使用Spark SQL构建交互式查询引擎
StreamingPro目前已经涵盖流式/批处理,以及交互查询三个领域,实现配置和SQL化
前言
StreamingPro 原来仅仅是用来作为Spark Streaming的一个配置化+SQL封装,然而不经意间,已经涵盖了批处理,交互式查询等多个方面。今天就讲讲如何使用StreamingPro构建一个交互式查询引擎。
准备工作
- 下载StreamingPro
1.5.1 链接: http://pan.baidu.com/s/1qYu2Fco 密码: efb9
1.6.1 链接: http://pan.baidu.com/s/1kVCTJE3 密码: rhss
我们假设您将文件放在了/tmp目录下。
启动StreamingPro
Local模式:
cd $SPARK_HOME ./bin/spark-submit --class streaming.core.StreamingApp / --master local[2] / --name sql-interactive / /tmp/streamingpro-0.2.1-SNAPSHOT-dev-1.6.1.jar / -streaming.name sql-interactive / -streaming.platform spark / -streaming.rest true / -streaming.driver.port 9004 / -streaming.spark.service true
访问
http://127.0.0.1:9004/sqlui
后可进入查询界面:
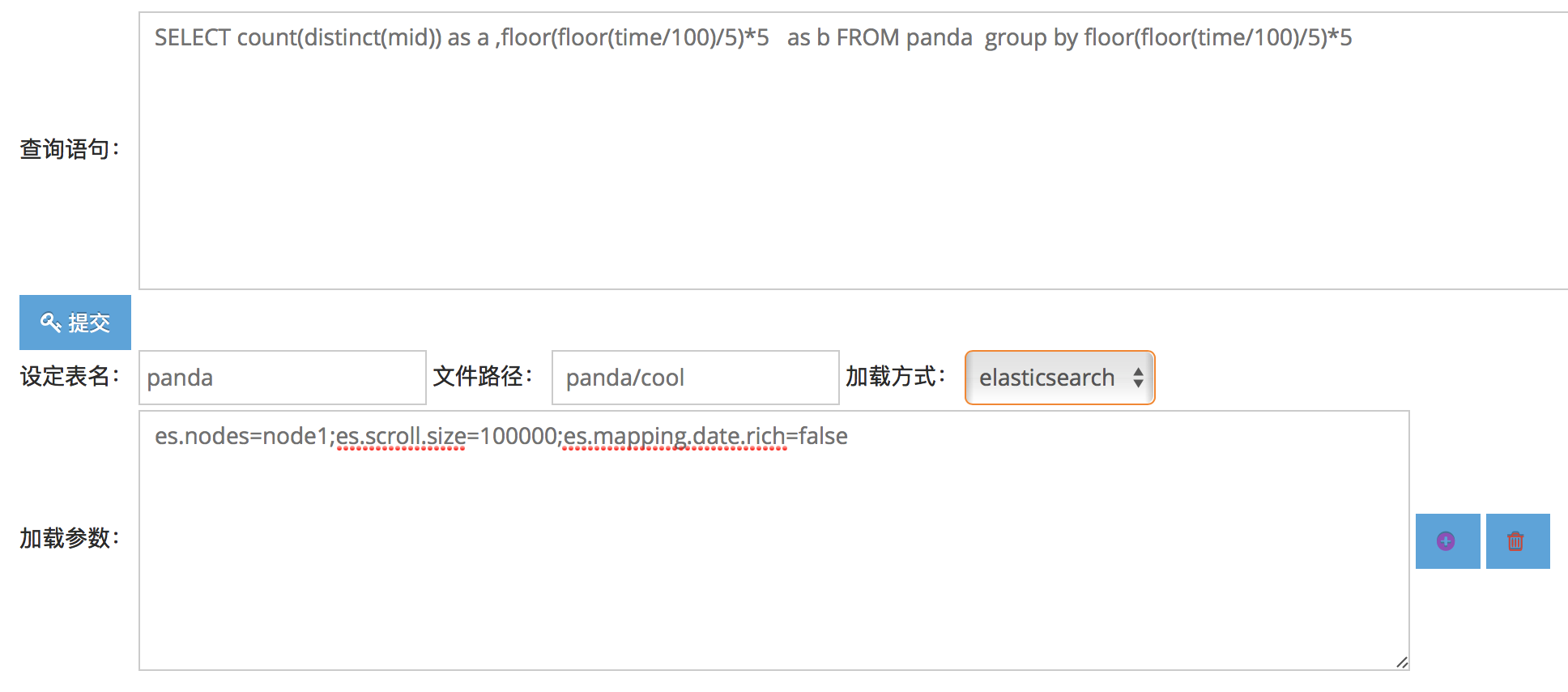
Snip20160709_5.png
目前支持elasticsearch 索引,HDFS Parquet 等的查询,并且支持多表查询。
除了交互式界面以外,也支持接口查询:
http://127.0.0.1:9004/runtime/spark/sql
参数支持:
| 参数名 | 示例 | 说明 |
|---|---|---|
| tableName.abc | hdfs://cluster/tmp/a.parquet | 索引或者parquet路径,其中abc是SQL中的表名称 |
| sql | SELECT count(distinct(mid)) as a ,floor(floor(time/100)/5) 5 as b FROM abc group by floor(floor(time/100)/5) 5 | 查询SQL |
| loaderclzz.abc | org.elasticsearch.spark.sql | 驱动类,如果是parquet文件则可简写为parquet |
| loaderclzz.abc | org.elasticsearch.spark.sql | 驱动类,如果是parquet文件则可简写为parquet |
| loaderparam.abc.es.nodes | node1 | 不同驱动可能会有自己一些特定的参数,比如es类的需要通过es.nodes传递ES集群在哪 |
上面的参数都是成套出现,你可以配置多套,从而映射多张表。
集群模式:
cd $SPARK_HOME ./bin/spark-submit --class streaming.core.StreamingApp / --master yarn-cluster / --name sql-interactive / /tmp/streamingpro-0.2.1-SNAPSHOT-dev-1.6.1.jar / -streaming.name sql-interactive / -streaming.platform spark / -streaming.rest true / -streaming.driver.port 9004 / -streaming.spark.service true
接着进入spark-ui界面获取driver的地址,就可以访问了。
服务发现
因为集群模式,driver的地址是变化的,所以一旦集群启动后我们需要注册到某个地方,从而能然前端知道。目前支持zookeeper的方式,在启动命令行中添加如下几个参数:
-streaming.zk.servers 127.0.0.1:2181 / -streaming.zk.conf_root_dir /streamingpro/jack
之后前端程序只要访问
/streamingpro/jack/address
就能获取IP和端口了。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

