基础设施服务化需要做哪些事情
基础设施服务化
所谓基础设施服务化就是希望做到这个

当用户需要获取某个基础设施的时候,比如一个redis的集群,或者mysql的集群,可以无需在钉钉上找管理员,无需用邮件提申请。在web界面上自助就可以搞定。
为什么这个问题会特别?相比较一下这两个场景:
1、segmentfault提供了一个写博客的功能,我利用segmentfault开了一个自己的博客。2、aws提供了一个mysql集群管理的功能,我在aws开了自己的mysql集群
从用户体验来说有本质区别吗?不都是通过web界面申请,然后获得了一个用tcp连接对外提供的服务吗?两者的区别在于
1、在segmentfault上申请博客是在已有的segmentfault的cpu和硬盘的资源池里切出来了一份属于我的。这个过程不牵涉到新的进程的启动。2、而mysql集群的申请开通是需要新的机器,需要新的进程。
“业务”和“运维”的分野就在这里。业务就是在不启动新的进程的情况下,用已有进程切分资源给不同用户使用。而运维就是起停进程,以达到扩缩整个资源池大小,给用户提供服务。只要我们做的事情里牵涉到了进程的起停,我就认为我们是在做运维的工作,而不是在做业务逻辑。这些进程管理相关的服务一般都会被罗列一下场景:
1、新版本发布,升级已有集群(停进程,然后再起)
2、已有版本,部署新的集群(起进程)
3、已有集群扩容(起进程)
4、已有集群缩容(停进程)
5、已有集群的故障恢复(进程死了,再拉新的)
所谓的“发布变更”,其实就是围绕进程管理组合出来的一堆服务。这些服务以http rest api之类的形式提供给用户使用。
进程管理的工作分解
我们可以把所有的进程管理工作按这个模型来理解
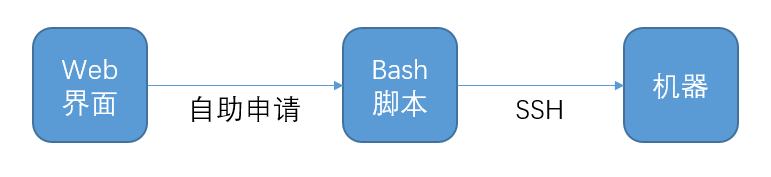
而且我丝毫不怀疑bash脚本套界面的有效性。它可以非常快地达到自助化管理的目的,极大提高用户方的效率。从投入产出比的角度来说,我是支持这么来搞的。
但是运维所有工作的考量应该是有四方面的“效率”,“质量”,“成本”,“安全” https://segmentfault.com/a/1190000002965517 。这种bash脚本套界面的做法就是典型的效率至上,其他都不管的做法。我相信这样的做法是无法兼顾到质量和安全。当你看到一个系统里沉淀了几千个bash脚本,被不同的web界面暴露出去了。你能保证这些bash脚本都是安全的?他们的组合使用的效率又是安全的?
假设我们放弃了直接把一个长长的bash脚本web化的想法。那么我们仔细来看看这些bash脚本都在干什么。概括起来可以分为四个部分

我们来分别看这四个组成部分都是在干什么。最佳的解决方案又是什么。
进程镜像的下发
对于 golang 来说,进程镜像下发可能就是scp拷贝一个可执行文件就行了。但是很多的进程要能启动,需要本地有一对关联的库。
曾经火过一段时间的 infrastructure as code,尝试以描述依赖的方式把这个进程镜像下发和运行时环境的问题描述清楚。但是构建在os的包管理(apt-get,yum),各种语言的包管理(pip,npm)之上外加各种补丁的依赖管理系统到头来还是浮沙之上筑高台。
目前最流行的是docker。它确实根本上解决了单机的依赖管理问题。一个进程该有一个什么样的运行时环境,一个docker镜像就搞定了。
进程拉起
有标配的god或者supervisord,绝对是一种福气。没有标准的进程托管工具,需要自己写各种拉起脚本的,非常低效,而且不容易做到健壮。这个方面还是首选 supervisord,把进程的起停很容易就标准化了。
比进程拉起这个动作更复杂的一个问题是决定在哪里拉起这个进程。所以有mesos,yarn这样的资源管理工具。让进程在多个主机上更合理的分割资源。这个方面可以吹得很厉害,解决了很多成本云云。但是大部分情况下手工静态分配进程和主机的关系,足矣。省成本这个事情,行政命令比高科技管用多了。
进程间通过网络组成拓扑
这是进程管理里最痛苦的部分。当我们启动了这些进程之后,进程之间是需要通过网络互相通信的。如果两个进程是通过本地文件系统的ipc机制通信,我们可以建模地时候把两个进程变成一个进程组,当一个进程看待。那么这个问题就是进程A,要知道进程B在哪里。进程B又要知道进程A在哪里。
传统的做法是进程A有自己的配置文件,这里要填进程B的ip和端口。进程B也有自己的配置文件,这里要填进程A的ip和端口。所以就有一个很复杂的配置管理生成的问题。
更好的做法是让进程去做自动的互相发现。无非就是进程A把自己注册到注册表里,进程B可以从注册表里取到。无论是使用zookeeper,etcd还是consul,这个过程都是类似的。很多复杂一些的开源软件,都会预设一个集群管理方式。比如kafka自己要求有一个zookeeper来管理其内部的几个节点。
即便是有了服务注册和发现,也不是进程随便拉起就撒手不管了。服务注册和发现可以减轻你管理整个网络拓扑的负担,但是不能代替你去规划这个网络拓扑结构。进程启动要加入到一个集群里做自发现,仍然需要知道两个信息,我是什么角色的service,我在什么cluster里。把进程划分为不同的cluster,又分为不同类型的service仍然是要提前规划的。而进程都要挂在具体的cluster的具体的service下。只是说同类型的service启动多个进程了,服务注册和发现可以减轻一些这方面的管理负担。
更复杂的集群可能要牵涉到跨cluster的互相访问。也就是cluster组cluster。这个方面仍然是没有最佳实践的。比如codis集群内,其实是由多个redis group组成。
当我们面对这个一个网络拓扑的管理问题的时候有两个解法。进程自身其实是有一个自身状态描述了这个拓扑的actual state,另外还有一份存在于你的设计文档也好,你的配置管理系统也好,是一个 expected state。我们可以用脚本直接变更actual state,然后再去同步这些state回来到某个dashboard上。或者我们可以先改变dashboard上的expected state,然后再推倒出有哪些action需要做,去变更actual state。两种方式都可以。但是不能只有脚本,而没有任何的state的建模。如果只有脚本,我们对于集群状态在变更之后实际上是什么情况是两眼一抹黑的。我们认为主从切换了,但是是不是主从切换了是不能有一个中心的dashboard可视的。这就很可怕了。
所以无论是不是有服务注册和发现,对集群的拓扑建模,现网状态的可视化都是必不可少的。千万不能只有一堆脚本,kuangkuangkuang执行完了,实际线上是什么个状态完全不知道。
更新与网络拓扑相关的进程状态
大部分的进程状态是不属于运维范畴的。比如安装完了一个订单管理系统,需要把城市列表导入到数据库里。没有人会认为这个城市列表导入会是运维工作的职责。但是安装完了一个codis集群,需要把codis集群里的redis group与slot range对应上,所有人都认为这个应该是运维工作的一部分。为什么?根本原因是data partition的配置,与网络拓扑是相关的。因为网络拓扑是运维来组的,所以凡是和网络拓扑有关的配置,都和运维有关系。
这个和前面的网络相关的配置是类似的。只是在组网的时候,我们认为一个service就是网络的ip和端口两个属性是有价值的。在配置data partition的时候,我们还要知道service具体是负责了什么数据。是负责了热数据还是冷数据。是负责哪个数据分片。如果我们的cluster和service建模得好,管理得好。这些属性完全就是ip和端口之外扩展的kv对而已。如果我们前一个工作做得不好,那么这些更复杂的状态的管理就更加是一个灾难。
数据分片更复杂的一点是它是有状态服务的状态的体现。把一个group迁移一些slot到另外一个group,不仅仅是一个配置变换,不仅仅是进程的起停,还包括这些配置对应的实际数据的搬迁。
但这个问题仍然是一个状态管理的问题。我们有一个注册表登记了group对应了哪些slot,这是一份登记的state。而这个group实际上是不是包含了这些slot,进程自己心里有数,这是一份actual的state。本质上还是state管理,actual state和expected state的同步问题。
总结
现有的运维的工具很好的解决了进程管理中四个问题里最简单的两个问题,镜像的下发(docker)和进程拉起(supervisord)。但是对于组网和数据分片管理,这两个state management问题,仍然有太多的open question。更多的解决方案是个例地,脚本化的解决一些问题。没有一个framework来系统性地对集群状态管理问题给一个解决方案。也就是说文章的标题“基础设施服务化需要做哪些事情”,我也不知道。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

