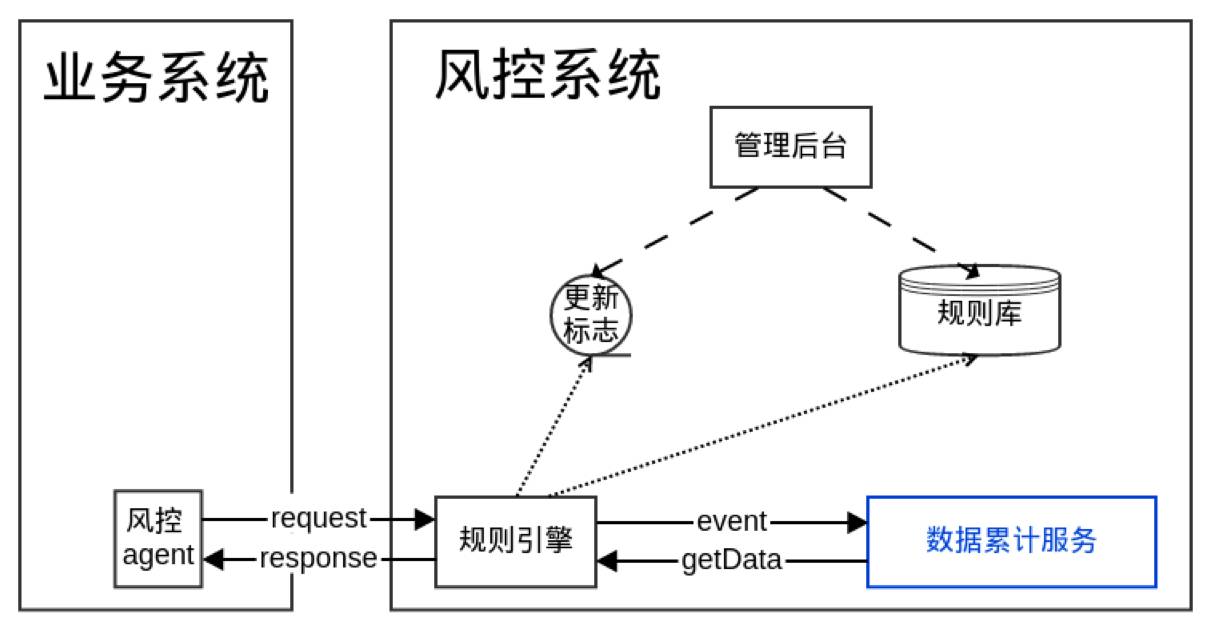
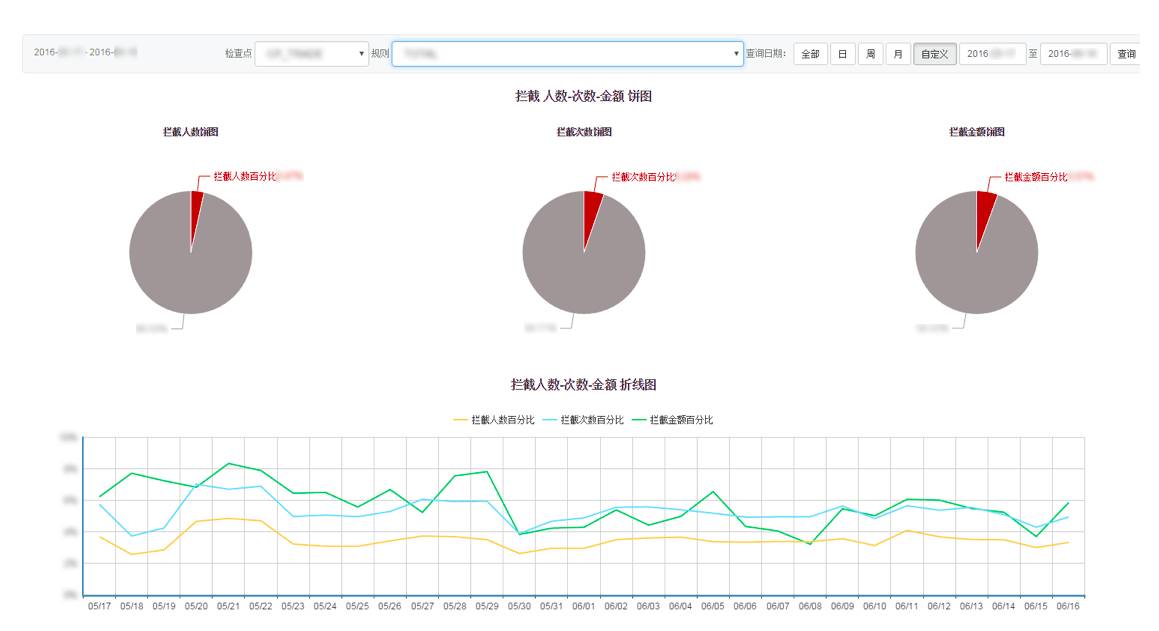
我们的风控系统响应时间缩短为以前的 1/4,并且能够实时监控规则运行效果。
 (点击图片全屏缩放)
(点击图片全屏缩放)
可以看到将数据和计算分离能够解耦带来巨大的好处,另外一方面数据应该尽快用起来,不要只是放在那里,尽快用起来,迭代起来,能够通过反馈搜集更高效的数据。
我们完成了风控系统建立之后,我们回到问题的本质,另外一个问题就是除了拍脑袋,还有其他的规则制定方法吗?我们发现我们其实可以利用机器学习的方式,从案例库中间学习模型,学习规律。同时对于案例库中已知的坏人,我们通过关系找到它的同伙。
从案例库学习方面,我们从案例库中和线上正常交易库中随即挑选两组数据。分别形成我们的训练集和测试集,选取交易数据 17 个交易特征:交易时间、交易者年龄、交易者所使用地理位置、注册地理位置、手机号归属地是否一致等,寻求这些特征,用了四组分类器,在测试集、训练集上进行训练,得到四组模型。最后再用测试集比较这四种模型优劣,最终 我们选择随机森林模型 。
找关系,我们利用交易数据里面用户、设备、手机之间关联关系建立一个关联图,里面很多关联子图。
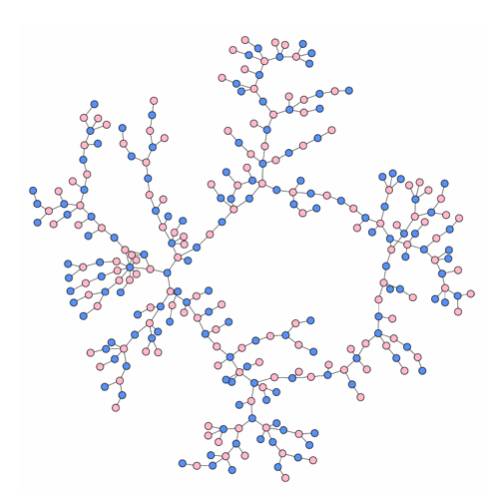
从案例库中导入相关的坏人的用户和设备,找到有关系的设备和用户,找到之后,在检查这些设备帐户交易特征。如果发现是坏人就把它加入到黑名单。通过这种方式我们预防了盗刷案件。 在随机森林模型上线五天之后,我们发现好几笔盗刷,丰富了黑名单 。从损失和错误中学习,把我们的损失变成我们财富。
随着业务快速发展,我们的经验越来越多,我们积累的案例库越来越多。我们发现很多风控问题一个很重要的问题本质是我们的交易对手是谁?他是不是本人?是不是真人?还是一条狗。我们解决这个问题考虑到我们可以利用小米生态里面海量全面的各种各样的用户数据。我们这里面能够知道一个小米帐号他是男是女,兴趣爱好是什么,年龄,学历等等这方面都是有一个画像的。
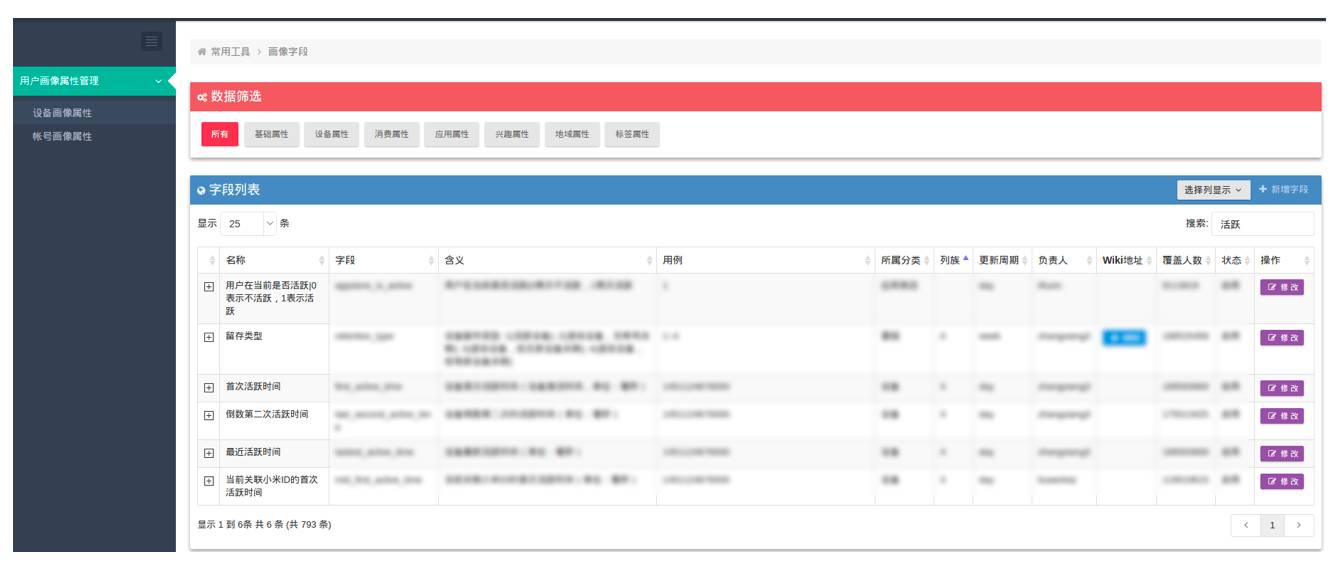
(点击图片全屏缩放)
这是我们画像组提供一个页面,这里面他把用户分成用户画像、设备画像。设备画像里面包含了 793 条各种关键属性,我们利用其中设备属性以及消费属性建立相应的规则来检查用户的真实性。这样做了以后,我们的 盗刷案件的比例近几个月来下降 40% 。
三、扩展
给我们的启发是他山之石可以攻玉。最后 2016 年以来小米的业务不断扩充,除了之以外,我们还陆续开展贷款、理财、保险、分期等等等等各种各样的业务。这些业务都需要风控,在小米体系下如何共享资源,建立风控体系?
我们解决思路是 对内共享所有数据,对外分享合作 。首先 CTO 牵头下我们建立一个基础风控组,在小米内部协调资源。如果我们需要建立服务的时候,我们建一份,实名认证服务。一个组建立这个服务,分享给其他组使用。在外部合作方面,一个团队有同盾和前海,也可以分享给同事使用。
小米这几年在金融方面扩展非常快,我们陆续开发各种各样业务,我们也希望这一方面牛人加入我们。谢谢大家。
Q&A
Q:做风控,你们利用一些简单 Drools,这个 Drools 包括什么?这个 Drools 怎么定的?后续你们用的一个随机森林框架,怎么把 Drools 放在这随机森林里做的。效果提高了大概 40% 左右,您更详细的介绍一下。如果不方面展开,能否简单举两个例子。
邓文俊:比如盗刷,有地理位置,他交易的时候他有一个地理位置。我们知道他注册的时候有地理位置,他手机号归属地有地理位置,他的身份证也是有地理位置。他最近三个月使用的设备在哪登录过,这些都是可以做限制。
Q:你们是怎么在风控模型中选用随机森林这个模型,底层是不是用了什么开源技术或者一些开源学习框架?
邓文俊:我们所有东西都是用开源的,怎么用随机森林?现在所有东西是基于刚才看到框架叫风控 Drools 框架,它的规则引擎可以调用外面服务或者外面资源。可以由随机森林模型,可以由别的模型,把每个模型学到的东西都可以做成一个独立的服务或者合到一个服务里面。在规则里面调用这个服务,把参数一些背景信息告诉这个服务,这个服务判断或者是有多少的概率是危险。再由规则本身来决定。我们是由规则引擎进行推理,其他所有服务只提供一些参考,最后规则服务来最终决定。事先学习好之后,以服务形式加载起来,放到内存起来,来调用。
Q:训练的时候这个有多少个?
邓文俊:有 17 个。
Q:刚刚我看到你们规则引擎开发是四周就可以上线,你们团队规模以及你们现在运营团队是大概什么样的配比?你们进行开源技术选型的时候所考虑这些方面是什么?
邓文俊:
- 当时风控就两个人,我开发,还有一个定规则。
- 风控分三个部门,研发、运营、数据,大概二三十人。到了第三方支付牌照之后可以为外部服务。支付宝据我所知至少一千人。
- 其实主要考虑方面就是一个,第一安全大家都用过,这是最重要。其次是不是很好用很好上手,文档齐全不齐全。第一很重要,是不是用过,是可靠的。
Q:您刚才说一开始的模型和后来的模型,模拟的模型是一直在迭代吗?
邓文俊:可以调整阈值,没有用高大上的东西。
Q:我看你之前模型一直在,后来走到机器学习,也是四种不同分类器,您选了随机森林。机器学习里面有一个问题,过拟合的问题怎么解决?
邓文俊:不解决,随它去吧。快速开发,快速上线,看迭代。
Q:您现在算法也是不断迭代过程当中,可能有一些问题没有暂时解决是吧?
邓文俊:说实话,我自己感觉我们没有过拟合的问题。
Q:您采用机器学习算法,有一个问题机器学习如果你样本集和训练集给到合适的划分,划分过程中、训练过程中,如果划分不合适或者算法有时候像过拟合抖动没有到合适地步,可能就会慢慢继续拟合,导致没有没有办法恢复。您在机器算法上面现在走的方向上有什么和大家有一些在互联网金融方向特殊的一些设计吗?
邓文俊:目前没有,我们也是刚刚开使用机器学习的方法,摸着石头过河,走一步看一步。如果我要回答你的问题的话,我给的建议是我们做的时候在企业里面其实不像高校管太多,设计那么完美或者会考虑那么多过拟合方面的科研问题、学术问题。我们先上再说,看效果,适者生存。我们并没有太关注过拟合的情况,算出什么结果就拿来用,有效,我们发现盗刷,发现有用,可以再调整。
Q:您刚刚说您样本的这些特征都是通过小米生态平台获得,包括地理位置,可能是一些帐单信息。现在有一个比较争议的问题,您获得这些纬度和用户隐私政策上咱们有什么思路?
邓文俊:小米已成为国内首家和 TRUSTe 公司就用户隐私保护展开合作的手机厂商。我们有两个原则, 第一、收集数据时,收集任何用户隐私数据都是要获得用户允许 ,默认是不许可的,需要用户明确授权。 第二、使用数据时,数据平台保证用户数据是机器可读,人不可读。 我们做分析的时候我们有一个样本的数据做模型,做测试。做完了以后,我们把我们的系统代码或者服务掉到线上跑得时候才是跑的真实的数据库。原来都是看不到,只有机器可以读,人是不可以读。
Q:我本身是做大数据研发,我对金融这方面感兴趣,我又读了金融 MBA。您说研发风控有一些系统,开始的时候是一个风控机组给你说一个业务去做。是不是一个人把金融和 IT 技术都掌握的比较好,把这个系统研发好一些,一个人就专业就建立一个好的团队,大家去合作比较好一些?
邓文俊:这个问题超出技术范畴,从我的角度我自己的体验,我觉得首先应该把自己的事情做好,你有余力可以了解其他人的合作。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

