h2o机器学习算法框架学习总结
H2O
官网: http://www.h2o.ai/
H2o 开源的机器学习框架,支持 glm , rf , gbm ,深度学习等算法,借助 hadoop spark 计算平台,实现 large scale 机器学习
H2o 机器学习包 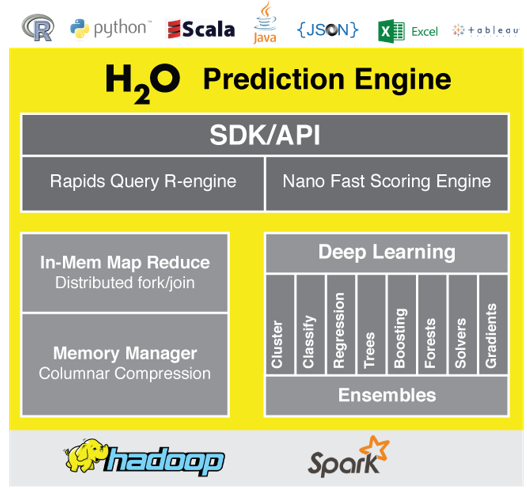
Python 版本 https://pypi.python.org/pypi/h2o/
基于 h2o 的 gbm 参数调整实验
https://github.com/h2oai/h2o-3/blob/master/h2o-docs/src/product/tutorials/gbm/gbmTuning.Rmd
1 下载安装 R h2o
install.packages("h2o")
2 启动 h2o
> library(h2o)
> h2o.init(nthreads = 3)
Connection successful!
R is connected to the H2O cluster:
H2O cluster uptime: 5 hours 9 minutes
H2O cluster version: 3.8.2.6
H2O cluster name: H2O_started_from_R_xxx_phg216
H2O cluster total nodes: 1
H2O cluster total memory: 1.42 GB
H2O cluster total cores: 4
H2O cluster allowed cores: 3
H2O cluster healthy: TRUE
H2O Connection ip: localhost
H2O Connection port: 54321
H2O Connection proxy: NA
R Version: R version 3.2.3 (2015-12-10)
3 导入数据
## 'path' can point to a local file, hdfs, s3, nfs, Hive, directories, etc.
df <- h2o.importFile(path = "http://s3.amazonaws.com/h2o-public-test-data/smalldata/gbm_test/titanic.csv")
dim(df)
head(df)
tail(df)
summary(df,exact_quantiles=TRUE)
## pick a response for the supervised problem
response <- "survived"
## the response variable is an integer, we will turn it into a categorical/factor for binary classification
df[[response]] <- as.factor(df[[response]])
## use all other columns (except for the name) as predictors
predictors <- setdiff(names(df), c(response, "name"))
4 数据切分
splits <- h2o.splitFrame(
data = df,
ratios = c(0.6,0.2), ## only need to specify 2 fractions, the 3rd is implied
destination_frames = c("train.hex", "valid.hex", "test.hex"), seed = 1234
)
train <- splits[[1]]
valid <- splits[[2]]
test <- splits[[3]]
5 基础模型
## We only provide the required parameters, everything else is default
gbm <- h2o.gbm(x = predictors, y = response, training_frame = train)
## Show a detailed model summary
gbm
## Get the AUC on the validation set
h2o.auc(h2o.performance(gbm, newdata = valid))
6 模型调参优化
## Depth 10 is usually plenty of depth for most datasets, but you never know hyper_params = list( max_depth = seq(1,29,2) )
#hyper_params = list( max_depth = c(4,6,8,12,16,20) ) ##faster for larger datasets grid <- h2o.grid(
## hyper parameters
hyper_params = hyper_params,
## full Cartesian hyper-parameter search
search_criteria = list(strategy = "Cartesian"),
## which algorithm to run
algorithm="gbm",
## identifier for the grid, to later retrieve it
grid_id="depth_grid",
## standard model parameters
x = predictors,
y = response,
training_frame = train,
validation_frame = valid,
## more trees is better if the learning rate is small enough
## here, use "more than enough" trees - we have early stopping
ntrees = 10000,
## smaller learning rate is better
## since we have learning_rate_annealing, we can afford to start with a bigger learning rate
learn_rate = 0.05,
## learning rate annealing: learning_rate shrinks by 1% after every tree
## (use 1.00 to disable, but then lower the learning_rate)
learn_rate_annealing = 0.99,
## sample 80% of rows per tree
sample_rate = 0.8,
## sample 80% of columns per split
col_sample_rate = 0.8,
## fix a random number generator seed for reproducibility
seed = 1234,
## early stopping once the validation AUC doesn't improve by at least 0.01% for 5 consecutive scoring events
stopping_rounds = 5,
stopping_tolerance = 1e-4,
stopping_metric = "AUC",
## score every 10 trees to make early stopping reproducible (it depends on the scoring interval)
score_tree_interval = 10
## by default, display the grid search results sorted by increasing logloss (since this is a classification task) grid
## sort the grid models by decreasing AUC sortedGrid <- h2o.getGrid("depth_grid", sort_by="auc", decreasing = TRUE)
sortedGrid ## find the range of max_depth for the top 5 models topDepths = sortedGrid@summary_table$max_depth[1:5]
minDepth = min(as.numeric(topDepths))
maxDepth = max(as.numeric(topDepths))
hyper_params = list(
## restrict the search to the range of max_depth established above
max_depth = seq(minDepth,maxDepth,1),
## search a large space of row sampling rates per tree
sample_rate = seq(0.2,1,0.01),
## search a large space of column sampling rates per split
col_sample_rate = seq(0.2,1,0.01),
## search a large space of column sampling rates per tree
col_sample_rate_per_tree = seq(0.2,1,0.01),
## search a large space of how column sampling per split should change as a function of the depth of the split
col_sample_rate_change_per_level = seq(0.9,1.1,0.01),
## search a large space of the number of min rows in a terminal node
min_rows = 2^seq(0,log2(nrow(train))-1,1),
## search a large space of the number of bins for split-finding for continuous and integer columns
nbins = 2^seq(4,10,1),
## search a large space of the number of bins for split-finding for categorical columns
nbins_cats = 2^seq(4,12,1),
## search a few minimum required relative error improvement thresholds for a split to happen
min_split_improvement = c(0,1e-8,1e-6,1e-4),
## try all histogram types (QuantilesGlobal and RoundRobin are good for numeric columns with outliers)
histogram_type = c("UniformAdaptive","QuantilesGlobal","RoundRobin")
search_criteria = list(
## Random grid search
strategy = "RandomDiscrete",
## limit the runtime to 60 minutes
max_runtime_secs = 3600,
## build no more than 100 models
max_models = 100,
## random number generator seed to make sampling of parameter combinations reproducible
seed = 1234,
## early stopping once the leaderboard of the top 5 models is converged to 0.1% relative difference
stopping_rounds = 5,
stopping_metric = "AUC",
stopping_tolerance = 1e-3
grid <- h2o.grid(
## hyper parameters
hyper_params = hyper_params,
## hyper-parameter search configuration (see above)
search_criteria = search_criteria,
## which algorithm to run
algorithm = "gbm",
## identifier for the grid, to later retrieve it
grid_id = "final_grid",
## standard model parameters
x = predictors,
y = response,
training_frame = train,
validation_frame = valid,
## more trees is better if the learning rate is small enough
## use "more than enough" trees - we have early stopping
ntrees = 10000,
## smaller learning rate is better
## since we have learning_rate_annealing, we can afford to start with a bigger learning rate
learn_rate = 0.05,
## learning rate annealing: learning_rate shrinks by 1% after every tree
## (use 1.00 to disable, but then lower the learning_rate)
learn_rate_annealing = 0.99,
## early stopping based on timeout (no model should take more than 1 hour - modify as needed)
max_runtime_secs = 3600,
## early stopping once the validation AUC doesn't improve by at least 0.01% for 5 consecutive scoring events
stopping_rounds = 5, stopping_tolerance = 1e-4, stopping_metric = "AUC",
## score every 10 trees to make early stopping reproducible (it depends on the scoring interval)
score_tree_interval = 10,
## base random number generator seed for each model (automatically gets incremented internally for each model)
seed = 1234
## Sort the grid models by AUC sortedGrid <- h2o.getGrid("final_grid", sort_by = "auc", decreasing = TRUE)
sortedGrid 7 模型验证和测试
gbm <- h2o.getModel(sortedGrid@model_ids[[1]])
print(h2o.auc(h2o.performance(gbm, newdata = test)))
交叉验证
for (i in 1:5) {
gbm <- h2o.getModel(sortedGrid@model_ids[[i]])
cvgbm <- do.call(h2o.gbm,
## update parameters in place
p <- gbm@parameters
p$model_id = NULL ## do not overwrite the original grid model
p$training_frame = df ## use the full dataset
p$validation_frame = NULL ## no validation frame
p$nfolds = 5 ## cross-validation
print(gbm@model_id)
print(cvgbm@model$cross_validation_metrics_summary[5,]) ## Pick out the "AUC" row
} gbm <- h2o.getModel(sortedGrid@model_ids[[1]])
preds <- h2o.predict(gbm, test)
head(preds) gbm@model$validation_metrics@metrics$max_criteria_and_metric_scores
web ui 查看各种结果,模型,评估等等
http://localhost:54321/flow/index.html
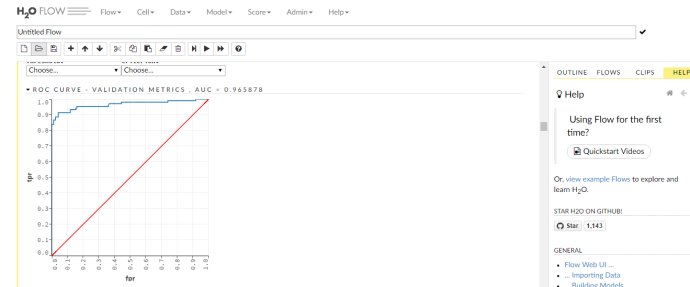
结果保存
h2o.saveModel(gbm, "/tmp/bestModel.csv", force=TRUE)
h2o.exportFile(preds, "/tmp/bestPreds.csv", force=TRUE)
8 模型部署
h2o.download_pojo(gbm) 得到 pojo 代码
通过 java 打分服务,可以将模型部署到实际工业应用场景
( 1 )下载 pojo 代码 javabean
$ mkdir experiment
$ cd experiment
$ mv ~/Downloads/gbm_pojo_test.java .
$ curl http://localhost:54321/3/h2o-genmodel.jar > h2o-genmodel.jar
( 2 )编写 打分程序
import java.io.*;
import hex.genmodel.easy.RowData;
import hex.genmodel.easy.EasyPredictModelWrapper;
import hex.genmodel.easy.prediction.*;
public class main {
private static String modelClassName = "gbm_pojo_test";
public static void main(String[] args) throws Exception {
hex.genmodel.GenModel rawModel;
rawModel = (hex.genmodel.GenModel) Class.forName(modelClassName).newInstance();
EasyPredictModelWrapper model = new EasyPredictModelWrapper(rawModel);
RowData row = new RowData();
row.put("Year", "1987");
row.put("Month", "10");
row.put("DayofMonth", "14");
row.put("DayOfWeek", "3");
row.put("CRSDepTime", "730");
row.put("UniqueCarrier", "PS");
row.put("Origin", "SAN");
row.put("Dest", "SFO");
BinomialModelPrediction p = model.predictBinomial(row);
System.out.println("Label (aka prediction) is flight departure delayed: " + p.label);
System.out.print("Class probabilities: ");
for (int i = 0; i < p.classProbabilities.length; i++) {
if (i > 0) {
System.out.print(",");
}
System.out.print(p.classProbabilities[i]);
}
System.out.println("");
}
}
( 3 )编译,输出打分结果
$ javac -cp h2o-genmodel.jar -J-Xmx2g -J-XX:MaxPermSize=128m gbm_pojo_test.java main.java
$ java -cp .:h2o-genmodel.jar main
The following output displays:
Label (aka prediction) is flight departure delayed: YES
Class probabilities: 0.4790490513429604,0.5209509486570396
9 关闭 h2o 集群
> h2o.shutdown()
Are you sure you want to shutdown the H2O instance running at http://localhost:54321/ (Y/N)? n
[1] TRUE 参考:
[1] http://blog.h2o.ai/
[2] https://github.com/h2oai
总结,相对于其他开源的机器学习算法包,h2o是一个机器学习产品,更加好用适用,从实际问题出发,结合茶品的思维,开发实现的机器学习框架,适合工业应用。
正文到此结束
- 本文标签: update ip cat 代码 开发 src 2015 java mina 产品 GitHub 参数 lib 下载 rmi node find IDE REST build python tab nfs 数据 list Connection ACE 深度学习 Hadoop tar UI DOM Amazon http ORM 测试 安装 HTML 开源 ECS bean 编译 https HDFS App 总结 ask Action web git 集群 CTO final core IOS
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

