HBase Compaction解析-基础篇
了解HBase的童鞋都知道,HBase是一种Log-Structured Merge Tree架构模式,用户数据写入先写WAL,再写缓存,满足一定条件后缓存数据会执行flush操作真正落盘,形成一个数据文件HFile。随着数据写入不断增多,flush次数也会不断增多,进而HFile数据文件就会越来越多。然而,太多数据文件会导致数据查询IO次数增多,因此HBase尝试着不断对这些文件进行合并,这个合并过程称为Compaction。
Compaction会从一个region的一个store中选择一些hfile文件进行合并。合并说来原理很简单,先从这些待合并的数据文件中读出KeyValues,再按照由小到大排列后写入一个新的文件中。之后,这个新生成的文件就会取代之前待合并的所有文件对外提供服务。HBase根据合并规模将Compaction分为了两类:MinorCompaction和MajorCompaction
- Minor Compaction是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile。
- Major Compaction是指将所有的StoreFile合并成一个StoreFile,这个过程还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。另外,一般情况下,Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。
Compaction作用 | 副作用
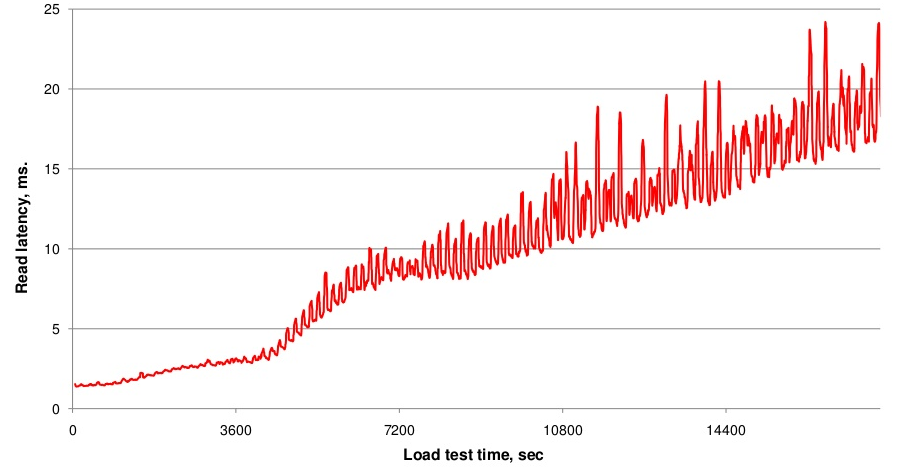
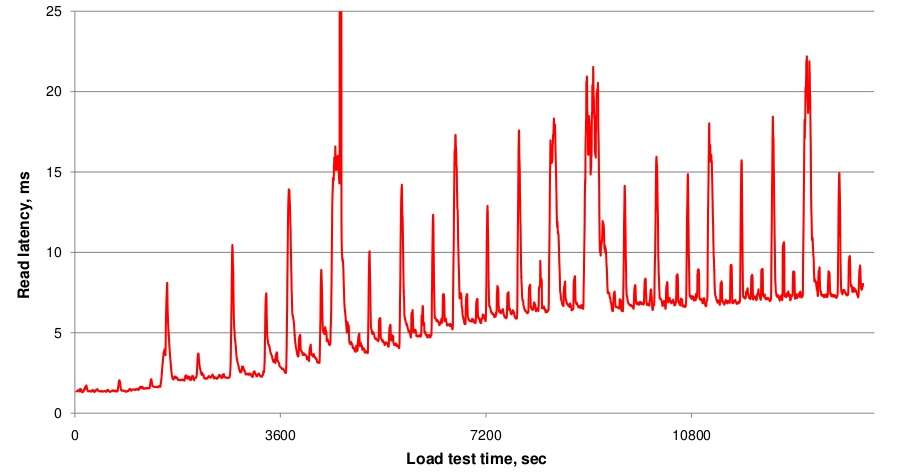
上文提到,随着hfile文件数不断增多,一次查询就可能会需要越来越多的IO操作,延迟必然会越来越大,如下图一所示,随着数据写入不断增加,文件数不断增多,读取延时也在不断变大。而执行compaction会使得文件数基本稳定,进而IO Seek次数会比较稳定,延迟就会稳定在一定范围。然而,compaction操作重写文件会带来很大的带宽压力以及短时间IO压力。因此可以认为,Compaction就是使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟。从图上来看,就是延迟有很大的毛刺,但总体趋势基本稳定不变,见下图二。
为了换取后续查询的低延迟,除了短时间的读放大之外,Compaction对写入也会有很大的影响。 我们首先假设一个现象:当写请求非常多,导致不断生成HFile,但compact的速度远远跟不上HFile生成的速度,这样就会使HFile的数量会越来越多,导致读性能急剧下降。为了避免这种情况,在HFile的数量过多的时候会限制写请求的速度:在每次执行MemStore flush的操作前,如果HStore的HFile数超过hbase.hstore.blockingStoreFiles (默认7),则会阻塞flush操作hbase.hstore.blockingWaitTime时间,在这段时间内,如果compact操作使得HStore文件数下降到回这个值,则停止阻塞。另外阻塞超过时间后,也会恢复执行flush操作。这样做就可以有效地控制大量写请求的速度,但同时这也是影响写请求速度的主要原因之一。
可见,Compaction会使得数据读取延迟一直比较平稳,但付出的代价是大量的读延迟毛刺和一定的写阻塞。
Compaction流程
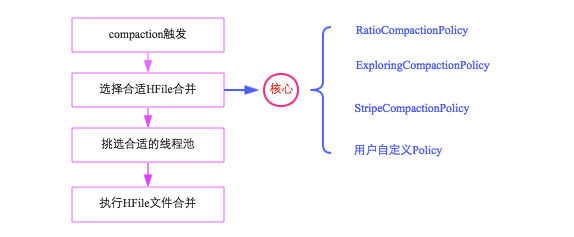
了解了一定的背景知识后,接下来需要从全局角度对Compaction进行了解。整个Compaction始于特定的触发条件,比如flush操作、周期性地Compaction检查操作等。一旦触发,HBase会将该Compaction交由一个独立的线程处理,该线程首先会从对应store中选择合适的hfile文件进行合并,这一步是整个Compaction的核心,选取文件需要遵循很多条件,比如文件数不能太多、不能太少、文件大小不能太大等等,最理想的情况是,选取那些承载IO负载重、文件小的文件集,实际实现中,HBase提供了多个文件选取算法:RatioBasedCompactionPolicy、ExploringCompactionPolicy和StripeCompactionPolicy等,用户也可以通过特定接口实现自己的Compaction算法;选出待合并的文件后,HBase会根据这些hfile文件总大小挑选对应的线程池处理,最后对这些文件执行具体的合并操作。可以通过下图简单地梳理上述流程:
触发时机
HBase中可以触发compaction的因素有很多,最常见的因素有这么三种:Memstore Flush、后台线程周期性检查、手动触发。
1. Memstore Flush: 应该说compaction操作的源头就来自flush操作,memstore flush会产生HFile文件,文件越来越多就需要compact。因此在每次执行完Flush操作之后,都会对当前Store中的文件数进行判断,一旦文件数# > ,就会触发compaction。需要说明的是,compaction都是以Store为单位进行的,而在Flush触发条件下,整个Region的所有Store都会执行compact,所以会在短时间内执行多次compaction。
2. 后台线程周期性检查: 后台线程CompactionChecker定期触发检查是否需要执行compaction,检查周期为:hbase.server.thread.wakefrequency*hbase.server.compactchecker.interval.multiplier。和flush不同的是,该线程优先检查文件数#是否大于,一旦大于就会触发compaction。如果不满足,它会接着检查是否满足major compaction条件,简单来说,如果当前store中hfile的最早更新时间早于某个值mcTime,就会触发major compaction,HBase预想通过这种机制定期删除过期数据。上文mcTime是一个浮动值,浮动区间默认为[7-7*0.2,7+7*0.2],其中7为hbase.hregion.majorcompaction,0.2为hbase.hregion.majorcompaction.jitter,可见默认在7天左右就会执行一次major compaction。用户如果想禁用major compaction,只需要将参数hbase.hregion.majorcompaction设为0
3. 手动触发:一般来讲,手动触发compaction通常是为了执行major compaction,原因有三,其一是因为很多业务担心自动major compaction影响读写性能,因此会选择低峰期手动触发;其二也有可能是用户在执行完alter操作之后希望立刻生效,执行手动触发major compaction;其三是HBase管理员发现硬盘容量不够的情况下手动触发major compaction删除大量过期数据;无论哪种触发动机,一旦手动触发,HBase会不做很多自动化检查,直接执行合并。
选择合适HFile合并
选择合适的文件进行合并是整个compaction的核心,因为合并文件的大小以及其当前承载的IO数直接决定了compaction的效果。最理想的情况是,这些文件承载了大量IO请求但是大小很小,这样compaction本身不会消耗太多IO,而且合并完成之后对读的性能会有显著提升。然而现实情况可能大部分都不会是这样,在0.96版本和0.98版本,分别提出了两种选择策略,在充分考虑整体情况的基础上选择最佳方案。无论哪种选择策略,都会首先对该Store中所有HFile进行一一排查,排除不满足条件的部分文件:
1. 排除当前正在执行compact的文件及其比这些文件更新的所有文件(SequenceId更大)
2. 排除某些过大的单个文件,如果文件大小大于hbase.hzstore.compaction.max.size( 默认Long最大值 ),则被排除,否则会产生大量IO消耗
经过排除的文件称为候选文件,HBase接下来会再判断是否满足major compaction条件,如果满足,就会选择全部文件进行合并。判断条件有下面三条,只要满足其中一条就会执行major compaction:
1. 用户强制执行major compaction
2. 长时间没有进行compact(CompactionChecker的判断条件2)且候选文件数小于hbase.hstore.compaction.max(默认10)
3. Store中含有Reference文件,Reference文件是split region产生的临时文件,只是简单的引用文件,一般必须在compact过程中删除
如果不满足major compaction条件,就必然为minor compaction,HBase主要有两种minor策略:RatioBasedCompactionPolicy和ExploringCompactionPolicy,下面分别进行介绍:
RatioBasedCompactionPolicy
从老到新逐一扫描所有候选文件,满足其中条件之一便停止扫描:
(1)当前文件大小 < 比它更新的所有文件大小总和 * ratio,其中ratio是一个可变的比例,在高峰期时ratio为1.2,非高峰期为5,也就是非高峰期允许compact更大的文件。那什么时候是高峰期,什么时候是非高峰期呢?用户可以配置参数hbase.offpeak.start.hour和hbase.offpeak.end.hour来设置高峰期
(2)当前所剩候选文件数 <= hbase.store.compaction.min(默认为3)
停止扫描后,待合并文件就选择出来了,即为当前扫描文件+比它更新的所有文件
ExploringCompactionPolicy
该策略思路基本和RatioBasedCompactionPolicy相同,不同的是,Ratio策略在找到一个合适的文件集合之后就停止扫描了,而Exploring策略会记录下所有合适的文件集合,并在这些文件集合中寻找最优解。最优解可以理解为:待合并文件数最多或者待合并文件数相同的情况下文件大小较小,这样有利于减少compaction带来的IO消耗。具体流程戳 这里
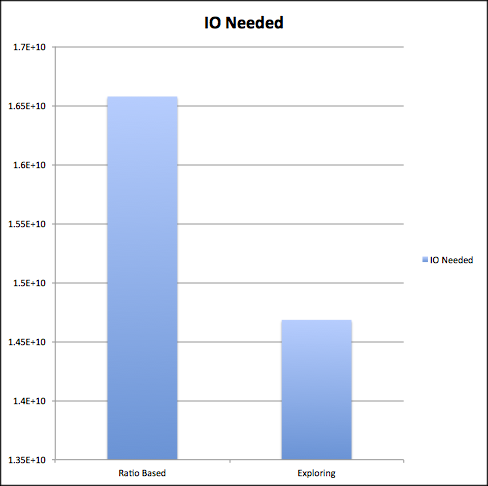
需要注意的是,Ratio策略是0.94版本的默认策略,而0.96版本之后默认策略就换为了Exploring策略,在cloudera博文 《what-are-hbase-compactions》 中,作者给出了一个两者的简单性能对比,基本可以看出后者在节省IO方面会有10%左右的提升:
截止到此,HBase基本上就选择出来了待合并的文件集合,后续通过挑选合适的处理线程,就会对这些文件进行真正的合并 。
挑选合适的线程池
HBase实现中有一个专门的线程CompactSplitThead负责接收compact请求以及split请求,而且为了能够独立处理这些请求,这个线程内部构造了多个线程池:largeCompactions、smallCompactions以及splits等,其中splits线程池负责处理所有的split请求,largeCompactions和smallCompaction负责处理所有的compaction请求,其中前者用来处理大规模compaction,后者处理小规模compaction。这里需要明白三点:
1. 上述设计目的是为了能够将请求独立处理,提供系统的处理性能。
2. 哪些compaction应该分配给largeCompactions处理,哪些应该分配给smallCompactions处理?是不是Major Compaction就应该交给largeCompactions线程池处理?不对。这里有个分配原则:待compact的文件总大小如果大于值throttlePoint(可以通过参数 hbase.hregion.majorcompaction配置, 默认为2.5G),分配给largeCompactions处理,否则分配给smallCompactions处理。
3. largeCompactions线程池和smallCompactions线程池默认都只有一个线程,用户可以通过参数 hbase.regionserver.thread.compaction.large和hbase.regionserver.thread.compaction.small进行配置
执行HFile文件合并
上文一方面选出了待合并的HFile集合,一方面也选出来了合适的处理线程,万事俱备,只欠最后真正的合并。合并流程说起来也简单,主要分为如下几步:
1. 分别读出待合并hfile文件的KV,并顺序写到位于./tmp目录下的临时文件中
2. 将临时文件移动到对应region的数据目录
3. 将compaction的输入文件路径和输出文件路径封装为KV写入WAL日志,并打上compaction标记,最后强制执行sync
4. 将对应region数据目录下的compaction输入文件全部删除
上述四个步骤看起来简单,但实际是很严谨的,具有很强的容错性和完美的幂等性:
1. 如果RS在步骤2之前发生异常,本次compaction会被认为失败,如果继续进行同样的compaction,上次异常对接下来的compaction不会有任何影响,也不会对读写有任何影响。唯一的影响就是多了一份多余的数据。
2. 如果RS在步骤2之后、步骤3之前发生异常,同样的,仅仅会多一份冗余数据。
3. 如果在步骤3之后、步骤4之前发生异常,RS在重新打开region之后首先会从WAL中看到标有compaction的日志,因为此时输入文件和输出文件已经持久化到HDFS,因此只需要根据WAL移除掉compaction输入文件即可
本文重点从减少IO的层面对Compaction进行了介绍,其实Compaction还是HBase删除过期数据的唯一手段。文章下半部分着眼于Compaction的整个流程,细化分阶段分别进行了梳理。通过本文的介绍,一方面希望读者对Compaction的左右有一个清晰的认识,另一方面能够从流程方面了解Compaction的工作原理。然而,Compaction一直是HBase整个架构体系中最重要的一环,对它的改造也从来没有停止过,改造的重点就是上文的核心点-’选择合适的HFile合并’,在接下来的一篇文章中会重点分析HBase在此处所作的努力~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

