如何用深度学习识别网络欺诈?
欺诈广告背景介绍
在这个资讯变化快速的时代,人手一台智慧型手机是非常普遍的情形,其中又以 Android 手机较常见,但你是否曾经注意过你手机中真的安装了什么移动 APP 应用程序吗 ? 你如何确定你的手机是否中毒以及是否需要安装什么应用程序?另一方面,你所任职的公司产品行销推广的如何呢?你是否觉得你的广告行销预算其实花得并不手软,但是理想中的流量以及产品安装和曝光量是否却总是没达到目标呢?如同市场营销大师 John Wanamaker 所说:Half the money I spend on advertising is wasted; the trouble is, I don’t know which half.
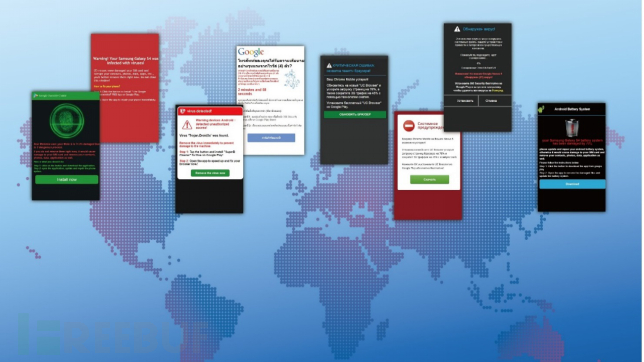
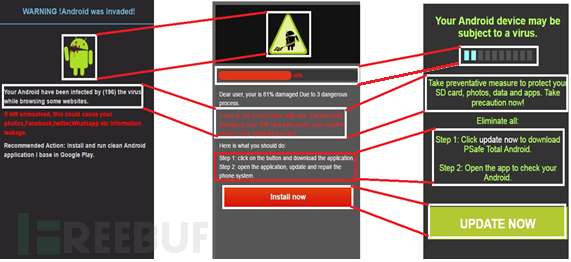
那么,当你使用手机上网时,是否有曾被告知中毒,还被迫下载了你不知道你是否需要的 App?这种当你使用手机正常浏览网页时,遇到以「你的手机中毒了」、「你的手机需要更新」等内容(如图1),意图使你下载你可能根本不需要的App,这就是所谓的欺诈广告(Deceptive Advertising);这些恐吓性内容往往伴随着手机不断震动、响铃,即便重新整理网页或是回到上一页仍无法停止这些问题,让你感到慌张,最后只能下载这些你当时不需要的App并让你以为它能帮你解决了问题,却又发现一切貌似正常,而对该App 造成反感;广告主大量广告预算更因此被销耗掉,连带导致品牌声誉下滑。由于欺诈广告呈现方式日新月异,会随着国家、时区、语言而有不同的样貌,防不胜防。
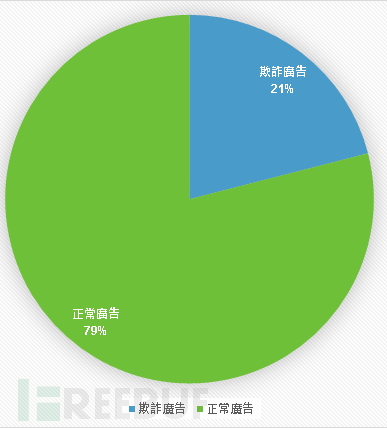
其中, 最常见的应用场景多是使用者浏览色情网站或是至免费空间下载软体点击了充满诱惑性的广告而出现伪装「系统中毒」的这种「广告手法」警示广告页面,接着再进一步跳转至应用市场;但是其实手机根本没有中毒! 这种灾害正快速的遍布全球,占了所有广告的 21%
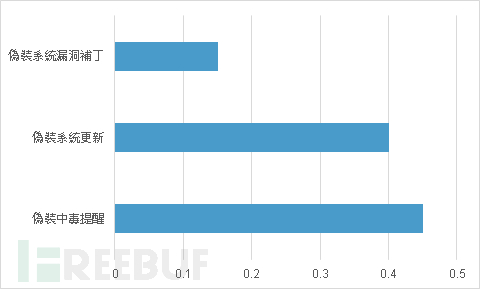
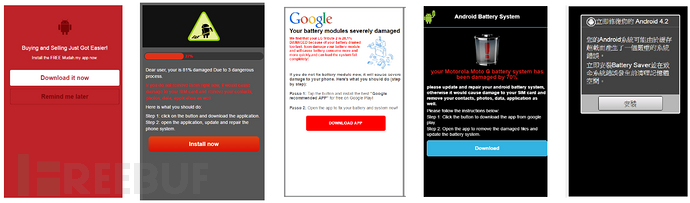
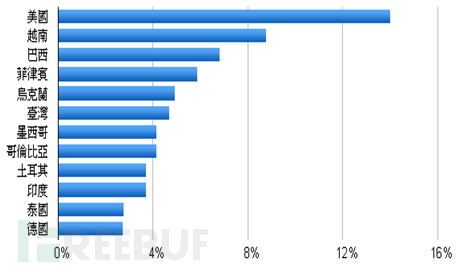
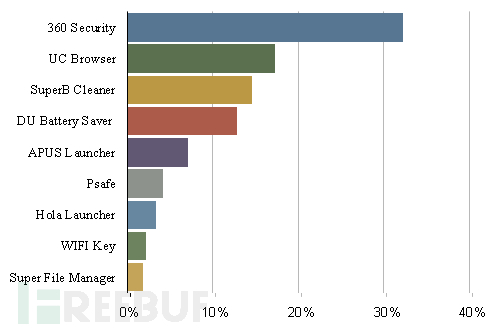
这种情况追根究底是因为部分网路广告联盟为了消耗其广告、点击率或者安装率等流量,而想出的恶质广告手法,除了增加使用者的困扰,更是浪费广告主的大量广告预算,还造成使用者对于该品牌声誉有不良的观感。另外,因为目前常见的伪装恐吓场景,主要的受害厂商为工具类或者防毒软体类App;根据统计,目前受此广告手法影响最大的国家分别是美国、巴西、台湾及德国等国家;而受害最深的APP 则是360 Security、UC Browser、SuperB Cleaner 等。
深度学习简介
2016年03月,Google Deep Mind 团队研发Alpha Go [1] 并且挑战南韩知名职业围棋棋士成功取得四胜一败,刹那间,深度学习演算法、机器学习以及人工智慧获得大量的观注;因此,基于其对于图像辨识的强大效果[2, 3],我们首开先例尝试使用了深度学习来对抗这会因时区、语系等不同而造成远比过去钓鱼网站生命周期短的欺诈广告威胁,并经过实验获得了近90% 的侦测率;以下将简要说明深度学习、类神经网路以及卷积类神经网路,以及我们如何构思对抗欺诈广告这方面的创新应用。
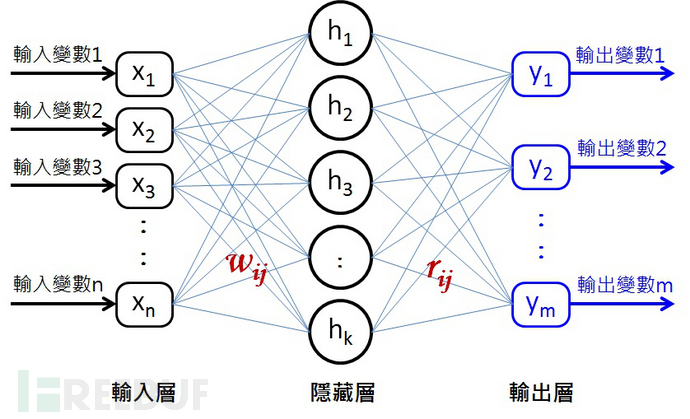
类神经网路(Neural Network) 是一种模仿人类大脑构造设计用于识别模式的演算法,通过机器感知解释传感器数据,对原始输入进行标记或聚类,而所能识别的模式是包含在向量中的数值形式;它的优点在于权值共享网路结构,降低了网路模型的复杂度,减少了权值数量(就是把多项参数浓缩成很少参数的概念,然后再一层一层的分析,使得影象可直接作为网路的输入,避免了传统演算法中复杂的特征提取和资料重建的过程。
 )
)
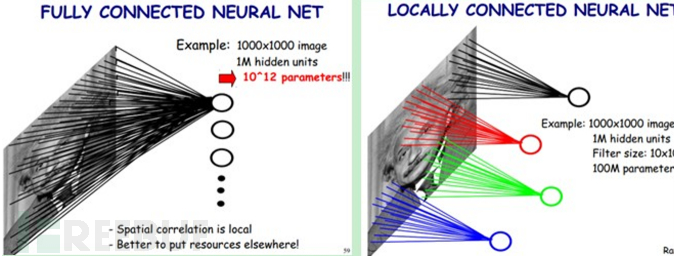
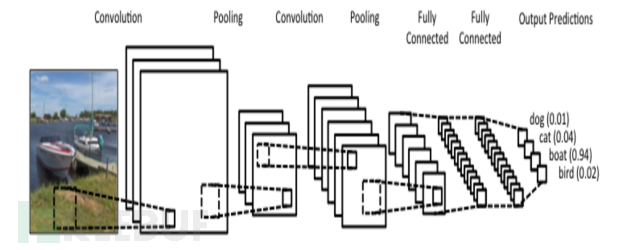
卷积类神经网路 (Convolutional Neural Network, CNN) 则是由一个或多个卷积层和顶端的全连通层组成,同时包括关联权重和池化层 (pooling layer)。而中间的隐藏层是用来增加神经元的复杂度,以便让它能够模拟更复杂的函数转换结构。此外,利用空间关系减少需要学习的参数数目,影像的一小部分作为层级结构的最底层输入,资讯再依次传输到不同的层,每层通过一个数字滤波器去获得观测资料的最显著特征;此外,若每个神经元都用同一个卷积核去卷积影象,参数可大量减少,不管隐层的神经元个数有多少,两层间的连线只有少量参数,公用同个卷积核;这就是权值共享。
 )
)
 )
)
文字探勘(Text Mining) 被视为是资料探勘(Data Mining) 的一种,关键差别在于资料探勘处理的资料是有结构性及有其明确的定义及值等,不同的地方在于其原始输入资料,都是没有特定结构的纯文字,无法直接套用资料探勘的演算法; 但透过统计等方式可计算出依词频TF (Term Frequency) 次数、文件集合中出现的文件频率DF (Document Frequency),以及反向文件频率IDF (Inverse Document Frequency) 等。但为了避免词频TF计算的频率,发生特定词只出现在特定文件,造成频率都相同而无法判断其权重,故衍生出TF-IDF (Term Frequency- Document Frequency);借此来过滤掉常见词语保留重要词语;此外,依循文字探勘的功能,可以处理关键字、文章的相似度确认以及处理多份文章的相似度等,可以将把每个文件做为一整串的索引(Index Term),每个词都有权重,不同的索引词根据自己在文件中的权重进而影响文件相关性的评分计算,看做一个n维向量证明该文件中向量集合,并转化为索引词及权重所组成的向量空间模型。
 )
)
 )
)
深度学习(Deep Learning) 是机器学习的一种分支,最简单的定义,就是大量的训练样本配合计算能力再加上自由灵活的神经网路结构设计;它试图使用包含复杂结构或由多重非线性变换构成的多个处理层对资料进行高层抽象的演算法;传统机器学习系统主要使用由一个输入层和一个输出层组成的浅层网路,至多在两层之间添加一个隐藏层。三层以上(包括输入和输出层在内)的系统就可以称为“深度”学习。以输入一幅图像来说,可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从例项中学习任务(例如,人脸识别或面部表情识别);深度学习主要是将非监督式或半监督式的特征学习和分层特征提取的手工取得特征使用演算法替代。
本系统的创新点在于目前尚未有对抗其变化快速且生命周期短的欺诈广告较好且能有效缩减人工所需耗费的资源;因此应用目前最受关注的深度学习及卷积类神经网路演算法于网路安全技术领域,是解决传统机器学习依赖安全领域专家人工预先提取特征码黑白名单的最好方式。
系统架构
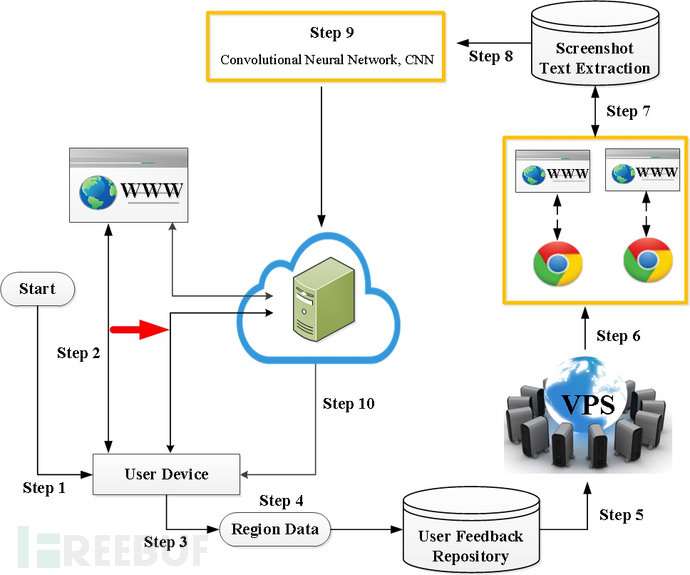
本系统主要是透过深度学习的卷积类神经网路演算法,提出一种欺诈广告网页的图像及文字语意分析系统;系统构如图9所示,首先我们搜集了大量广告网址,并透过虚拟专属主机(VPS, Virtual Private Server) 来模拟还原其页面以便更加贴近使用者所见到的场景,针对弹现广告的网页的图形进行自动化截取,并取用其中小范围进行逐层过滤,透过大量的数据来进行深度学习及其自动提取其特征,不再需要像过去一样透过人工先找出特征给类神经网路学习,逐一修正权重让整体的错误率降到最低,而是透过卷积网路结构,可以自己从数据中找出特征,而且卷积层越多,能够辨识的特征就越高阶越抽象;不再需要自己找出任何特征注记,只要把大量的图形交给卷积类神经网路,它自己会找出其抽象定义。此外,本系统亦搜集截取广告页面之文字,将其转化为图形向量再藉由卷积类神经网路进行特征的自动提取以及训练;借此可完全简化传统特征码或文字及语意分析等所需耗费的大量人力,对抗因时区及语系等而快速产生不同欺诈内容广告特别有效。
实验结果
有鉴于欲依循我们的方法从头训练其深度学习模型,需日积月累的透过GPU等运算资源及相关的欺诈广告截图及其文字等大量数据来训练模型;为避免事倍功半,本文除了说明相关实验结果及系统概念的展示外,将简要说明如何以迁移学习(transfer learning) 的方法使用Google 于2015 年底发布的Tensorflow 以及其Inception-V3 的模型来快速训练适合自己的模型;同时,我们也将公开已训练及分类完成的资料无偿分享于业界伙伴及学术研究,期许共同努力对抗欺诈广告并加强提升移动互联网的安全。
本文是采用CentOS 6.7 64 bit,所以需先启用EPEL 软件库,再下载安装docker,然后设定其网路桥接,接着下载Tensorflow的Docker image,同时可考虑安装IRMA 以及ElasticSearch等;另外,使用python爬虫来自动化爬取网址并进行图文截取做模型的训练以及特征的自动提取。
以下说明快速建置系统需准备之相关工具套件:
· Docker: https://www.docker.com
· TensorFlow: https://www.tensorflow.org
· Inception-V3: https://github.com/tensorflow/models/tree/master/inception
· Word2Vec: https://code.google.com/archive/p/word2vec/
· IRMA: http://irma.quarkslab.com
· ElasticSearch & Kibana: https://www.elastic.co
EPEL 启用及 Docker 安装
1. wget http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
2. rpm -ivh epel-release-6-8.noarch.rpm
3. sudo yum install docker-io
4. sudo service docker start
5. sudo chkconfig docker on
设定 docker 网路桥接
1. service docker stop (把 docker 停用)
2. ip link set dev docker0 down (把 docker0这个 bridge关掉)
3. brctl delbr docker0 (把 docker0 这个 bridge 刪掉)
4. ip link set dev br0 up (把你建的 bridge 啟用)
5. ip addr show br0 (检查)
6. echo ‘DOCKER_OPTS=”-b=br0″‘ >> /etc/default/docker (写入设定档)
7. service docker start (启用你的 docker)
使用python 对网页进行图文截取
1. pip install selenium
2. from selenium import webdriver
3. driver = webdriver.Chrome(‘chromedriver’, chrome_options=opts)
4. driver.set_window_size(400, 700)
5. driver.set_page_load_timeout(15)
6. fo = open(outdir + ‘/source.txt’, ‘w’)
7. fo.write(driver.page_source)
8. fo.close()
9. fo = open(outdir + ‘/wording.txt’, ‘w’)
10. fo.write(driver.find_element_by_tag_name(‘body’).text)
11. fo.close()
12. driver.save_screenshot(outdir + ‘/screen.png’)
TensorFlow 下载安装设定
1. docker run -it -v /TF/:/TF/ –name deep b.gcr.io/tensorflow/tensorflow:0.7.1-devel
2. 整理预分类的各种类图片,并各自建立一个资料夹
3. bazel build -c opt –copt=-mavx tensorflow/examples/image_retraining:retrain
4. bazel-bin/tensorflow/examples/image_retraining/retrain / –bottleneck_dir=/tf_files/bottlenecks / –model_dir=/tf_files/inception / –output_graph=/tf_files/retrained_graph.pb / –output_labels=/tf_files/retrained_labels.txt / –image_dir /tf_files/tf_photos
5. bazel build tensorflow/examples/label_image:label_image && / bazel-bin/tensorflow/examples/label_image/label_image / –graph=/tf_files/retrained_graph.pb / –labels=/tf_files/retrained_labels.txt / –output_layer=final_result / –image=/tf_files/tf_photos/tf1/000.jpg
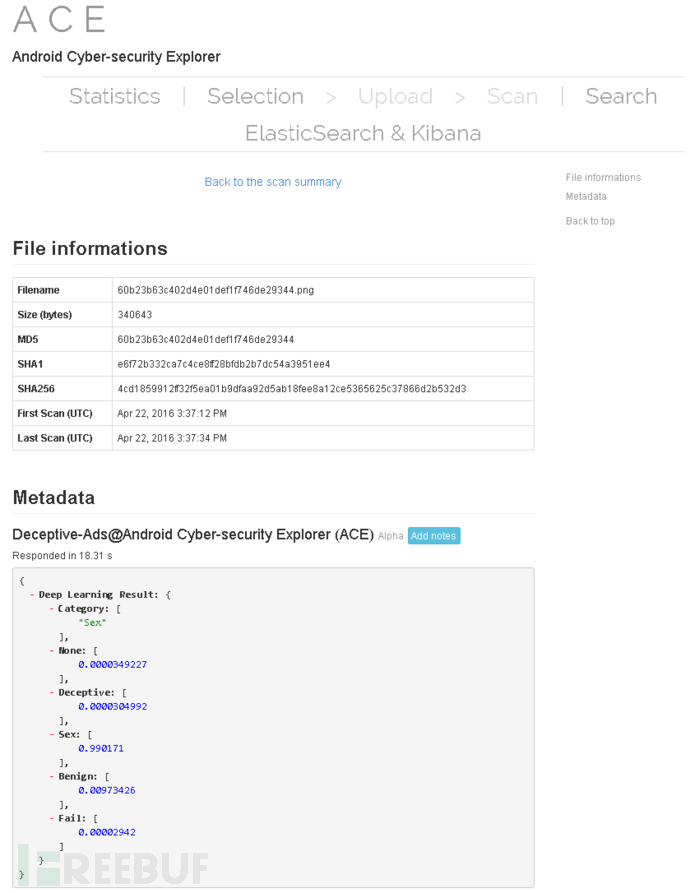
透过深度学习的卷积类神经网路演算法,我们总计自动爬取前处理了Deceptive, Benign, Sex, Fail及None等5类各约2000张截图,及各国语系词句约5000 笔,再根据Tensorflow 的GPU记忆体做参数微调来进行训练;在验证过程中,即使模型数据未含其截图或文字,仍能依图7及图8概念计算识别出相似度。

未來方向
综合前面所述,本文亦已将整个分析过程使用 IRMA 与ElasticSearch 以及 Kibana介接做为内部鉴识平台。并将开放API供业界伙伴及学术研究单位申请,持续为移动互联网安全贡献心力,提供更安全的环境给使用者;详如下图网址。
TIC: http://tic.cmcm.com
参考来源
[1] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, et al., “Mastering the game of Go with deep neural networks and tree search,” Nature, vol. 529, pp. 484-489, 2016.
[2] A. Karpathy and F.-F. Li, “Deep visual-semantic alignments for generating image descriptions,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015.
[3] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015.
*本文作者: 猎豹移动威胁情报中心(企业账号),转载请注明来自FreeBuf黑客与极客(FreeBuf.COM)
正文到此结束
- 本文标签: final http Security ip 广告 系统架构 App 主机 免费 自动化 美国 安装 空间 参数 推广 2015 rpm description 安全 GitHub 软件 统计 下载 深度学习 web find apr Google Chrome src 文章 Service wget tar centos API Docker build python 隐藏层 vps 网站 数据 Document example Word Deep Learning https 产品 黑客 Android 企业 生命 营销 git 互联网 UI HTML
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

