如何监控 golang 程序的垃圾回收
说明:本文测试环境 go version go1.6.2 darwin/amd64
本地开发环境的监控
如果是本地开发环境, 可以利用 GODEBUG=gctrace=1 /path/to/binary 的方式输出 GC 信息,然后用 gcvis 作可视化。
GODEBUG=gctrace=1 会输出如下格式的信息(输出到 stderr):
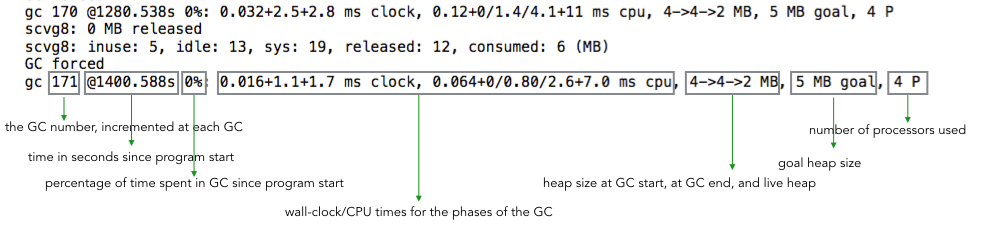
gc 1 @17.471s 0%: 0.22+4.4+0.19 ms clock, 0.66+0/1.8/10+0.57 ms cpu, 4->4->2 MB, 5 MB goal, 4 P
关于其资料,可以查阅: https://godoc.org/runtime ,这里引用下:
gctrace: setting gctrace=1 causes the garbage collector to emit a single line to standard
error at each collection, summarizing the amount of memory collected and the
length of the pause. Setting gctrace=2 emits the same summary but also
repeats each collection. The format of this line is subject to change.
Currently, it is:
gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P
where the fields are as follows:
gc # the GC number, incremented at each GC
@#s time in seconds since program start
#% percentage of time spent in GC since program start
#+...+# wall-clock/CPU times for the phases of the GC
#->#-># MB heap size at GC start, at GC end, and live heap
# MB goal goal heap size
# P number of processors used
The phases are stop-the-world (STW) sweep termination, concurrent
mark and scan, and STW mark termination. The CPU times
for mark/scan are broken down in to assist time (GC performed in
line with allocation), background GC time, and idle GC time.
If the line ends with "(forced)", this GC was forced by a
runtime.GC() call and all phases are STW.
为了方便对应上字段,我简单标记了一下:
GODEBUG=gctrace=1 对应的实现在 src/runtime/mheap.go (go 1.6)
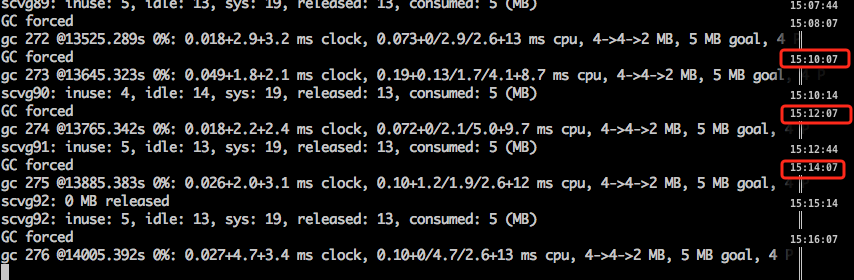
据说目前是每 两分钟 进行一次 GC forced, 关于其定义,我估计是下面这个,但是不太确定:
runtime/proc.go
// forcegcperiod is the maximum time in nanoseconds between garbage
// collections. If we go this long without a garbage collection, one
// is forced to run.
//
// This is a variable for testing purposes. It normally doesn't change.
var forcegcperiod int64 = 2 * 60 * 1e9 // 2 分钟
...
// check if we need to force a GC
lastgc := int64(atomic.Load64(&memstats.last_gc))
if gcphase == _GCoff && lastgc != 0 && unixnow-lastgc > forcegcperiod && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
forcegc.g.schedlink = 0
injectglist(forcegc.g)
unlock(&forcegc.lock)
}
从下图来看,还真是每两分钟一次 force GC 。
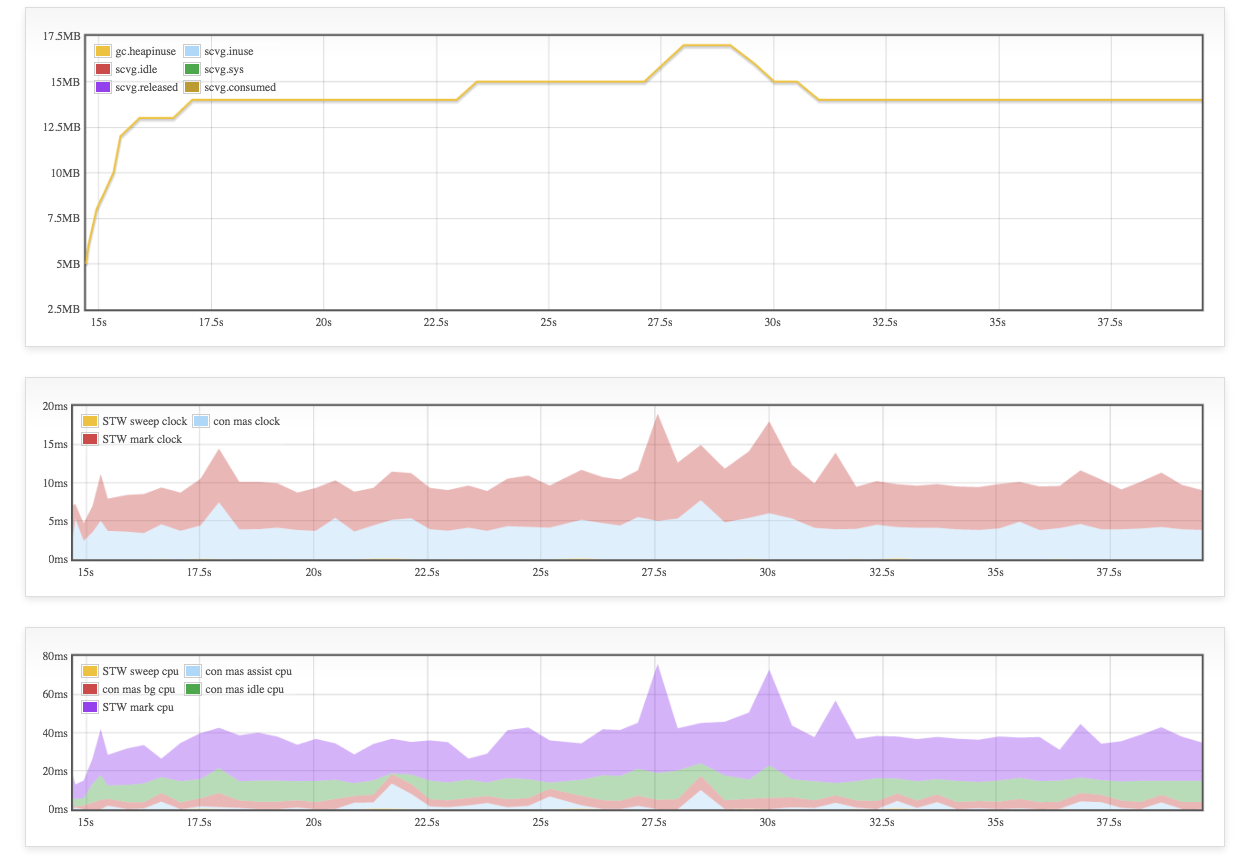
gcvis 的原理很简单, 就是逐行解析目标程序的 GC 输出,然后用正则匹配相关的数据,然后生成 JSON 数据,另外也会起一个协程开启 HTTP 服务,用于图表展示。
gcvis 主要有两种用法:
1、 直接运行
gcvis /path/to/binary
2、 管道重定向方式(standard error)
GODEBUG=gctrace=1 /path/to/binary |& gcvis
gcvis 的图标输出效果如下:
线上环境的监控
上面这种是不修改一行代码的情况下,完全使用外部工具/参数,无侵入式的 GC 监控。
另一种办法是直接读取 runtime.MemStats (runtime/mstats.go) 的内容。其实上面这种办法也是读取了 runtime.memstats (跟 runtime.MemStats 是同一个东西,一个对内,一个对外)。这也意味着要修改我们的程序代码。
我逛了一圈,发现不少人也是这么干的。
- NSQ 对 GC 监控 https://github.com/nsqio/nsq/blob/master/nsqd/statsd.go#L117
- beego 对 GC 的监控: https://github.com/astaxie/beego/blob/master/toolbox/profile.go#L96
- Go port of Coda Hale’s Metrics library https://github.com/rcrowley/go-metrics
- A Golang library for exporting performance and runtime metrics to external metrics systems (i.e. statsite, statsd)
https://github.com/armon/go-metrics/
总之,都是读取了 runtime.MemStats ,然后定时发往一些时序数据库之类的,然后展示。
代码基本都是这样:
memStats := &runtime.MemStats{}
runtime.ReadMemStats(memStats)
如果希望获取 gcstats:
gcstats := &debug.GCStats{PauseQuantiles: make([]time.Duration, 100)}
debug.ReadGCStats(gcstats)
如果你用了 open-falcon 作为监控工具的话,还可以用 github.com/niean/goperfcounter , 配置一下即可使用。
{ "bases": [“runtime”, “debug”], // 分别对应 runtime.MemStats, debug.GCStats } 如果读者看过 ReadMemStats 的实现的话,应该知道里面调用了 stopTheWorld 。 卧槽,这会不会出事啊!
Russ Cox 说,
We use ReadMemStats internally at Google. I am not sure of the period but it’s something like what you’re talking about (maybe up to once a minute, I forget).
Stopping the world is not a huge problem; stopping the world for a long time is. ReadMemStats stops the world for only a fixed, very short amount of time. So calling it every 10-20 seconds should be fine.
Don’t take my word for it: measure how long it takes and decide whether you’re willing to give up that much of every 10-20 seconds. I expect it would be under 1/1000th of that time (10 ms) .
refer: https://groups.google.com/forum/#!searchin/golang-nuts/ReadMemStats/golang-nuts/mTnw5k4pZdo/rpK69Fns2MsJ
另外, https://github.com/rcrowley/go-metrics 也提到了(go-metrics/runtime.go L:68)
runtime.ReadMemStats(&memStats) // This takes 50-200us .
我觉得一般业务,只要对性能没有很变态的要求,1毫秒内都还能接受吧,也看你读取的频率有多高。
由于每家公司使用的监控系统大相径庭,很难有大一统的解决办法,所以本文只是提供思路以及不严谨的考证。祝大家玩的开心!
小结:
- 基本都是围绕 runtime.MemStats 做文章;
- 没事多看看 runtime 代码,加深理解。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

