个性化搜索技术与应用
一 什么是个性化搜索
个性化搜索简单点说,就是在搜索过程中融入个性化元素,具体过程是指在搜索引擎中,根据用户个性化特征,进行二次排序或融合相关物品的搜索过程;目的是抓住用户口味偏好,缩短用户筛选时间和消费路径。
一方面从用户角度来讲,每个人的喜好不一样,需要分析用户偏好。比如价格偏好、类目偏好、品质偏好等等;另一方面,从搜索的角度来讲,搜索系统有两件事情可以做:首先挖掘用户的个性化需求,明确消费指向;其次是对商品的特征抽取。这两件事情做好后,当客户搜索时,系统需要把符合他消费习惯的产品尽量往前排。
二 个性化搜索在淘宝中应用
淘宝上用户的注册信息,浏览行为,购买行为非常丰富,搜索的结果中加入了个性化的因素,不同的买家,由于以前的购买或者浏览行为不一样,看到的搜索结果也可能不一样。
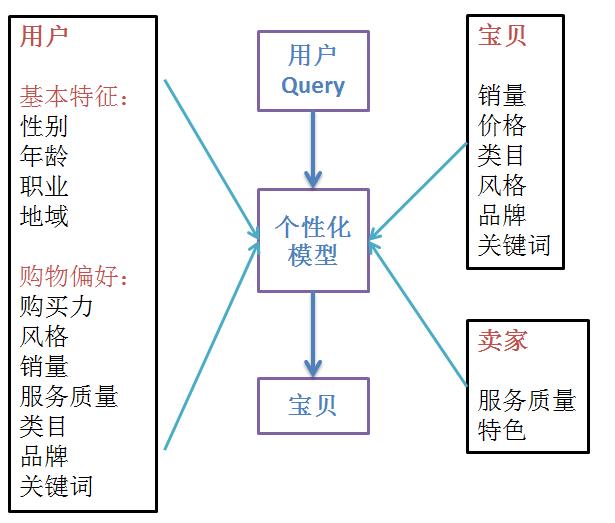
个性化模型根据用户的个性化偏好、物品特征以及卖家特征,做出二次排序模型,然后再展示给用户;搜索结果和营销资源等方面的充分应用,目标是让消费者看到和他最相关的商品展现,最终实现千人千面的淘宝。
比如下图中,搜索购买T恤时,对于中档购买力的用户,左图高中低价格都有,用户需要仔细再筛选辨认下,而右图主要是中等价位,而且拍在前面,用户很容易选择,这就是在价位上的个性化排序搜索。

三 构建个性化搜索系统
想要顺利地构建个性化搜索系统,需要先明晰系统的核心关键点,然后据此逐步进行用户和物品特征建模、建立个性化化模型、线上二次排序,最后把最终结果展示给用户。
1 个性化搜索系统的关键点
(1) 用户个性化特征:一方面是,用户的客观特征,比如性格,年龄;另一方面是,根据用户历史行为,比如浏览、购买等,抽象出来的用户偏好特征,比如风格偏好,价格偏好,品牌偏好。
(2) 物品特征:一方面是物品的客观特征,比如品牌,类目,关键词;另一方面是,物品的随行就市以及随之变化的特征,比如折扣,销量
(3) 二次排序:原始搜索结果特征与用户个性化特征匹配,对搜索结果重新打分、排序,然后,尽可能地展示出符合用户偏好的搜索结果。
(4) 融合:一种是,协同搜索;搜索凉鞋,如果用户刚买红色连衣裙,这种情况下推送买红色连衣裙的用户也买的凉鞋。另外一种是,在搜索结果中,展示不完全符合搜索意图,但是符合用户偏好特征,并与搜索意图相关的物品。
2 用户特征建模和物品特征建模
用户特征建模就是挖掘用户个性化特征的过程;根据用户的历史行为,分析用户的个性化偏好特征,比如上文提到的风格偏好,价格偏好,品牌偏好。
物品特征建模就是挖掘物品特征的过程。
3 建立个性化模型
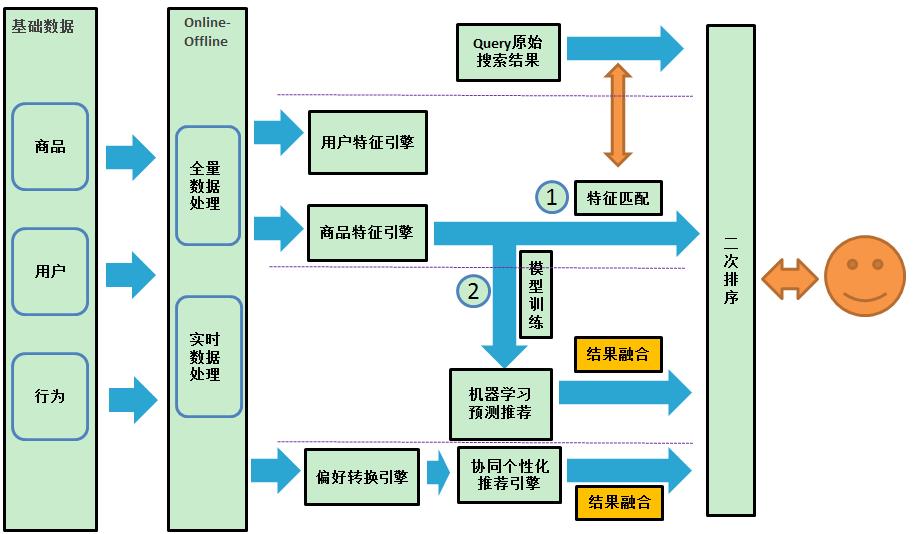
(1)特征匹配
特征匹配是最简单,易实现的个性化模型;特征匹配在原query搜索结果的基础上,用户个性化偏好特征,匹配(搜索结果中的)物品特征,然后进行加权排序。
(2)协同搜索
协调搜索是根据用户的购买,浏览等消费行为,利用经典的协同过滤算法,离线推荐用户可能喜欢的其他物品,简单的算法原理见下图:
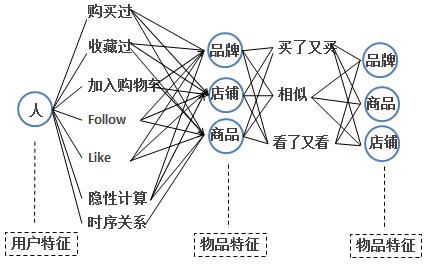
“买了又买”、“看了又看”是Itembased协同过滤算法最简白的描述(另外,还有Userbased协同过滤算法,原理类似),其算法核心是计算物品的的相似度,相似度算法有余弦相似度、Pearson相似度、Jaccard相似度等。
协同推荐的结果可以在搜索结果中融合展示,也可以对搜索出的结果匹配加权展示。
(3)模型训练
个性化模型训练是在原搜索点击率预估模型的基础上,加入用户特征,将模型目标,确定为搜索系统目标的二分类问题,通过对历史样本数据的训练学习,从而对新样本进行准确预测。
模型训练的结果可以是用户搜索转换的概率,也可以是特征匹配,协同搜索时的加权权重。
4 线上二次排序
线上二次排序是搜索结果展示给用户的最后一步,一般是在线上处理,需要实现的工作有:特征匹配加权重排序、协同推荐结果融合、协同推荐加权二次排序以及模型结果融合。
综上,个性化搜索系统的整体架构如下:
四 同城约会个性化搜索系统案例
同城约会是网易公司旗下婚恋交友网站,专为单身男女白领提供征婚交友服务平台。
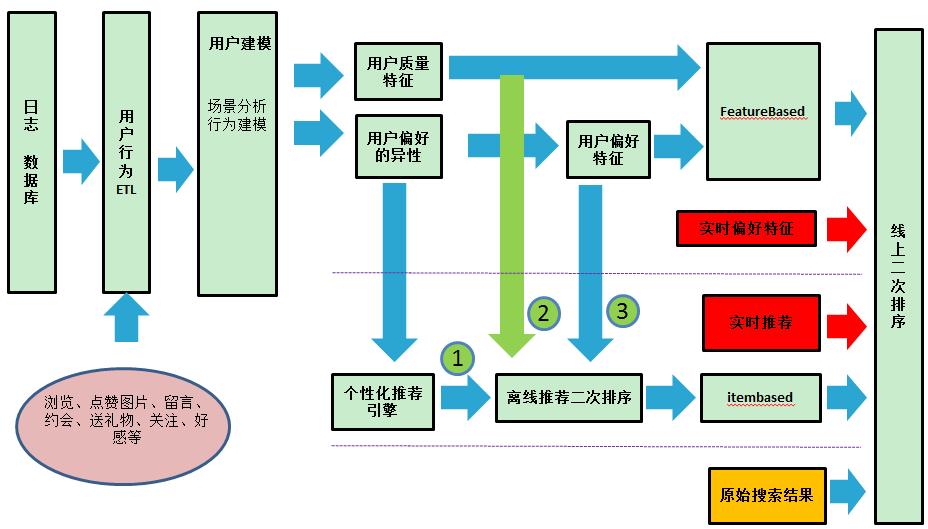
同城约会的个性化搜索系统在“找缘分”下的“搜索会员”界面,默认排序的方式就是个性化搜索的结果。同城约会的个性化搜索系统架构见下图:
1 数据源
系统的数据源为数据库mysql和客户端的行为action日志;数据库数据可以通过猛犸导出到hdfs,日志可以通过datastream分发到hdfs;之后的离线计算可以在hadoop集群上处理。
2 同城约会中的用户特征,同时也是物品特征
一方面,同城约会中,用户可以完善自己的个人资料(性别、年龄、身高、学历等)和择偶标准,构成用户自身的 客观属性特征 ;
另一方面,通过用户的浏览、点赞图片、留言、约会、送礼物、关注、好感等主动行为,可以分析用户的个性化 异性偏好口味特征 ,包括偏好的异性年龄、地域、风格、学历、职业、收入、房车、吸烟喝酒,婚姻状况情况等;
最后,可以根据用户的被动行为(即其他用户对该用户的浏览、点赞图片、送礼物等的主动行为),分析用户的受欢迎程度、外貌特征(图片点赞情况可以推测出)、亲和力等特征,从用户自己的消费行为可以分析用户的消费水平等,以上可以构成用户的 质量特征 。
3 同城约会线上特征匹配
当线上,用户发出搜索请求后,在原始搜索结果的基础上,获取请求用户的异性偏好特征和搜索结果中用户的客观属性特征和质量特征,经过线上二次排序后,再展示给用户,即图中的FeatureBased算法。
4 协同搜索
根据用户主动行为,可分析用户偏好的异性,之后利用协同过滤算法,计算出同性用户之间的相似度,进而可以为用户推荐出他/她可能喜欢的其他相似异性用户,由于直接相似关联的结果会有badcase,因此,离线计算时候会根据用户的偏好特征和被推荐用户的质量特征,作一次过滤和重排序;当线上,用户发出搜索请求后,在原始搜索结果的基础上,当存在用户的推荐结果时候,会作加权二次排序,即图中的Itembased算法。
5 线上实时系统
个性化搜索系统中的实时模块包括两部分:(1)用户实时推荐结果;当系统发现用户对某异性有偏好意图后,会实时为用户推荐可能喜欢的其他用户,进而迅速地融入Itembased算法中;(2)用户实时偏好特征;系统在线上追踪用户表现偏好的主动行为,不断调整当天用户实时的异性偏好特征,最终体现到FeatureBased算法二次排序中。实时模块可以迅速扑捉用户当前的口味偏好,能促进个性化搜索系统更灵敏、更智能化。
6 同城约会个性化搜索系统效果
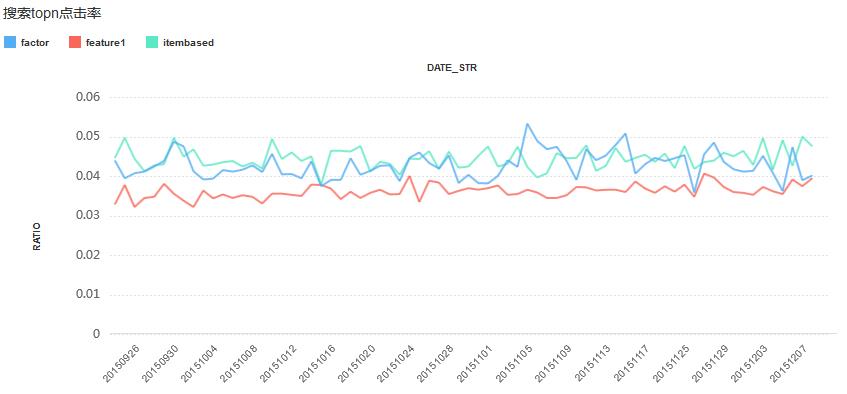
上图为,个性化搜索系统刚上线的一段时间内,搜索结果top10,用户点击率效果图。红线为非算法的原始搜索结果的点击率效果,平均在3.5%左右;蓝色为FeatureBased算法的点击率效果,平均在4.18%左右,提升19.4%;青色为Itembased算法的点击率效果,平均在4.44%左右,提升26.9%。
五个性化搜索系统的难点
1 特征建模
特征是个性化排序模型的基础;挖掘分析特征需要深入业务场景,不断调整完善,往往好的特征可以事半功倍。
2 二次排序特征权重
特征权重可以人工设置,也可以通过机器学习不断调整。一般刚开始数据两不足的时候,可以通过人工经验,手动设置;当积累到一定的数据量的时候,可以通过模型训练,优化特征权重。
3 系统的线上响应
个性化搜索系统会在线上做大量的二次排序工作,这对系统的响应性能造成很大的影响。一般,可以将用户特征、Itembased算法结果能放到线上缓存中,如nkv/ncr,以提升接口的响应性能。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

