“人脸检测”背后的奥秘
人类所感知的外界信息80%以上来自于视觉。目标感知是视觉系统的基本功能,为人类了解周围的环境和景物提供了至关重要的信息。人类天生具有这样一种能力,可以从纷繁复杂的外部世界中,迅速而准确地找到感兴趣的物体,如街道、人脸、行人、汽车、文字、建筑物等。目前,即使最好的计算机系统也难以模仿上述人类视觉系统的过程。
人脸目标的自动获取与识别在视频监控、人机交互和电子商务安全等领域具有很高的应用价值。与人脸目标相关的研究主要包括人脸检测与人脸识别。最初人脸研究主要集中在人脸识别领域,而且早期的人脸识别算法是在假设已经得到一个正面人脸或者人脸很容易获得的情况下进行的。随着人脸应用范围的不断扩大和实际系统需求的不断提高,以上假设往往不复存在,因此,人脸检测开始作为独立的研究内容发展起来。目前,国内外的文献中所涉及的人脸检测算法已经有很多种,许多重要的国际会议和期刊也都涉及人脸检测问题。人脸检测的例子如图1所示。
人脸检测是一个具有挑战性的目标检测问题,主要体现在两方面。一方面是由于人脸目标内在的变化所引起,包括:①人脸具有相当复杂的细节变化和不同的表情(眼、嘴的开与闭等),不同的人脸具有不同的外貌,如脸形、肤色等;②人脸的遮挡,如眼镜、头发和头部饰物等。另一方面是由于外在条件变化所引起,包括:①由于成像角度的不同造成人脸的多姿态,如平面内旋转、深度旋转以及上下旋转等,其中深度旋转影响较大;②光照的影响,如图像中的亮度、对比度的变化和阴影等;③图像的成像条件,如摄像设备的焦距、成像距离等。

图1 人脸检测的示例
一、人脸检测数据库
人脸图像数据库对于算法的研究、训练和测试是不可或缺的。在算法训练阶段,所采用的人脸库的规模、光照条件、表情、姿势等在很大程度上影响着算法的精度和鲁棒性。在算法测试时所用到的人脸数据库的规模同样决定了实验设计的合理性和结果的有效性。以下介绍3 个在人脸检测中常用的人脸数据库。
1. MIT 人脸检测数据库
该数据库由麻省理工学院多媒体实验室(MIT MediaLaboratory)于1989 年建立,训练集合中包含了2429 幅人脸图像,4548 幅非人脸图像;测试集合中包含了472 幅人脸图像,23 573 幅非人脸图像。
2.CMU人脸检测数据库
该数据库由卡耐基梅隆大学计算机系建立,包含了训练集合与测试集合,实际应用中较多使用其测试集合。CMU 人脸库包含了CMU 与MIT 数据库的人脸检测测试图像,分为A、B、C 三个正面人脸测试集合与一个旋转人脸测试集合。
3.LFW 自然环境人脸数据库
LFW 人脸数据库是一个在自然拍摄条件下采集的较大规模的数据库,包含了各种光照、姿态、表情的人脸图像。该数据库包含了彩色图像和灰色图像两个版本,共有5749 个人,每个人有1~10 张左右的人脸图像,同一个人的图像存放在同一个目录下,并以姓名作为目录名。总共有26 466 张人脸图像,是做人脸识别、人脸检测等研究的常用数据库。
二、脸检测的计算模型
通常所说的人脸检测是基于光学图像定位出现的人脸的具体位置和大小的简称。光学图像中的人脸图像(简称人脸图像)是外界光源(包括太阳、室内人造光源和其他物体表面反射)发出的光线照射在人脸上,经人脸表面反射后传播到电荷耦合元件(Charge-CoupledDevice,CCD)的光线强度的度量。
一般来说,一幅人脸图像是一个3D 的人头或者一幅2D 人脸图像在一定光照条件下的2D 投影。人脸图像的变化可由许多因素导致,具体来说,这一成像过程实际上涉及以下三大类关键要素。
1. 人脸内部属性
包括人脸组件(眼睛,鼻子和嘴巴等)的基本形状、人脸表面的反射属性(如反射系数等,通常简称为纹理)、人脸的3D 形状(表面法向量方向),以及人脸表情、胡须等属性的变化。
2. 外部成像条件
包括光源(位置和强度等)、其他物体(比如眼镜、帽子)或者人体其他部件(如头发)对人脸的遮挡、头部姿态等。
3. 摄像机成像参数
摄像机成像参数包括摄像机位置(视点),摄像机的焦距、光圈、快门速度,成像设备的畸变等内外部参数。
人脸表面3D 结构及其反射属性是人脸相对稳定的本质属性;而人脸表情变化、有无胡须等属于人脸内部属性,它们并不能改变人脸区别于非人脸的本质属性。至于光源等外部成像条件以及摄像机参数等外部因素就更不能作为人脸检测所依赖的特征属性。
三、人脸检测算法
1.基于肤色特征的检测
过去若干年中对于肤色检测问题的研究有很多,这为人脸检测中使用肤色特征打下了良好的基础。Jones 等基于大量的样本图像对肤色检测问题进行了统计分析,比较了用直方图模型和混合高斯模型进行肤色检测的情况;Martinkauppi 等对不同光照条件下的肤色分布问题作了细致分析,指出在特定的摄像机条件下,各种光照条件下的肤色分布可以用两个二次或者多次的多项式来完全描述,这为解决肤色光照问题提供了依据。
肤色用于人脸检测时,可采用不同的建模方法,主要有高斯模型、高斯混合模型,以及非参数估计等。利用高斯模型和高斯混合模型可以在不同颜色空间中建立肤色模型来进行人脸检测。Soriano 等建立的肤色模型通过提取彩色图像中的面部区域以实现人脸检测,该方法能够处理多种光照的情况,但是算法需要在固定摄像机参数的前提下才有效。Comaniciu 等提出使用非参数的核函数概率密度估计法来建立肤色模型,并使用mean-shift 方法进行局部搜索实现了人脸的检测和跟踪。其方法提高了人脸的检测速度,对于遮挡和光照也有一定的鲁棒性。该方法的不足是和其他方法的可结合性不是很高,同时,用于人脸检测时,处理复杂背景和多个人脸时存在困难。
为了解决光照问题,可以针对不同光照进行补偿,然后再检测图像中的肤色区域,如图2所示。这样可以解决彩色图像中偏光、背景复杂和多个人脸的检测问题,但对人脸色彩、位置、尺度、旋转、姿态和表情等具有不敏感性。

图2 肤色检测
(a) 黄色光照条件下的图像;(b)检测到的肤色(白色部分);(c)光照补偿后的图像;(d)从图(c)中检测到的肤色
使用肤色和形状信息来定位人脸和提取面部特征的方法,可在HSV 颜色空间中进行颜色分割以确定肤色区域,然后在低分辨率图像中进行区域增长实现各肤色区域的连接。对于每个连通区域,用几何矩的方法拟合椭圆区域,并将那些与椭圆相近的连通区域作为候选的人脸。接下来,在这些候选的区域中进行面部特征的匹配以确认人脸目标所在的范围。
2.基于边缘特征的检测
利用图像的边缘特征检测人脸时,其计算量相对较小,可以实现实时检测。大多数使用边缘特征的算法都是基于人脸的边缘轮廓特性,利用建立的模板(如椭圆模版)进行匹配。也有研究者采用椭圆环模型与边缘方向特征,实现简单背景的人脸检测。Fröba 等采用基于边缘方向匹配(Edge-Orientation Matching,EOM)的方法,在边缘方向图(图3)中进行人脸检测。该算法在复杂背景下误检率比较高,但是与其他的特征相融合后可以获得很好的效果。

图3 图像边缘方向的向量场示例
3.基于级联Adaboost 与SVM 的检测
图4 中的人脸检测系统级联了两个人脸检测器,第一个是采用Adaboost 算法学习得到的检测器,第二个是采用SVM 算法学习得到的检测器。将Adaboost 算法作为第一级检测器主要是因为该算法不仅计算速度快,而且还可以达到和其他算法相当的性能。采用SVM 算法作为第二级检测器是因为在采用Adaboost 算法学习的过程中,最后总有一些人脸和非人脸模式难以区分,而且其检测的结果中存在一些与人脸模式并不相像的窗口。实验发现,那些Adaboost 算法难以区分的人脸和非人脸模式对于SVM 来说却相对容易区分。同时,采用SVM 作为第二级检测器也可以去除Adaboost 误判断为人脸模式的非人脸窗口。因此,在这种意义上来说,级联Adaboost 和SVM 组成的分类器可以提高人脸检测系统的性能。
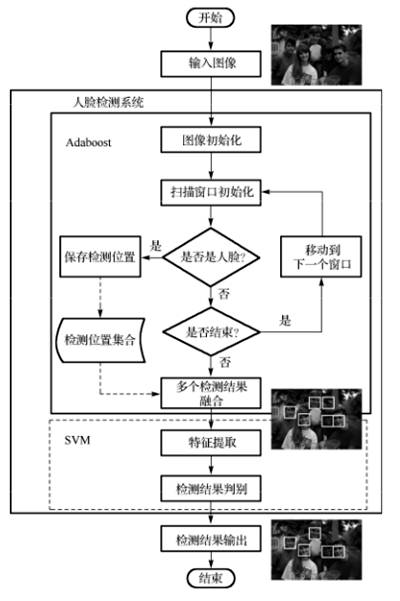
图4 基于级联Adaboost与SVM 人脸检测系统框图
如图4所示,基于级联Adaboost 与SVM 人脸检测器的检测步骤如下:①将输入的图像初始化,主要是计算输入图像的积分图,其中需要对图像进行多次缩放,最终使缩放得到图像的大小和训练的人脸样本相等(20×20),并对所有缩放的图像计算积分图;②对输入检测器的子窗口进行初始化,主要包括对每个输入子窗口的方差归一化(这样可以在一定程度上减弱光照的影响)和输入子窗口的特征值计算;③将这些子窗口的特征值送入Adaboost 分类器进行计算以判断该窗口是否为人脸窗口,并对那些Adaboost 判断为人脸的子窗口保留其大小和位置信息,在Adaboost扫描完一幅图像后,对所有判断为人脸的子窗口进行合并;④对合并后得到的窗口提取特征并送入SVM 进行验证,排除那些不可能是人脸模式的字窗口;⑤输出SVM验证后的人脸子窗口的参数(包括该窗口的大小和位置信息)作为人脸检测系统的输出。图5给出了基于上述流程的人脸检测结果。

图5 人脸检测结果
本文由王芳摘编自焦建彬 叶齐祥 韩振军 李 策 编著的《视觉目标检测与跟踪》(科学出版社.2016.06)一书第4章,内容有删节。
欢迎加入本站公开兴趣群
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

