基于 Tesseract 的图文识别搜索引擎
【OCR/机器学习/搜索引擎】基于 Tesseract的图文识别搜
一、前言:
这是一篇图像识别OCR技术、机器学习、以及简易搜索引擎构建相关的技术Blog,是自己在做毕设的同时,每天不断记录研究成果和心得的地方。
二、选题背景
OCR(Optical Character Recognition 光学字符识别)技术,是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。 数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。 Tesseract目前已作为开源项目发布在Google Project,其最新版本3.0已经支持中文OCR。
在这样成熟的技术背景下,我很想利用这项OCR技术,再结合当下热门的移动互联网的开发技术和信息检索技术,实现一个能将图片中文字成功识别的移动Web搜索引擎,旨在为更多朋友能更加快捷、准确地从图片中获取想要的信息。
三、需求分析
随着互联网的快速发展,大数据的到来,人们对数据和信息依赖程度越来越大。然而,如今的互联网数据十分庞大,数据的准确性,和数据的合理分类一直存在着很大的问题,针对如此现状,越来越多的人们期望在日常工作、生活中能找到更加便捷获取准确数据的方式,能更加具有效率地找到自己所求信息的方式。同时,如今随着智能手机的普及,越来越多的人们更习惯于用拍照这样一种效率极高的方式,代替以前的抄写,打字方式,去记录生活、工作上需要记录的数据。 由此启发,想利用当下比较成熟的OCR(光学字符识别)技术,以及结合当下热门的互联网的开发技术和信息检索技术,实现一个能将图片语言字体成功识别的Web搜索引擎,旨在为更多朋友能通过拍照、截图这样便捷的方式,更加快捷、准确地从图片中搜索、获取到想要的信息。
四、用例设计
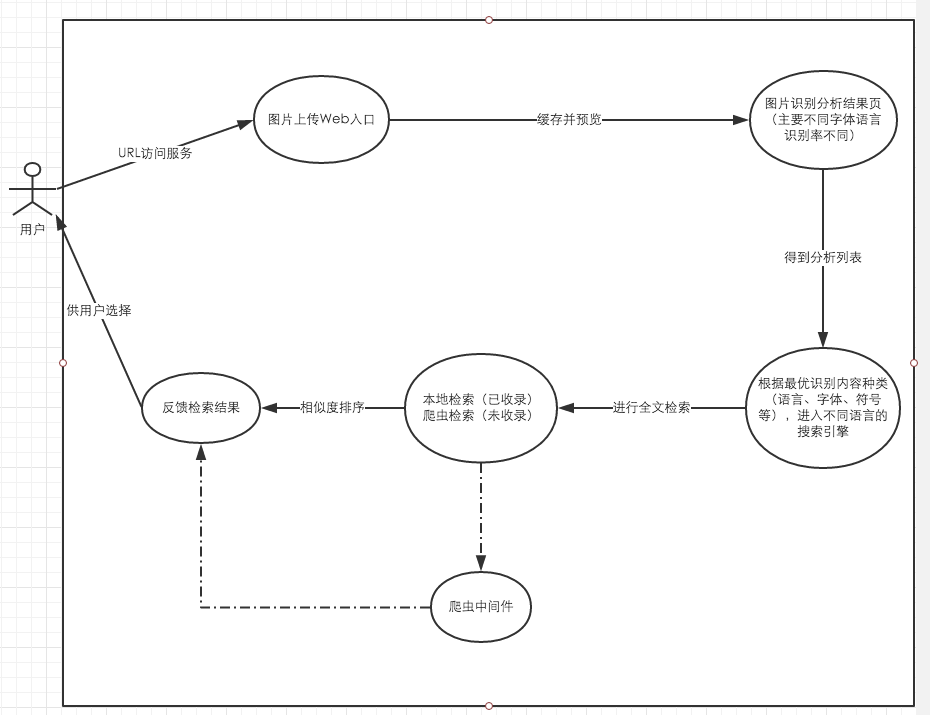
五、应用领域
- 海报信息云检索
- 广告图信息云检索
- 云翻译
- 名片云检索
六、架构设计

七、技术点分析
八、工程实现
后端工程实现
简介
后端的架构,主要分为三大模块:OCR模块、搜索引擎模块、PHP消息中间件模块。
- OCR模块:
- Tesseract在Mac下的搭建部署
- 字体语言样本数据训练
- 搜索引擎模块:
- Nutch模块部署配置
- Solr模块部署配置
- PHP消息中间件模块:又分为三大消息模块
- Tesseract-OCR-PHP中间件
- PHP图片传输中间件
- PHP云检索中间件
开源库
- 使用 Composer 依赖;
- Silex framework ;
- thiagoalessio ;
- Nutch1.10+Solr4.10.4 ;
第一个模块:OCR模块
Tesseract在Mac下的搭建部署
1.先翻墙
2.打开Mac OS的终端,键入
``` shell brew install tesseract ```
3.如果未同意Xcode协议许可,需要先键入协议许可,同意。
```shell sudo xcodebuild -license ... agree ```
4.继续使用Homebrew安装
``` shell brew install tesseract ```
5.安装成功后,进行测试,看Tesseract能否在Mac OS上正常运行,如下图所示。

6.这里解释下Tesseract终端下的用法:
```shell Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...] pagesegmode values are: 0 = Orientation and script detection (OSD) only. 1 = Automatic page segmentation with OSD. 2 = Automatic page segmentation, but no OSD, or OCR 3 = Fully automatic page segmentation, but no OSD. (Default) 4 = Assume a single column of text of variable sizes. 5 = Assume a single uniform block of vertically aligned text. 6 = Assume a single uniform block of text. 7 = Treat the image as a single text line. 8 = Treat the image as a single word. 9 = Treat the image as a single word in a circle. 10 = Treat the image as a single character. -l lang and/or -psm pagesegmode must occur before anyconfigfile. ```
-
其中:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
表示
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件。 -
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch-
-l chi_sim表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为.raineddata简体中文字库文件名为:chi_sim.traineddata)。 -
-psm 7表示告诉tesseractcode.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为3。 - configfile 参数值为tessdata/configs 和 tessdata/tessconfigs 目录下的文件名。
-
7.现在我们来使用测试一下,如下图
英文字体测试: 
中文字体测试: 
字体语言样本数据训练
现在我们来建立字体语言库以及字体语言样本数据的训练
字体库建立的官方原版说明:
**font_properties (new in 3.01)** A new requirement for training in 3.01 is a font_properties file. The purpose of this file is to provide font style information that will appear in the output when the font is recognized. The font_properties file is a text file specified by the -F filename option to mftraining. Each line of the font_properties file is formatted as follows: <fontname> <italic> <bold> <fixed> <serif> <fraktur> where <fontname> is a string naming the font (no spaces allowed!), and <italic>, <bold>, <fixed>, <serif> and <fraktur> are all simple 0 or 1 flags indicating whether the font has the named property. When running mftraining, each .tr filename must match an entry in the font_properties file, or mftraining will abort. At some point, possibly before the release of 3.01, this matching requirement is likely to shift to the font name in the .tr file itself. The name of the .tr file may be either fontname.tr or [lang].[fontname].exp[num].tr. **Example:** font_properties file: timesitalic 1 0 0 1 0 shapeclustering -F font_properties -U unicharset eng.timesitalic.exp0.tr mftraining -F font_properties -U unicharset -O eng.unicharset eng.timesitalic.exp0.tr Note that in 3.03, there is a default font_properties file, that covers 3000 fonts (not necessarily accurately) in training/langdata/font_properties. **Clustering** When the character features of all the training pages have been extracted, we need to cluster them to create the prototypes. The character shape features can be clustered using the shapeclustering, mftraining and cntraining programs: **shapeclustering (new in 3.02)** shapeclustering should not be used except for the Indic languages. shapeclustering -F font_properties -U unicharset lang.fontname.exp0.tr lang.fontname.exp1.tr ... shapeclustering creates a master shape table by shape clustering and writes it to a file named shapetable. **mftraining** mftraining -F font_properties -U unicharset -O lang.unicharset lang.fontname.exp0.tr lang.fontname.exp1.tr ... The -U file is the unicharset generated by unicharset_extractor above, and lang.unicharset is the output unicharset that will be given to combine_tessdata. mftraining will output two other data files: inttemp (the shape prototypes) and pffmtable (the number of expected features for each character). In versions 3.00/3.01, a third file called Microfeat is also written by this program, but it is not used. Later versions don't produce this file. NOTE: mftraining will produce a shapetable file if you didn't run shapeclustering. You must include this shapetable in your traineddata file, whether or not shapeclustering was used. **cntraining** cntraining lang.fontname.exp0.tr lang.fontname.exp1.tr ... This will output the normproto data file (the character normalization sensitivity prototypes).
如何进行机器学习,训练自定义新数据:
-
官方wiki
-
中文指导
实践过程:
- 首先可以从Tesseract官方Github上下载官方的语言包进行参考:传送门
第二个模块:搜索引擎模块
Nutch模块部署配置
安装配置开发包
Mac下,用Spotlight开启Terminal
JDK安装部署
- 介绍:这个就不解释了。
- 版本选用:1.8.0_77
- 下载地址: JD下载官网
- 启动安装:我记得Mac版的java安装包有dmg,直接双击安装,图形界面操作即可。
vi /etc/profile
这时按下键盘上字母i进入编辑模式,在终端下方输入以下两行命令:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin
然后按esc结束编辑,再输入:wq!退出
source /etc/profile java -version
出现 java版本信息 则证明安装成功!
Ant安装部署
-
介绍:当一个代码项目大了以后,每次重新编译,打包,测试等都会变得非常复杂而且重复,因此c语言中有make脚本来帮助这些工作的批量完成。在Java 中应用是平台无关性的,当然不会用平台相关的make脚本来完成这些批处理任务了,ANT本身就是这样一个流程脚本引擎,用于自动化调用程序完成项目的编译,打包,测试等。除了基于JAVA是平台无关的外,脚本的格式是基于XML的,比make脚本来说还要好维护一些。
-
版本选用:apache-ant-1.9.6-bin.zip
- 下载地址: Ant官网
- 启动安装:
sudo sh cd /usr/local/ chown YourUserName:staff apache-ant-1.9.6 ln -s apache-ant-1.9.6 ant vi /etc/profile
这时按下键盘上字母i进入编辑模式,在终端下方输入以下两行命令:
export ANT_HOME=/usr/local/ant export PATH=${PATH}:${ANT_HOME}/bin 然后按esc结束编辑,再输入:wq!退出
source /etc/profile ant -version
出现 Apache Ant(TM) version 1.9.6 compiled on ... 这个显示则证明安装成功!
Nutch安装部署
-
介绍:目前Nutch分为两个大版本1.x和2.x,Apache分别对这两个大版本进行独立开发和维护。其中,1.x和2.x最大的不同点在于,1.x是基于hadoop的HDFS文件系统的,而2.x将数据的存储层抽象出来,可以将数据保存在Hbase、MySQL等数据库中。还有一点很重要,Nutch在1.2以及之前,都是作为一个完整的搜索引擎进行发布的,而从1.3开始,Nutch本身就主要只有爬虫功能,若需要对抓取的数据建立索引并进行搜索,还要用到Solr全文检索服务器。由于Nutch和Solr都是基于Lucene开发的,因此Nutch抓取的数据可以轻松地在Solr中建立索引。Nutch官网可以下载到编译好的1.x包,但2.x只提供源码,需要自己编译。Nutch使用Ant来构建的,若自己编译的话,需要安装Ant来编译源码。对于如何选择Nutch的版本,主要考虑一下以下问题:如果只需要抓取少量的网站,并对其建立索引,使用1.x和2.x都可以,甚至都可以使用单机的,而不需分布式。但如果要抓取大量网站,甚至是全网爬行,那么最好选择1.x,并且采用分布式,因为1.x是基于hadoop文件系统的,而hadoop又是专门为处理大数据而生。若抓取大量网站时采用2.x,可能会遇到一些性能问题,要是使用MySQL来存储数据,网页数据上百亿时,性能将是一个噩梦。Nutch1.x不同的版本变化也比较大,执行命令发生过较大改变,因此,建议初学者下载本教程对应的版本1.10,等到熟悉使用Nutch的时候,那些改变对你而言就没太大影响了。Nutch作为当今最流行的开源爬虫之一,已被企业广泛使用。Nutch的插件机制使得开发者可以灵活地定制网页抓取策略。Nutch有着悠久的历史,当今大名鼎鼎的Hadoop就是由Nutch发展而来。Nutch不仅可以运行在单机模式下,还可以运行在分布式模式下。Nutch仅支持在Linux环境下工作,因此,在类Linux的OS X下可以直接使用。
-
版本选用:apache-nutch-1.10-src.zip
- 下载地址: Nutch官网
- 启动安装:
unzip apache-nutch-1.10-src.zip cd apache-nutch-1.10 vi conf/nutch-default.xml
找到http.agent.name这个属性,将其拷贝到conf/nutch-site.xml中,并修改value值不能为空,这里自定义为为: HD nutch agent,不然后续抓取命令会报错,修改后的nutch-site.xml如下:
<configuration> <property> <name>http.agent.name</name> <value>myNutch</value> <description>HTTP 'User-Agent' request header. MUST NOT be empty - please set this to a single word uniquely related to your organization. NOTE: You should also check other related properties: http.robots.agents http.agent.description http.agent.url http.agent.email http.agent.version and set their values appropriately. </description> </property> </configuration>
http.agent.name 这个属性是用于标记爬虫的,便于被爬的网站对其进行识别。
nutch-site.xml 中配置的属性会覆盖 nutch-default 中的默认属性,在这里我们仅修改 http.agent.name 这个属性,其它的不作改变。
到此,我们就配置好Nutch了,接着,在Nutch的主目录使用以下命令对源码进行编译。
启动服务
Ant 编译 Nutch源码
切换到Nutch主目录下执行:
ant
首次编译过程会耗费较多时间,因为需要下载较多的依赖包,具体时间根据实际网络情况而定,快的话需要5-10分钟,慢的话需要20分钟以上。
编译开始时会报如下警告:
Could not load definitions from resource org/sonar/ant/antlib.xml. It could not be found.
这个警告不影响编译结果,因此可以忽略。
编译过程中也有可能因为网络问题而出现编译失败,只需要使用如下命令清除上次编译结果(不会删除已经下载好的依赖包):
ant clean
在网络较差的情况下,可能会重复上面两步操作多次。
当出现如下类似信息时,也就意味着编译成功了:
BUILD SUCCESSFUL
Total time: 1 minute 7 seconds
如下图所示:

Nutch编译成功之后,会在主目录下生成一个runtime文件夹。其中包含deploy和local两个子文件夹。deploy用于分布式抓取,而local用于本地单机抓取。本节内容先讲解使用本地单机抓取,分布式抓取放到后续教程。
进入local文件夹,再进入bin文件夹。这里包含两个脚本文件,一个是nutch,另一个是crawl。其中,nutch包含了所需的全部命令,而crawl主要用于一站式抓取。
如下图所示: 
Solr模块部署配置
- 介绍: Solr 是一款优秀的基于Lucene的全文检索服务器,它对 Lucene 进行了扩展,提供了非常丰富的查询语言,并对查询进行了性能优化。
- 版本选用:solr-4.10.4.zip
- 下载地址: Solr官网
- 启动安装:
unzip solr-4.10.4.zip
得到文件夹solr-4.10.4,将Nutch目录下的runtime/local/conf/schema-solr4.xml拷贝到solr的配置文件目录example/solr/collection1/conf下:
cp apache-nutch-1.10/runtime/local/conf/schema-solr4.xml solr-4.10.4/example/solr/collection1/conf
删除solr原schema.xml文件:
rm –f solr-4.10.4/example/solr/collection1/conf/schema.xml
并注释掉schema-solr4.xml中的
<copyField source="latLon" dest="location"/>
将schema-solr4.xml改名为schema.xml:
mv solr-4.10.4/example/solr/collection1/conf/ schema-solr4.xml solr-4.10.4/example/solr/collection1/conf/ schema.xml
到此,Solr就配置完毕了,进入solr-4.10.4/example目录:
cd solr-4.10.4/example
启动Solr:
```java –jar start.jar
此时就可以通过浏览器访问8983端口,查看Solr的控制界面: http://localhost:8983/solr #### 利用Nutch爬虫进行数据抓取、Solr进行数据检索 ##### 一站式抓取 进入Nutch的主目录,今后我们大部分执行命令的操作都是在Nutch主目录完成的,而不是在Nutch的bin目录里,因为这样可以更方便地执行一些复杂的命令。查看一站式抓取命令:
bin/crawl bin/nutch
输入以上两个命令显示了它们各自的使用方法,后面会详细讲解一部分常用的命令,如下图所示:  查看crawl的使用方法: >-i|index用于告知nutch将抓取的结果添加到配置的索引器中。 >-D用于配置传递给Nutch调用的参数,我们可以将索引器配置到这里。 >Seed Dir种子文件目录,用于存放种子URL,即爬虫初始抓取的URL。 >Crawl Dir抓取数据的存放路径。 >Num Rounds循环抓取次数。 使用示例: >进入Nutch的runtime/local目录,新建一个urls文件夹: >在urls文件夹中新建一个存放url的种子文件,seed.txt >向urls/seed.txt添加初始抓取的URL:http://www.163.com >开启Solr服务,否则不能正常在Solr中建立索引
bin/crawl -i -D solr.server.url=http://localhost:8983/solr/ urls/ TestCrawl/ 2
>这条命令中,-i告知爬虫将抓取的内容添加到给定的索引中,solr.server.url=http://localhost:8983/solr/是Solr索引器的地址,urls/为种子URL文件路径,TestCrawl为Nutch用于存储抓取数据的文件夹(包含URL、抓取的内容等数据),这里的参数2表示循环抓取两次。 >通过执行上面一条命令,就可以开始抓取网页了。在浏览器中输入http://<host>:8983/solr,选择collection1,就可以在里面通过关键字搜索到已经建立索引的内容。这里需要注意的是,爬虫并没有将指定URL的全部页面抓取下来,查看抓取情况的具体方法请参考下面的分布式抓取。 抓取成功后如下图所示:  ##### 分布式抓取 有的时候,一站式抓取并不能很好的满足我们的需求,因此,这里给大家介绍一下分布式抓取的方法:分布式抓取的实际抓取过程包含多个命令的,为了简化操作,crawl把多个命令组合到一起提供给用户使用的。如果要深入学习Nutch爬虫技术,仅仅会使用crawl命令是不够的,还需要对抓取的过程非常熟悉,这里需要用到上一教程中seed.txt所保存的URL信息,还需删除data/crawldb,data/linkdb和data/segments文件夹下的内容,因为我们要分步重新抓取数据。 ###### Nutch数据文件夹组成 执行crawl命令之后,会在Nutch的runtime/local下面生成一个TestCrawl文件夹,里面包含三个文件夹:crawldb、linkdb和segments。 crawldb:它包含Nutch所发现的所有URL,它包含了URL是否被抓取、何时被抓取的信息。 linkdb:它包含了Nutch所发现的crawldb中的URL所对应的全部链接,以及源URL和锚文本。 segments:里面包含多个以时间命名的segment文件夹,每个segment就是一个抓取单元,包含一系列的URL,每个segment又包含如下文件夹: crawl_generate:待抓取的URL crawl_fetch:每个URL的抓取状态 content:从每个URL抓取到的原始内容 parse_text:从每个URL解析得到的文本 parse_data:从每个URL解析得到的外链和元数据 crawl_parse:包含外链URL,用来更新crawldb ###### 将URL列表注入到crawldb中
bin/nutch inject data/crawldb urls
###### 生成抓取列表 为了抓取指定URL的页面,我们需要先从数据库(crawldb)里生成一个抓取列表:
bin/nutch generate data/crawldb data/segments
generate命令执行之后,会生成一个待抓取页面的列表,抓取列表存放在一个新建的segment路径中。segment的文件夹根据创建的时间进行命名(本教程文件夹名为201507151245)。 generate还有很多可选参数,读者可以通过以下命令自行查看(其它命令的查看方法也一样):
bin/nutch generate `
启动抓取
根据generate生成的抓取列表抓取网页:
bin/nutch fetch data/segments/201507151245 #这里的201507151245为文件夹名,需要根据自己的情况进行更改,或者直接采用data/segments文件夹,这样的操作对segments文件夹下的所有子文件夹生效,后文同理。
解析
bin/nutch parse data/segments/201507151245
更新数据库
根据抓取的结果更新数据库:
bin/nutch updated data/crawldb –dir data/segments/201507151245
现在,数据库里包含所有初始页面更新后的入口,以及从初始集合中新发现的页面的新入口。
反转链接
在建立索引之前,我们首先对所有的链接进行反转,这样我们才可以对页面的来源锚文本进行索引。
bin/nutch invertlinks data/linkdb –dir data/segments/201507151245
将抓取到的数据加入Solr索引
启动Solr服务,现在,我们对抓取到的资源建立索引:
bin/nutch index data/crawldb -linkdb data/linkdb -params solr.server.url=http://localhost:8983/solr -dir data/segments/201507151245
去除重复URL
一旦建立了全文索引,它必须处理重复的URL,使得URL是唯一的:
bin/nutch dedup
这个命令基于签名查找重复的URL,对重复的URL标记为STATUS_DB_DUPLICATE,Cleaning和Indexing任务将会根据标记删除它们。
清理
bin/nutch clean –D solr.server.url=http://192.168.1.11:8983/solr data/crawldb
从solr移除HTTP301、404以及重复的文档。
到此为止,我们使用分步抓取的方式完成了所有抓取步骤,正常抓取的情况下,可以在http://localhost:8983/solr进行搜索了
抓取结果分析
readdb
用于读取或者导出Nutch的抓取数据库,通常用于查看数据库的状态信息,查看readdb的用法: ```bin/nutch readdb Usage: CrawlDbReader (-stats | -dump | -topN [] | -url ) directory name where crawldb is located -stats [-sort] print overall statistics to System.out [-sort]list status sorted by host -dump [-format normal|csv|crawldb]dump the whole db to a text file in [-format csv]dump in Csv format [-format normal]dump in standard format (default option) [-format crawldb]dump as CrawlDB [-regex ]filter records with expression [-retry ]minimum retry count [-status ]filter records by CrawlDatum status -url print information on to System.out -topN []dump top urls sorted by score to []skip records with scores below this value. This can significantly improve performance.
这里的crawldb即为保存URL信息的数据库,-stats表示查看统计状态信息,-dump表示导出统计信息,url表示查看指定URL的信息,查看数据库状态信息: ```bin/nutch readdb TestCrawl/crawldb -stats
得到的统计结果如下:
MacBook-Pro:local root# bin/nutch readdb TestCrawl/crawldb -stats CrawlDb statistics start: TestCrawl/crawldb Statistics for CrawlDb: TestCrawl/crawldb TOTAL urls: 290 retry 0: 290 min score: 0.0 avg score: 0.017355172 max score: 1.929 status 1 (db_unfetched): 270 status 2 (db_fetched): 17 status 3 (db_gone): 2 status 4 (db_redir_temp): 1 CrawlDb statistics: done
TOTAL urls表示URL总数,retry表示重试次数,mins score为最低分数,max score为最高分数,status 1 (db_unfetched)为未抓取的数目,status 2 (db_fetched)为已抓取的数目。
readlinkdb
readlinkdb用于导出全部URL和锚文本,查看用法:
```bin/nutch readlinkdb Usage: LinkDbReader (-dump [-regex ]) | -url -dump dump whole link db to a text file in -regex restrict to url's matching expression -url print information about to System.out
这里的dump和url参数与readdb命令同理,导出数据: `bin/nutch readlinkdb data/linkdb -dump linkdb_dump` 将数据导入到linkdb_dump这个文件夹中,查看导出的数据信息: `cat linkdb_dump /*` 可以看到,导出的信息类似以下格式: ```http://archive.apache.org/dist/nutch/ Inlinks: fromUrl: http://www.sanesee.com/article/step-by-step-nutch-introduction anchor: http://archive.apache.org/dist/nutch/
即记录了来源URL。
readseg
readseg用于查看或导出segment里面的数据,查看使用方法:
```bin/nutch readseg Usage: SegmentReader (-dump ... | -list ... | -get ...) [general options]
- General options: -nocontentignore content directory -nofetchignore crawl_fetch directory -nogenerateignore crawl_generate directory -noparseignore crawl_parse directory -noparsedataignore parse_data directory -noparsetextignore parse_text directory
- SegmentReader -dump [general options] Dumps content of a as a text file to . name of the segment directory. name of the (non-existent) output directory.
- SegmentReader -list ( ... | -dir ) [general options] List a synopsis of segments in specified directories, or all segments in a directory , and print it on System.out ...list of segment directories to process -dir directory that contains multiple segments
- SegmentReader -get [general options] Get a specified record from a segment, and print it on System.out. name of the segment directory. value of the key (url). Note: put double-quotes around strings with spaces.
导出segment数据: `bin/nutch readseg -dump data/segments/20150715124521 segment_dump` 将数据导入到segment_dump这个文件夹中,查看导出的数据信息: `cat segment_dump /*` 可以看到,里面包含非常具体的网页信息。 ### 第三个模块:PHP消息中间件模块 #### Tesseract-OCR-PHP中间件的实现 ##### 1. 配置PHP和服务器环境 可以使用WAMP/MAMP,也可以用PHPStorm和其内置服务器。 ##### 2.使用Composer进行PHP源工程的构建 具体操作可以参考:[传送门](http://daijiale.github.io/2016/03/08/%E3%80%90PHP%E3%80%91%20Composer%E5%85%A5%E9%97%A8%E5%AE%9E%E8%B7%B5/) 打开终端,切换到你的工程路径下: ```shell composer require silex/silex twig/twig thiagoalessio/tesseract_ocr:dev-master
因为使用了PHP的微型框架 Silex Framework ,我们需要自己建立PHP源工程项目MVC(public,uploads,views)结构,如图所示:
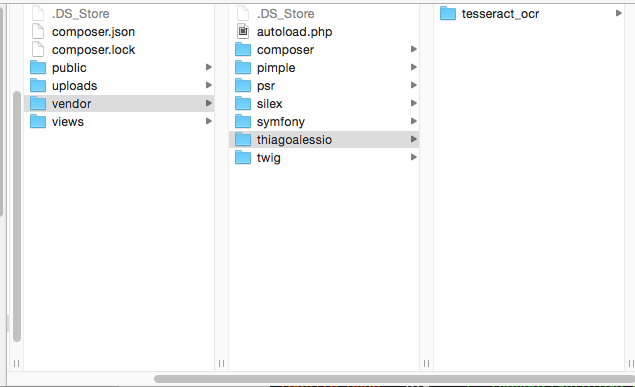
- public: 存放PHP脚本
- uploads: 存放用户上传图片
- vendor: 所有composer依赖包
- views: 前端代码
3.用Sliex库建立PHP消息中间件
启动初始化
- public/index.php
<?php //如果是在WAMP等其他集成环境下,需要重新获取环境变量的PATH,不然无法调用Tesseract $path = getenv('PATH'); putenv("PATH=$path:/usr/local/bin"); require __DIR__.'/../vendor/autoload.php'; use Symfony/Component/HttpFoundation/Request; $app = new Silex/Application(); $app->register(new Silex/Provider/TwigServiceProvider(), [ 'twig.path' => __DIR__.'/../views', ]); $app['debug'] = true; $app->get('/', function() use ($app) { return $app['twig']->render('index.twig'); }); $app->post('/', function(Request $request) use ($app) { //TODP }); $app->run();
文件上传并唯一标识存放
// Grab the uploaded file $file = $request->files->get('upload'); // Extract some information about the uploaded file $info = new SplFileInfo($file->getClientOriginalName()); // 产生随机文件名来减少文件名冲突 $filename = sprintf('%d.%s', time(), $info->getExtension()); // Copy the file $file->move(__DIR__.'/../uploads', $filename);
Tesseract-OCR接口类以及调用方法
Solr-PHP中间件的实现
前端工程实现、测试
交互设计
交互流程:
1)用户输入主页网站URL,进入首页,享受服务,了解服务详情。
2)用户通过搜索框,上传所需要的搜索图片,并进行上传前的预览。
3)用户确认上传的图片无误后,点击图搜按钮,进行图片上传和识别操作,因为这部分Server端计算量比较大,返回结果需要等待2-5秒钟,所以给用户呈现一个Loading页。
4)图像识别完成,Loading页消失,进入识别结果预览确认页面。
5)用户确认识别内容后,可以点击搜索,进入搜索引擎模块,获取检索结果。
视觉设计
视觉设计在产品组成中占了极为重要的成分,它直接影响了使用者对于该产品最初的观感、使用时的体验以及最后留下的印象等等。甚至在许多时候,产品的成败与否,往往就取决于成功的视觉设计经验上。 针对这个毕设,我并没有把它当成一个可以应付了事的系统,而是当成一个自己的产品去悉心创作,因此,我很注重这个系统的前端视觉设计,和用户体验。 全站选色,我选用了大众比较认可的百度搜索引擎主题色,红色和蓝色,首页背景采用红蓝过渡色,并调整了透明度,通过CSS代码画出,节约加载耗时的同时也给予用户一个良好的视觉冲击,同时对首页的文字说明,增加了底部阴影,并采用微软细黑字体,让视觉感觉更有层次感,图片搜索框以及预览框,也是加重了阴影,对预览字段的重要程度进行了不同的颜色和色度区分。让用户视觉上清爽,简洁,能最快找到自己视觉所需信息,之后会经过一个简单的loading页面,这里做了一个等待的圆圈渐变放大缩小动效,让用户对等待时间不感觉到烦躁,同时告诉用户,系统后台正在进行计算运行,当跳转到识别结果页面时候,依然按照文案重要程度,对所有文字颜色和字号进行了视觉调整,让用户不用花费太多时间,筛选重要信息,两个按钮的排班和选色也更倾向于增加点击欲望和点击感,提示用户可以进行下一步操作。最后的检索结果页面,我将它设计成了类似一本书目的篇章,每个列表根据搜索结果网页标题、网页摘要、收录时间、权重进行了不同的排班和字号颜色调整,增加视觉冲击感以及辨识度。让用户觉得和大众搜索引擎有一些共同点,但其中又透露出一些自己的个性,给用户熟悉又新奇的体验感,而且还保留了清爽无广告和多余干扰信息的特点。并且,所有视觉设计结合了当下的响应式设计理念,同时在PC端和移动端下都具有良好的用户体验和视觉效果。
模板编写
采用Twig进行模板编写:
- views
- index.twig
- search_results.twig
- results.twig
- css
- js
- fonts
- images
- favicon.ico
前端体验如下图所示: 
移动端工程实现、测试
主要基于Bootstrap3.4,可以用XDK/phoneGap打包编译成对应NA App,发布到应用市场。 移动端体验如下图所示:

心得体会
感谢大学四年所有的任课老师和所有帮助过我的同学们,是他们教会了我专业知识,通过近四年的学习和科研工作,不仅使我的知识结构和科研能力上了一个新的台阶,更重要的是让我融入了社会,给了我充分的实习经历,让我在大学本科就体验到了很多研究生都无法体验的互联网公司工作经历。弹指一挥间,大学四年已经接近了尾声。当自己怀着忐忑不安的心情完成这篇毕业论文的时候,自己也从当年一个懵懂孩子变成了一个成熟青年,还是那句话——只有汗水不会欺骗你,最后,感谢电子科技大学,感谢大学所遇见的每一个人,也感谢自己四年的努力。
项目开源地址:
https://github.com/daijiale/OCR_FontsSearchEngine .
项目视频演示地址:
http://v.youku.com/v_show/id_XMTYzNDY2NDYxNg==.html .
参考文献
- tesseract OCR训练新数据的详细步骤-附大量训练数据
- tesseract OCR的多语言,多字体字符识别
- Tesseract:安装与命令行使用
- Mac下使用Vagrant打造本地开发环境
- PHP OCR实战:用Tesseract从图像中读取文字
- Github—Tesseract-OCR
- Tesseract-OCR 字符识别---样本训练
- 开源图文识别引擎实现验证码识别
- Tesseract-OCR 3.02 训练笔记
- Tesseract 3 语言数据的训练方法
- Tesseract 3.02中文字库训练
- Mac下Tesseract安装部署
- 基于Tesseract-OCR的名片识别系统
- Github_Tesseract-OCR_For_PHP
- Nutch1.10入门教程
- Solr入门
- Solr官网
正文到此结束
- 本文标签: description 网站 UI 开源项目 注释 parse 软件 百度 rmi example 安装配置 统计 源码 Clustering shell 科技 cat 配置 微软 响应式 解析 插件 性能问题 目录 collection1 root schema.xml classpath 2015 mail tar 产品 安装 CSS 时间 HTML 文件上传 开发 云 schema PHP core 测试 下载 mina 文案 sql Bootstrap 需求 初学者 list 缩小 mysql solr web src 定制 ACE 自动化 互联网 HBase IDE 代码 App value 参数 linux 企业 apache lib 翻译 Nutch db ORM js 广告 HDFS 数据 GitHub 智能 key 入门教程 智能手机 zip dist 协议 Word 端口 Service https 美国 搜索引擎 开源软件 Google CTO XML 快的 provider update client 编译 删除 tab Property git 数据库 标题 开发者 大数据 色调 URLs REST 开源 java build 服务器 http Hadoop Features ip
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

