Deep dive into Linux network namespace
data structure
相同namespaces(所有的namespace都相同)中的所有进程共享同一个nsproxy,nsproxy包含所有具体的namespace的指针:
struct nsproxy { atomic_t count; struct uts_namespace *uts_ns; struct ipc_namespace *ipc_ns; struct mnt_namespace *mnt_ns; struct pid_namespace *pid_ns; struct net *net_ns; }; extern struct nsproxy init_nsproxy;
进程、nsproxy和单个namespace的关系如下:

nsproxy有一个引用计数,表明有多少个进程引用它;另外,每个namespace还有一个自己的引用计数(影响该计数的情况比较多,后面讨论net namespace的引用计数)。
每个网络设备、socket都有一个指向struct net的指针:
struct net_device { #ifdef CONFIG_NET_NS /* Network namespace this network device is inside */ struct net *nd_net; #endif ... } dev_net(const struct net_device *dev) to access the nd_net namespace of a network device. struct sock { #define sk_net __sk_common.skc_net Added sock_net() and sock_net_set() methods (get/set network namespace of a socket)
system call
有3个与namespace相关的 系统调用 :clone、 unshare 、 setns 。
也就是说进程有3种方式操作namespace:(1)创建进程时,同时创建新的namespace;(2)unshare将调用进程移到新的namespace;(3)setns将调用进程移到已经存在的namespace。
unshare
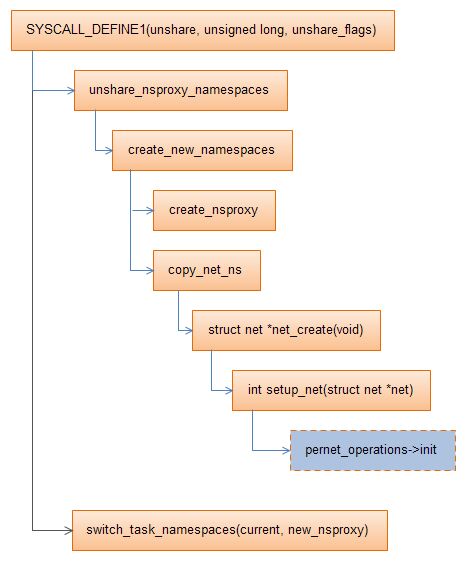
一般来说,unshare会创建新的namespace(比如net或者pid,或者两者),所以会调用create_new_namespaces创建一个新的nsproxy对象。然后创建新的namespace,将其引用计数置1。对于使用原来的namespace对象的情况,直接拷贝对应的namespace对象即可(即将具体的namespace的对象的引用计数加1)。
setns
- 实现

实现过程如下:
- (1) setns每个只会操作一个namespace对象,所以需要创建一个新的nsproxy对象,同时拷贝旧的所有namespace对象;
- (2) 修改nsproxy,指向目标namespace对象;
static int netns_install(struct nsproxy *nsproxy, void *ns) { struct net *net = ns; if (!ns_capable(net->user_ns, CAP_SYS_ADMIN) || !nsown_capable(CAP_SYS_ADMIN)) return -EPERM; put_net(nsproxy->net_ns); ///put old ns nsproxy->net_ns = get_net(net); ///get new ns return 0; }
-
(3) 进程指向新的nsproxy对象。
-
setns的应用
当我们执行 ip netns exec ... 时,就会 调用setns 加入到已有的net namespace:
int netns_switch(char *name) { char net_path[PATH_MAX]; int netns; snprintf(net_path, sizeof(net_path), "%s/%s", NETNS_RUN_DIR, name); netns = open(net_path, O_RDONLY | O_CLOEXEC); if (netns < 0) { fprintf(stderr, "Cannot open network namespace /"%s/": %s/n", name, strerror(errno)); return -1; } if (setns(netns, CLONE_NEWNET) < 0) { fprintf(stderr, "setting the network namespace /"%s/" failed: %s/n", name, strerror(errno)); close(netns); return -1; } close(netns); ...
clone
copy_process -> copy_namespaces
int copy_namespaces(unsigned long flags, struct task_struct *tsk) { struct nsproxy *old_ns = tsk->nsproxy; struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns); struct nsproxy *new_ns; int err = 0; if (!old_ns) return 0; get_nsproxy(old_ns); if (!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNET))) return 0; ... new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs); if (IS_ERR(new_ns)) { err = PTR_ERR(new_ns); goto out; } tsk->nsproxy = new_ns; out: put_nsproxy(old_ns); return err; }
copy_namespaces先对旧的nsproxy对象引用计数加1。如果clone需要创建新的namespace对象(比如指定了CLONE_NEWNS),则会创建新的nsproxy对象,进程会指向新的nsproxy对象(引用计数置),然后对旧的nsproxy的引用计数减1。
net namespace的引用计数
net namespace相对于其它namespace有一点特殊的地方,就是network可以独立于进程存在。也就是说,即使没有一个进程,net namespace也可以存在。比如,我们可以通过 ip netns add ... 创建一个net namespace。从net namespace的引用计数可以明白其原因。
struct net { atomic_t passive; /* To decided when the network * namespace should be freed. */ atomic_t count; /* To decided when the network * namespace should be shut down.
passive用于net的内存什么时候被释放(free),count用于有多个对象在使用该net对象。两个引用计数目的不一样,前者用于内存管理,后者用于net对象的使用引用情况。一般来说,后者为0,也应该将前者置0(clean_net)。这里重点关注count。
引用计数操作
static inline struct net *get_net(struct net *net) { atomic_inc(&net->count); return net; } static inline void put_net(struct net *net) { if (atomic_dec_and_test(&net->count)) __put_net(net); ///cleanup net namespace }
影响引用计数的条件
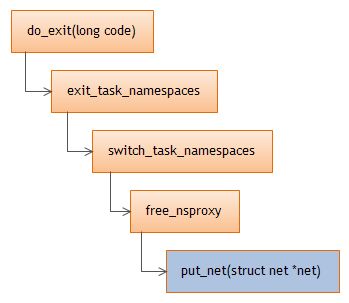
- (1)进程的创建与退出
从前面的讨论可以看到,创建进程时,会对nsproxy的引用计数加1;同理,当进程退出时,会对nsproxy的引用计数减1;当nsproxy引用计数变成0时,就会释放nsproxy,同时影响namespace的引用计数。
static inline void put_nsproxy(struct nsproxy *ns) { if (atomic_dec_and_test(&ns->count)) { free_nsproxy(ns); } } static inline void get_nsproxy(struct nsproxy *ns) { atomic_inc(&ns->count); }
- (2) socket的创建与释放
内核在创建socket的时候,会设置socket的net,同时也会增加net的引用计数:
struct sock *sk_alloc(struct net *net, int family, gfp_t priority, struct proto *prot) { struct sock *sk; sk = sk_prot_alloc(prot, priority | __GFP_ZERO, family); if (sk) { sk->sk_family = family; /* * See comment in struct sock definition to understand * why we need sk_prot_creator -acme */ sk->sk_prot = sk->sk_prot_creator = prot; sock_lock_init(sk); sock_net_set(sk, get_net(net)); ...
相应的,在释放socket时,减少net的引用计数:
static void __sk_free(struct sock *sk) { ... put_net(sock_net(sk)); ... }
iproute2
ip netns add
static int netns_add(int argc, char **argv) { ... /* Create the filesystem state */ fd = open(netns_path, O_RDONLY|O_CREAT|O_EXCL, 0); if (fd < 0) { fprintf(stderr, "Cannot create namespace file /"%s/": %s/n", netns_path, strerror(errno)); return -1; } close(fd); if (unshare(CLONE_NEWNET) < 0) { fprintf(stderr, "Failed to create a new network namespace /"%s/": %s/n", name, strerror(errno)); goto out_delete; } /* Bind the netns last so I can watch for it */ if (mount("/proc/self/ns/net", netns_path, "none", MS_BIND, NULL) < 0) { fprintf(stderr, "Bind /proc/self/ns/net -> %s failed: %s/n", netns_path, strerror(errno)); goto out_delete; } ...
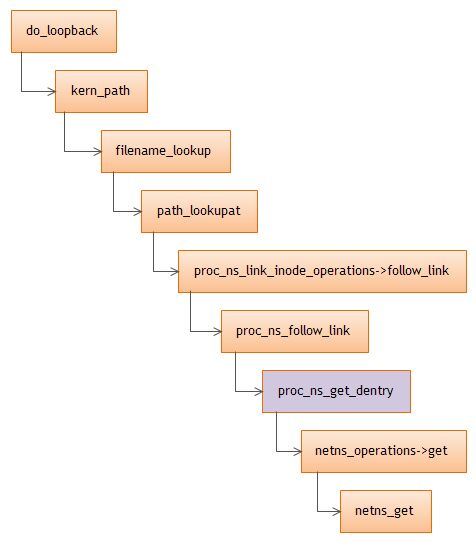
上面的bind mount能够保证当进程退出后,net namespace对象仍然存在。 /proc/self/ns/net 为proc_inode,mount的时候,会对进程的net对象的引用计数加1。
static struct dentry *proc_ns_get_dentry(struct super_block *sb, struct task_struct *task, const struct proc_ns_operations *ns_ops) { struct dentry *dentry, *result; struct inode *inode; struct proc_inode *ei; struct qstr qname = { .name = "", }; void *ns; ns = ns_ops->get(task); ///netns_operations->get if (!ns) return ERR_PTR(-ENOENT); ... ei = PROC_I(inode); if (inode->i_state & I_NEW) { inode->i_mtime = inode->i_atime = inode->i_ctime = CURRENT_TIME; inode->i_op = &ns_inode_operations; inode->i_mode = S_IFREG | S_IRUGO; inode->i_fop = &ns_file_operations; ei->ns.ns_ops = ns_ops; ei->ns.ns = ns; unlock_new_inode(inode); } else { ns_ops->put(ns); } ...
ip netns del
static int on_netns_del(char *nsname, void *arg) { char netns_path[PATH_MAX]; snprintf(netns_path, sizeof(netns_path), "%s/%s", NETNS_RUN_DIR, nsname); umount2(netns_path, MNT_DETACH); if (unlink(netns_path) < 0) { fprintf(stderr, "Cannot remove namespace file /"%s/": %s/n", netns_path, strerror(errno)); return -1; } return 0; }
In kernel:
# ./kprobe -s 'p:netns_put' netns_put Tracing kprobe netns_put. Ctrl-C to end. ip-10965 [014] d... 720230.717293: netns_put: (netns_put+0x0/0x30) ip-10965 [014] d... 720230.717296: <stack trace> => proc_evict_inode => evict => iput_final => iput => d_kill => dput => mntput_no_expire => SyS_umount => system_call_fastpath
- 网络设备的处理
当net namespace删除时,会将namespace中的网络设备返回给init net namespace。
Notice that after deleting a namespace, all its migratable network devices are moved to the </br> default network namespace; </br> unmoveable devices (devices who have NETIF_F_NETNS_LOCAL in their features) and virtual devices </br> are not moved to the default network namespace.
将网络设备移到init_net:
static void __net_exit default_device_exit(struct net *net) { struct net_device *dev, *aux; /* * Push all migratable network devices back to the * initial network namespace */ rtnl_lock(); for_each_netdev_safe(net, dev, aux) { int err; char fb_name[IFNAMSIZ]; /* Ignore unmoveable devices (i.e. loopback) */ if (dev->features & NETIF_F_NETNS_LOCAL) continue; /* Leave virtual devices for the generic cleanup */ if (dev->rtnl_link_ops) continue; ///将网络设备移到init_net /* Push remaining network devices to init_net */ snprintf(fb_name, IFNAMSIZ, "dev%d", dev->ifindex); err = dev_change_net_namespace(dev, &init_net, fb_name); if (err) { pr_emerg("%s: failed to move %s to init_net: %d/n", __func__, dev->name, err); BUG(); } } rtnl_unlock(); }
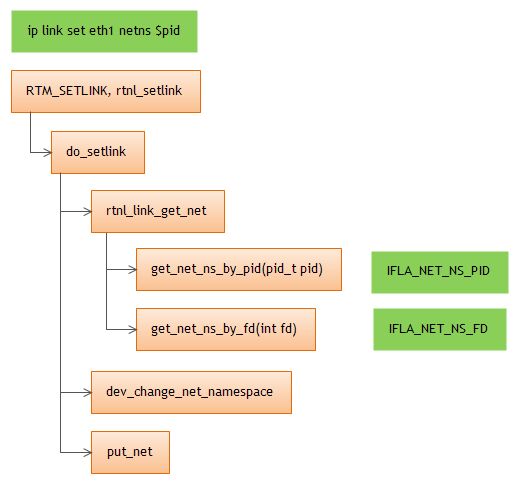
ip link set $DEV netns $PID
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

