Mycat的JDBC后端框架
JDBC方式访问后端数据库
Mycat对JDBC支持部分的代码比较简单,主要实现了下面三个类:
1. JDBCDatasource JDBC物理数据源
2. JDBCConnection JDBC连接类
3. JDBCHeartbeat JDBC心跳类
JDBC相关类图
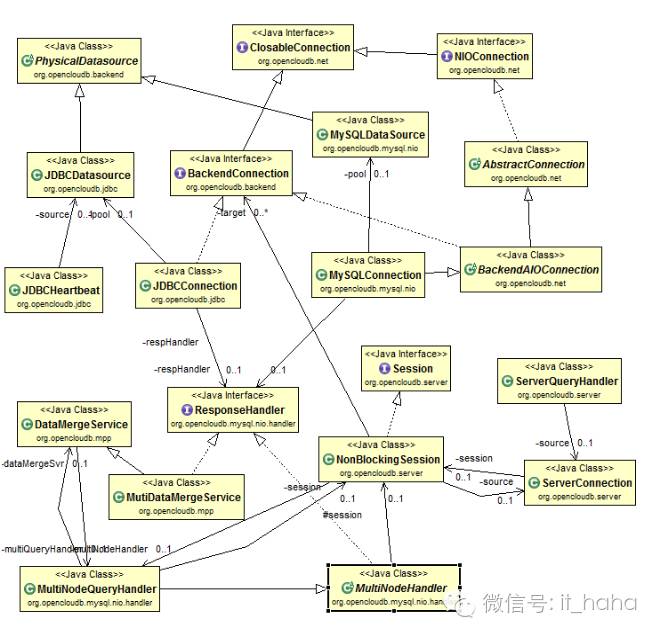
JDBCDatasource
JDBCDatasource继承PhysicalDatasource
初始化的时候加载支持数据库的驱动
static { // 加载可能的驱动
List<String> drivers = Lists.newArrayList("com.mysql.jdbc.Driver", "org.opencloudb.jdbc.mongodb.MongoDriver", "oracle.jdbc.OracleDriver", "com.microsoft.sqlserver.jdbc.SQLServerDriver","org.apache.hive.jdbc.HiveDriver","com.ibm.db2.jcc.DB2Driver","org.postgresql.Driver");
for (String driver : drivers) {
try{
Class.forName(driver);
} catch (ClassNotFoundException ignored) {
}
}
}
创建连接的时候,从配置文件中获取host,port,dbtype,还有连接数据库的url,User,Password
public void createNewConnection(ResponseHandler handler,
String schema) throws IOException {
DBHostConfig cfg = getConfig();
JDBCConnection c = new JDBCConnection();
c.setHost(cfg.getIp());
c.setPort(cfg.getPort());
c.setPool(this);
c.setSchema(schema);
c.setDbType(cfg.getDbType());
try {
// TODO 这里应该有个连接池
Connection con = getConnection();
// c.setIdleTimeout(pool.getConfig().getIdleTimeout());
c.setCon(con); // notify handler
handler.connectionAcquired(c);
} catch (Exception e) {
handler.connectionError(e, c);
}
}
获取连接的时候,判断是否配置的初始化语句,如果存在,就执行初始化语句,此功能可用于设置日期格式,字符集等
Connection getConnection() throws SQLException {
DBHostConfig cfg = getConfig();
Connection connection = DriverManager.getConnection(cfg.getUrl(),
cfg.getUser(), cfg.getPassword());
String initSql=getHostConfig().getConnectionInitSql();
if(initSql!=null&&!"".equals(initSql)) //初始化语句是否存在
{
Statement statement =null;
try{
statement = connection.createStatement();
statement.execute(initSql);
}finally{
if(statement!=null){
statement.close();
}
}
}
return connection;
}
mycat 又从哪里创建JDBCDatasource的呢?
请看org.opencloudb.ConfigInitializer.
判断是否dbType是mysql并且dbDriver是native,使用MySQLDataSource连接后台数据库,如果dbDriver是jdbc就使用JDBCDatasource连接后台数据库,否则抛出异常。
private PhysicalDatasource[] createDataSource(DataHostConfig conf, String hostName, String dbType, String dbDriver, DBHostConfig[] nodes, boolean isRead) { PhysicalDatasource[] dataSources = new PhysicalDatasource[nodes.length]; if (dbType.equals("mysql") && dbDriver.equals("native")) { for (int i = 0; i < nodes.length; i++) { nodes[i].setIdleTimeout(system.getIdleTimeout()); MySQLDataSource ds = new MySQLDataSource(nodes[i], conf, isRead); dataSources[i] = ds; } } else if(dbDriver.equals("jdbc"))//是jdbc方式 { for (int i = 0; i < nodes.length; i++) { nodes[i].setIdleTimeout(system.getIdleTimeout()); JDBCDatasource ds = new JDBCDatasource(nodes[i], conf, isRead); dataSources[i] = ds; } } else { throw new ConfigException("not supported yet !" + hostName); } return dataSources; }
JDBCConnection
JDBCConnection主要做两件事情,就是执行SQL语句,然后把执行结果发回给mpp(SQL合并引擎,mycat处理多节点结果集排序,分组,分页),需要实现ResponseHandler的接口。
下面来分析下执行SQL语句的代码:
创建线程Runnable,在线程中执行executeSQL的方法,并把线程放入MycatServer的线程池中执行,据测试,比不用线程方式执行SQL语句效率提高20%-30%。
public void execute(final RouteResultsetNode node, final ServerConnection source, final boolean autocommit) throws IOException { Runnable runnable=new Runnable() { @Override public void run() { try { executeSQL(node, source, autocommit); } catch (IOException e) { throw new RuntimeException(e); } } } ; MycatServer.getInstance().getBusinessExecutor().execute(runnable); }
执行SQL语句的过程,先判断是select,或show语句还是ddl语句
1:如果是show指令,并且不是mysql数据库,执行ShowVariables.execute,构造mysql的固定信息包
2:如果是SELECT CONNECTION_ID()语句,执行ShowVariables.justReturnValue,也是构造mysql的固定信息包
3:如果是SELECT语句,执行并且有返回结果数据集
4:如果是DDL语句,执行并且返回OkPacket
private void executeSQL(RouteResultsetNode rrn, ServerConnection sc, boolean autocommit) throws IOException {
String orgin = rrn.getStatement();
if (!modifiedSQLExecuted && rrn.isModifySQL()) {
modifiedSQLExecuted = true;
}
try {
if (!this.schema.equals(this.oldSchema)) {//判断
con.setCatalog(schema);
this.oldSchema = schema;
}
if (!this.isSpark){//spark sql ,hive 不支持事务
con.setAutoCommit(autocommit);
}
int sqlType = rrn.getSqlType(); //判断是否是查询或者mysql的show指令
if (sqlType == ServerParse.SELECT || sqlType == ServerParse.SHOW ) {
if ((sqlType ==ServerParse.SHOW) && (!dbType.equals("MYSQL")) ){ ShowVariables.execute(sc, orgin,this);//show指令的返回结果 } else if("SELECT CONNECTION_ID()".equalsIgnoreCase(orgin)) { ShowVariables.justReturnValue(sc, String.valueOf(sc.getId()),this); }else {
ouputResultSet(sc, orgin);//执行select语句,并处理结果集
}
} else {//sql ddl 执行
executeddl(sc, orgin);
}
} catch (SQLException e) {//异常处理
String msg = e.getMessage();
ErrorPacket error = new ErrorPacket();
error.packetId = ++packetId;
error.errno = e.getErrorCode();
error.message = msg.getBytes(); //触发错误数据包的响应事件 this.respHandler.errorResponse(error.writeToBytes(sc), this);
} finally {
this.running = false;
} }
ouputResultSet(sc, orgin);//执行select语句,并处理结果集
stmt = con.createStatement();
rs = stmt.executeQuery(sql); 执行sql语句
List<FieldPacket> fieldPks = new LinkedList<FieldPacket>();//创建字段列表 //把字段的元数据转换为mysql的元数据并放入fieldPks中,主要是数据类型 ResultSetUtil.resultSetToFieldPacket(sc.getCharset(), fieldPks, rs, this.isSpark);
把字段信息封装成mysql的网络封包
int colunmCount =fieldPks.size();
ByteBuffer byteBuf = sc.allocate();
ResultSetHeaderPacket headerPkg = new ResultSetHeaderPacket();
headerPkg.fieldCount = fieldPks.size();
headerPkg.packetId = ++packetId;
byteBuf = headerPkg.write(byteBuf, sc, true);
byteBuf.flip();
byte[] header = new byte[byteBuf.limit()];
byteBuf.get(header);
byteBuf.clear();
List<byte[]> fields = new ArrayList<byte[]>(fieldPks.size());
Iterator<FieldPacket> itor = fieldPks.iterator();
while (itor.hasNext()) {
FieldPacket curField = itor.next();
curField.packetId = ++packetId;
byteBuf = curField.write(byteBuf, sc, false);
byteBuf.flip();
byte[] field = new byte[byteBuf.limit()];
byteBuf.get(field);
byteBuf.clear();
fields.add(field);
itor.remove();
}
EOFPacket eofPckg = new EOFPacket();
eofPckg.packetId = ++packetId;
byteBuf = eofPckg.write(byteBuf, sc, false);
byteBuf.flip();
byte[] eof = new byte[byteBuf.limit()];
byteBuf.get(eof);
byteBuf.clear();
//触发收到字段数据包结束的响应事件
this.respHandler.fieldEofResponse(header, fields, eof, this);
遍历结果数据集ResultSet,并把每一条记录封装成一个数据包,数据发送完成,还需要在封装一个行结束的数据包
// output row
while (rs.next()) {
RowDataPacket curRow = new RowDataPacket(colunmCount);
for (int i = 0; i < colunmCount; i++) {
int j = i + 1;
curRow.add(StringUtil.encode(rs.getString(j), sc.getCharset()));
}
curRow.packetId = ++packetId;
byteBuf = curRow.write(byteBuf, sc, false);
byteBuf.flip();
byte[] row = new byte[byteBuf.limit()];
byteBuf.get(row);
byteBuf.clear();
//触发收到行数据包的响应事件
this.respHandler.rowResponse(row, this);
} // end row
eofPckg = new EOFPacket();
eofPckg.packetId = ++packetId;
byteBuf = eofPckg.write(byteBuf, sc, false);
byteBuf.flip();
eof = new byte[byteBuf.limit()];
byteBuf.get(eof);
//收到行数据包结束的响应处理
this.respHandler.rowEofResponse(eof, this);
JDBCHeartbeat
JDBCHeartbeat就是定时执行schema.xml中dataHost的heartbeat语句。
在启动的时候判断心跳语句是否为空,如果为空则执行stop(),后面再执行heartbeat()方法时,直接返回。
public class JDBCHeartbeat extends DBHeartbeat{
private final ReentrantLock lock;
private final JDBCDatasource source;
private final boolean heartbeatnull;
public JDBCHeartbeat(JDBCDatasource source) {
this.source = source;
lock = new ReentrantLock(false);
this.status = INIT_STATUS;
this.heartbeatSQL = source.getHostConfig().getHearbeatSQL().trim(); this.heartbeatnull= heartbeatSQL.length()==0;//判断心跳语句是否为空 }
@Override
public void start()//启动
{
if (this.heartbeatnull){
stop();
return;
}
lock.lock();
try {
isStop.compareAndSet(true, false);
this.status = DBHeartbeat.OK_STATUS;
} finally{
lock.unlock();
}
}
@Override
public void stop()//停止
{
lock.lock();
try{
if (isStop.compareAndSet(false, true)) {
isChecking.set(false);
}
} finally {
lock.unlock();
}
}
....
@Override
public void heartbeat()//执行心跳语句
{
if (isStop.get()) return;
lock.lock();
try {
isChecking.set(true);
try (Connection c = source.getConnection()){
try (Statement s = c.createStatement()){
s.execute(heartbeatSQL);
}
}
status = OK_STATUS;
} catch (SQLException ex) {
status = ERROR_STATUS;
} finally {
lock.unlock();
this.isChecking.set(false);
}
}
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

