云计算核心技术dockeer的探索
首先通过一个简单的场景来看一下为什么docker这么火?
开发人员在开发的时候是有一套开发环境,包括运行的操作系统,依赖的服务比如weblogic,java,一些特定的配置,比如jvm大小 ,字符集,操作系统内核参数等,然后就是应用代码了。当开发完成后,开发人员就把代码打包发送运维人员到生产上部署。运维人员就需要搭建一个和开发环境一样的生产环境,安装操作系统 ,weblogic,java,根据基线配置一些参数,过程非常的繁琐。搭建完成后还是可能因为两个环境细微的不同都有可能导致应用程序的部署失败。做为运维人员常常听到开发的抱怨,在我的环境里是正常的啊,怎么到你的环境就不行了呢!
在传统的部署模式下,如果有非常多的服务器,运维工程师需要在每一台服务器上进行相当复杂的操作才能够完成部署。安装->配置->部署。但是docker的出现颠覆了这种传统的模式。我们看一下,docker只需要把整个开发环境做打包成一个docker image,也就是docker镜像给运维团队,而运维团队直接运行就可以了,整个过程就变成打包,传送,运行即可,非常的简单。因为docker镜像包含了所有的环境依赖关系,可以保证开发与生产环境一致,对于开发和运维工作,docker技术可以让开发和运维豁免很多预想之外的工作和相互推脱。此外,容器可以重复运行在任何地方,简单化了运维人员的工作 。 Docker的这种在安全、可重复的环境中可移植,跨平台的快速部署软件的方式也方便做持续集成,所以说docker出现拉开了基于云计算平台发布产品方式的变革序幕,是运维人员的解放,广受开发者和运维人员的欢迎。
Docker ,除了是云时代的应用交付方式的变革,运维人员的解放,和微服务的结合使用还将颠覆传统的软件架构。我们先看一下单块架构和微服务架构的区别。单块架构就是一个实例里包含了多个业务模块,如果说电信行业的登陆,开户,缴费,话费查询等功能都运行在一个实例里,这样做有什么缺点呢?第一,随着业务的增长,这个单块会越来越大,变得很复杂,启动的时间也会越来越长,如果有bug要排查起来也会非常的复杂。第二,如果其中某一个业务模块异常将会影响所有其他的业务模块,造成整个业务系统瘫痪。第三,有些功能业务压力大,有些功能业务压力小,因为捆绑在一起,都只能一起增加或减少,这样就会造成资源的浪费。如果某个功能业务4个实例已经不能支撑了,而其他业务模块其实并没有什么压力,但是为了业务大的功能模块的业务压力,就需要增加一个实例。而微服务架构就可以解决这三个问题,把功能按模块运行在不同的容器里,相互不影响,各用各的资源,可以根据实现的业务压力而来启动相应的实例数。
Docker的细粒度松耦合能够让我们用一个Docker容器装载一个场景功能,让每个Docker中运行一个微服务,为微服务应用程序创建出高效的分布式模型,从而顺利实现微服务概念的现实转化。
那么docker究竟是什么呢?
首先我们来看一下docker的标识,是一个大鲨鱼驮着一堆集装箱在海上航行。无边无尽的海就是云了,大鲨鱼货轮就是云计算平台了,docker是集装箱。集装箱将货运目标标准化,Docker 将应用程序标准化,集装箱里面装的以是任意类型的App,各自在自己的集装箱里运行,相互隔离,共用大鲨鱼货轮的资源,这种封装的集装箱可以放到任何的平台上去运行。非常形像的展示了docker的特性: Build, Ship and Run Any App, Anywhere!在任何平台运行任何应用!
docker的英文本意是码头工人,也就是搬运工,这种搬运工搬运的是集装箱。
Docker是PasS提供商DoctCloud开源的一个基于LXC的高级容器引擎。
Docker是一个由GO语言写的程序运行的“容器” 。
Docker把App装在Container内,通过Linux Container技术的包装将App变成一种标准化的、可移植的、自管理的组件(集装箱)。这种组件可以在你的电脑上开发、调试、运行,最终非常方便和一致地运行在测试环境和生产环境下。
docker诞生的时间并不长,2013年3月发布0.1版本,到现在也才三年多,现在最新的版本是1.12,还在不断的完善中。但docker并不是一种新技术,而是基于Linux内核容器技术LXC的为适应时代需要、标准化IT结构的新方式,一种冲击虚拟化的新玩法。
docker解决LXC的两个问题集成度低,需要手工准备容器内文件系统的两个问题,
docker的整体结构包括两个部分,Docker Hub 和 Docker 引擎组成。Docker Hub提供API和云服务来发布基于Docker的应用程序。Docker Hub 是Docker 官方提供的容器镜像仓库,有大量的软件公司在其中维护自己的官方软件。目前已经有1万4千多个基于Docker的应用程序package,从操作系统的厂商,,云计算IaaS服务商,大数据,像各种各样的编程语言等等各种各样的软件,包含最流行的13个应用-CentOS, MongoDB, MySQL, Nginx, Redis, Ubuntu, and WordPress 等等,在云计算产业迅速发展的环境下拥有越来越丰富的生态系统。后者运行在宿主机上,是一个可以移植的,轻量的应用运行环境和打包工具,负责构建、运行和分发 Docker 容器。简单来说,Docker Hub 是资源存放的云平台,Docker 引擎是使用云上资源资源的终端,任何人都能到云上下载需要的资源,这就是容器云+端开放平台的模式。
下面讲一下在docker的容器云+端开放平台结构下,应用程序的生命周期。先在本地基于Docker引擎构建和打包应用程序,然后用DockerHub云服务将程序(集装箱)放到DockerHub,希望运行此应用的平台再去下载和运行。

Docker号称Build once,run anywhere,就是镜像一次构建,容器到处运行。就像这个图上所示,当使用Docker引擎构建好应用程序后放到DockerHub,开发,测试人员都可以获取,拿来直接运行,可以运行在物理平台上,也可以运行的虚拟平台上。整个过程非常的简单方便,在这种模式下极大地提高了开发部署效率。
简单介绍docker使用到的部分核心技术,但不做深入探究,因为每一个技术都是一个独立的项目,了解一下核心技术的作用就可以了。前面说了,docker是基于LXC的,而LXC的核心就是namespaces,容器隔离和cgroups,资源控制。每个用户实例之间相互隔离, 互不影响。 一般的硬件虚拟化方法给出的方法是VM,而LXC给出的方法是container,更细一点讲就是namespace。
PID,IPC,Network等系统资源不再是全局性的,而是属于某个特定的Namespace。通过使用namespace对cpu、内存、网络和文件系统的隔离,在这种情况下一个容器不会影响另一个容器的资源。不同 namespace 中可以有相同pid,比如说容器A里有个进程号为123,在容器B里也可以存在一个进程号为123。每一个docker容器都有自己的Namespace,在docker用户层只能看到属于自己namespace下的资源。对宿主机来说,docker就是一个进程,但每个namespace看上去就像一个单独的Linux系统。
cgroups控制组可以提供对宿主机上的共享资源内存、CPU、磁盘 IO 等资源的限制和审计管理,限制相应进程或一组进程使用的系统资源,实现了对资源的配额和度量。只有能控制分配到容器的资源,才能避免当多个容器同时运行时的对系统资源的竞争。
AUFS则可以让大家像玩乐高那样玩 Docker。我们先看一下它的结构:容器在最顶层,是writable,其下所有层都为readonly,将readonly的文件系统层称作“image”,每一层镜像的下面称为其父镜像,Docker镜像位于bootfs之上,第一层镜像为Base Image。因此想要从一个image启动一个container,docker会先加载其父image直到base image,用户的进程运行在writeable的layer中。得益于AUFS的特性,每一个对readonly层文件/目录的修改都只会存在于上层的writeable层中。这样由于不存在竞争,多个container可以共享readonly的layer。所以docker将readonly的层称作 "image"——对于container而言整个rootfs都是read-write的,但事实上所有的修改都写入最上层的writeable层中,image不保存用户状态,可以用于模板、重建和复制。
1. 节省存储空间:多个container可以共享base image存储
2. 快速部署:如果要部署多个container,base image可以避免多次拷贝
3. 内存更省:因为多个container共享base image, 以及OS的disk缓存机制,多个container中的进程命中缓存内容的几率大大增加
4. 升级更方便:相比于 copy-on-write 类型的FS,base-image也是可以挂载为可writeable的,可以通过更新base image而一次性更新其之上的container
5. 允许在不更改base-image的同时修改其目录中的文件:所有写操作都发生在最上层的writeable层中,这样可以大大增加base image能共享的文件内容。
在这里我们讲了两个概念,容器和镜像,大家可能还不是很理解,下面就给讲一下docker的三大核心概念。
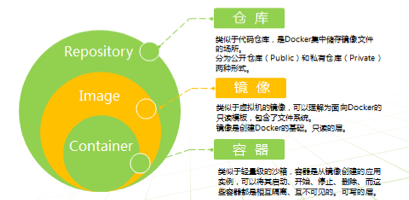
docker三大核心概念是仓库,镜像,容器,从这个图表我们可以知道,仓库里有镜像,容器运行在镜像之上。
仓库类似于代码仓库,是Docker集中储存镜像文件的场所。分为公开仓库(Public)和私有仓库(Private)两种形式。最大的公开仓库就是前面提到的dockerHub,当然,也可以在局域网内构建私有仓库。
镜像类似于虚拟机的镜像,可以理解为面向Docker的只读模板,包含了文件系统。镜像是创建Docker的基础,所有的docker容器都是基于镜像运行。
容器就是前面提到的集装箱,是从镜像创建的应用实例,可以将其启动、开始、停止、删除、而这些容器都是相互隔离、互不可见的。
镜像相应于是java代码写的公用类,而容器是则是基于这个代码运行的实例,每个人都可以调用这个公用类,并且可以根据自己的需求传入不同的参数,形成不同内容的实例,比如我们可以通过传参指定实例名,启动基本weblogic镜像容器,在同一台机器上就可以基于同一个镜像启动很多个实例名不一样的进程。但这些参数不会改变原始代码,所有的变更都只存于容器内。所以说镜像是只读的,而容器是可写的。三个概念之间究竟是怎么相互存在,相互影响的呢?我们可以通过docker的生命周期来进一步了解。
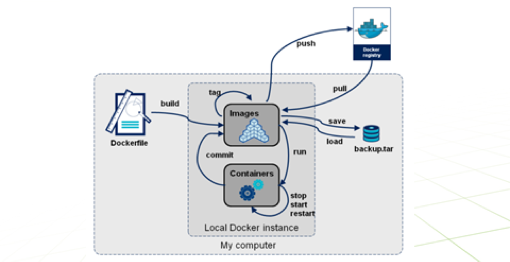
以镜像为基础,我们来看一下docker的生命周期。在我们的本地计算机上,我们可以从docker仓库把镜像下载下来,也可以把本地的镜像上传到docker仓库。可以为镜像的不同版本打上标签tag用来区别。
可以基于镜像创建一个容器,也可以把运行的容器commint成一个镜像,而容器则可以作为一个docker实例在本地运行,可以启动,停止,重启,当然也可以删除。我们还可以通过save把镜像保存到一个tar包,也可以通过load加载tar包里的镜像。我们还可以通过dockerfile来构建一个镜像。Docker的操作命令相对来说还是比较简单,如果发布一个镜像是就docker push 镜像名,加载tar包就是docker load 包名,运行容器docker start 容器名,掌握这个图上的命令基本就可以玩转Docker了。而在这个里面比较复杂的就是用dockerfile构建镜像了,在这个图里我们知道可以把一个运行的容器通过commit命令制作成一个新的镜像,相对比较简单,但是我们更建议使用dockerfile来构建镜像,为什么呢?下面简单介绍一下如何用dockerfile构建镜像。
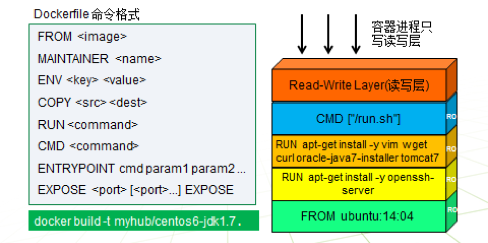
先我们看一下怎么用dockerfile构建docker镜像。只需要在当前目录下创建一个Dockerfile,记住Dockerfile的首字母D是大写,再使用使用命令build就可以创建新的镜像了。
简单讲解一下Dockerfile的命令格式
FROM <image> 设置基本的镜像,作为Dockerfile的第一条指令。比如右边一个图最底下,是基于ubuntu14.04版本创建的
RUN <command> 创建一层镜像,RUN命令的运行过程等于把一个运行的容器commit为镜像。比如右边第二层和第三层,创建了两层镜像,第二层的镜像是先基于第一层的镜像启动一个使用ubuntur操作系统的容器,然后在安装ssh服务,再用commit把第二层保存为一个镜像。而第三是基于第二层镜像启动一个容器,然后安装java,tomcat等服务,再用commit保存为第三层镜像。
MAINTAINER <name> 用来指定维护者的姓名和联系方式
ENV <key> <value> 用于设置环境变量
CMD指令指定你制作出来的镜像在启动成容器时运行命令的默认的参数。一个Dockerfile里只能有一个CMD,如果有多个,只有最后一个生效。docker run命令如果指定了参数会把CMD里的参数覆盖
ENTRYPOINT cmd param1 param2 ... 也是设置在容器启动时执行命令
COPY复制本地主机的 <src> (为Dockerfile所在目录的相对路径)到容器中的 <dest> 。
EXPOSE <port> [<port>...] EXPOSE 命令可以设置一个端口在运行的镜像中暴露在外,这样容器外可以看到这个端口并与其通信。
前面我们说了,可以像玩乐高一样玩docker,因为每一层的镜像都是基本父镜像形成的,他并不关心父镜像具体是什么。我们可以一层一层的叠加镜像,也可以根据需要增加删除或修改每一层镜像,再使用docker build生成一个最终版本的镜像。所以强烈推荐在生产中使用dockerfile来构建镜像,一是可以通过dockerfile来“阅读”镜像,看一下镜像里都包含了什么内容,二是在升级等需要修改镜像的场景下,直接优化dockerfile的内容,重构新的镜像就可以了。
在使用镜像的时候为避免镜像间依赖过深,建议三层,分别是基础的操作系统镜像、中间件镜像和应用镜像,一个容器里只运行一个服务。环境干净,结构简单,启动快速。
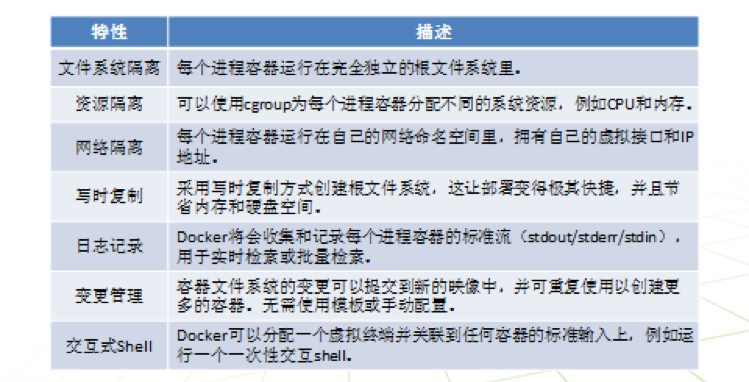
最后总结一下docker有哪些主要的特性:
正文到此结束
- 本文标签: 服务器 sql 大数据 App 操作系统 http 云 Nginx ip 安全 redis 空间 参数 颠覆 虚拟化 root tomcat centos 数据 时间 软件 主机 Go语言 mysql web db cat 调试 需求 value src 下载 linux ssh 端口 产品 开发者 代码 key build ACE wordpress java cmd 压力 UI IaaS Docker 开源 Word Ubuntu tab 进程 配置 API 实例 总结 生命 目录 测试 tar 安装 管理 MongoDB 开发 删除
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

