Java并发原理无废话指南
你们要的后续我写了,如果喜欢请把账号推荐给你的朋友,谢谢。
进程、线程和并发实体
《操作系统原理》里面很重要的一个概念是进程。进程是程序动态的概念,它 用来表示程序在执行的一组数据结构 。这组数据结构中记录了指令加载到内存中的地址,打开的文件,线程信息,共享内存等。
每个进程可以有多个线程。它也是一组数据结构包括:下一条要执行的指令,寄存器,堆栈,状态等。一幅图来表示
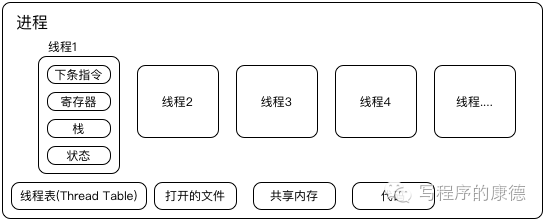
上图画出了4个线程(线程2、3、4和1是一样的,没有全画),如果程序没有启动任何线程,其实也会用到线程——主线程(图中的线程1)。 所以最后消耗CPU的线程而不是进程
其实在Linux中(我实在不知道Windows,我猜应该差不多)进程和线程是同一个数据结构——task_struct,对于内核(kernel)来说并没有进程和线程的区别,只有进程——kernel称之为task。所以 在Linux中进程和线程并没有父子关系而是平行的结构 ,表示进程的数据结构填充的数据多一些,包括了打开文件,共享内存之类的,这个被称为主线程;其他线程的数据结构这些项目则为空,并且有一个“父进程”的指针,指向了“主线程”。
明白了这一点我们就清楚了, 操作系统调度的最小对象其实是——线程 ,但是名字叫task,教科书上叫进程。。。。有点混乱了吗?所以我们引入一个新的术语—— 并发实体 。所有CPU调度的最小单位我们统称为并发实体,无论是进程还是线程或者是其他的什么“怪胎”。(没错,我会在下一次介绍这些怪胎。)
为什么要线程
勇敢提出这个问题的人要受到表扬,他冒着被无情嘲讽的危险提出了一个很白痴的问题。(我觉得回答不出来这个问题的人,才是真正的白痴)回答这个问题要回答另一个基本的问题——为什么要并发
我们想象一下,一个Web服务器,可能是下面的代码
while (true){ request = next_http_request() request_work(request) }程序循环获取新请求(next_http_request),执行请求(request_work),然后继续下一次循环。request_work会从硬盘读取文件,然后发送给客户端作为HTTP的响应,而硬盘I/O是一个阻塞操作,也就是说request_work会一直等待读取完数据之后才能释放CPU的控制权,然后下一个请求才有机会被执行。
这就是并发要解决的问题,当request_work发起I/O之后CPU是完全空闲下来的,而可怜的新请求(next_http_request)必须等待I/O完成之后才可以获取CPU的控制权。所以CPU的利用率非常低, 并发要解决的问题就是提高CPU的利用率 。明白这一点我们也就清楚了,并发只对非CPU密集型程序管用,如果CPU利用率非常高,更多的并发只会让情况更加糟糕
那么并发为什么一定是多线程而不是多进程呢?其实在Linux下进程和线程的创建成本没有什么区别(都是task_struct),但是进程之间可以共享数据的方式只能通过非常复杂的IPC来实现, 线程之间代码都是共享的,地址空间也是共享的,所以共享数据的方式更加高效。 (进程要考虑隔离,一个进程没有办法直接访问另一个进程;线程不用隔离,线程之间共享内存)
我们修改成多线程版本的Web服务器
while (true){ request = next_http_request() request_work_in_thread(request) }request_work_in_thread方法会启动一个线程(work线程),然后CPU开始执行next_http_request获得下一个请求。
request对象是在主线程创建的,可以直接传递给request_work_in_thread中的work线程使用。
我们提高CPU利用率所以需要并行,我们要提高并发实体之间共享数据的效率所以选择了线程作为并发实体的实现
Java的线程
好了,回到了Java。在Java中启动一个线程非常简单——只要new Thread就搞定了。JVM会把它变成操作系统的API,如果是Linux则会生成一个task_struct的结构。至于Runable之类的东西其实最后还是Thread,即便是Java并发包最后也还是用Thread。
所以至此,我们成功把《操作系统原理》中进程、线程和Java的线程“融汇贯通了”。下面开始另一个东西——PV操作。
竞争条件,临界区、PV信号量
恩,你这一部分估计也已经还给老师了。没关系,我们一起回忆一下。
举个例子:
public void plus(int value){ count = count + value; }当多线程同时调用plus的时候程序的逻辑是错误的。count+value并不是一个原子操作,它会被变成三个CPU指令
-
获取count的数据到寄存器(还记得吗?CPU只访问寄存器)
-
寄存器+value,并且写回寄存器
-
寄存器写回到内存
如果T1,T2两个线程同时执行(count=0)
-
T1 获取count的数据到寄存器
-
T1 将寄存器的值加10
-
T2 获取count的数据到寄存器
-
T2 将寄存器的值加30
-
T2 寄存器写回到内存(count=30)
-
T1 寄存器写回到内存(count=10)
我们期望的可能是40,但是实际情况是10,因为T2访问数据的时候T1还没有来得及写回到内存中。当两个线程访问同一个数据,最后的结果依赖于线程的顺序这个就叫竞争条件。避免竞争条件的方法就是——通过临界区把一组动作“原子化”。例子中就是把:count = count + value,原子化。(原子化是指一次做完;其他人排队等候。)
就像你去买咖啡,收银员是所有人共享的(竞争条件),如果他经历:问杯型、种类、口味;收费;给你发票,这三个过程不能被打断否则会乱掉的。所以大家需要依次排队。(临界区)
如何实现临界区?答案是PV信号量(也叫PV操作,PV原语)。它是著名“河南籍”计算机科学家——E.W.Dijkstra设计的一套算法,老爷子这套严密的理论是现代并发的基础。简单来说他定义了两个操作
设一个计数器s
-
P s-1,如果s小于0则休眠否则继续执行
-
V s+1,如果s<=0则唤醒等待进程否则继续执行
P操作相当于使用资源,执行这个操作相当于:这个桌子我承包了,你们等我用过之后再用。(如果桌子有人那就只能乖乖等着了)
V操作相当于释放资源,执行这个操作相当于:这个桌子我不用了,下一个是谁?来用吧。(如果没有下一个人,那就直接走人了)
没错,PV就是“锁”。《操作系统原理》中竞争条件、临界区都是现实中不存在的概念,只有PV操作被具体实现了,就是我们称之为锁的东西。
Java中的锁
所有的“锁”都是一种PV操作,锁的区别在于你选择的“计数器”是什么?比如你选择的计数器是当前对象那么对应的关键是“synchronized”(还有个名字叫管程,天真的科学家们觉得面向对象的锁好牛B,就赐予它一个专门的名词),如果你的计数器是一个原子类型的值那么可能就是AtomicInteger的inc或者dec操作。这个就是 锁的粒度 ,锁越小竞争条件就越小。就像你买咖啡,把整个咖啡馆当做“竞争条件”或者把收银员当做“竞争条件”,很像然后者对咖啡馆的利用率更高。(还有一些买过咖啡的人至少可以逗留一会)
总结
我不想在文章中介绍Java的API,并发包的类。(这些介绍资料一抓一大把实在太多了)我的目的是通过回忆基础课程,尝试把我们认为最没用的东西联系到实际中。让大家知道——原来教科书上不是骗人的,真的是无处不在。希望你看完这篇文章,能够默默的去翻开尘封已久的《操作系统原理》。郭德纲老师有句话说:演员和演员最后比拼的是文化底蕴;同样的道理, 程序员和程序员最后比拼的是基础 ,当你羡慕别人“游刃有余”的轻松解决一个很难缠的BUG时;动动手指搞定解决了性能问题时;短时间内迅速领悟到一个新技术时,请不要忘记他在这个背后可能花了几年甚至几十年的功夫在练习被你遗弃的“教科书”。
最后推荐几本靠谱的操作系统书(不要浮躁,每本书都值得我们花上一年半载的慢慢欣赏)
-
现代操作系统 我从未见过如此牛B的操作系统书,没有之一!!!用最通熟易懂的语言,最简单的例子解释最复杂的道理。最牛B的是,它还很现代,非常现代。
-
计算机的心智:操作系统之哲学原理 邹恒明,上海交大的教授写的。本地书的特点就是薄,你喜欢看薄书这个是一个好选择。
-
Linux内核设计与实现,薄书。如果你想了解Linux Kernel有不想太深入,这本书绝对的适合你
欢迎关注公众账号了解更多信息

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

