Exadata火线救援:10TB级数据修复经典案例详解!
凌晨1点半,朦胧中电话铃狂响,某Exadata严重故障…….
离上一篇文章( 5小时数据蒸发||24小时服务降级,Salesforce的遭遇只是个案? )不远,我们又遇到了一次又一次数据救援工作。跟Salesforce巧合的是,大家都是运行在Exadata上,不幸的是Salesforce丢失了4个小时数据(后续没看到新闻稿,是否又追回了部分)业务停顿,那我今天遇到的要麻烦更多。
近期Exadata故障比较多,比较重要的是硬件生命周期所致,X2从2010年9月开始发布上线,到现在已经将近6年,就算传统“高端”小型机也到该下线的时候了。提醒使用Exadata的朋友们做好备份,否则,你可能也要经历一场难忘的救援经历。问题发生得很不可思议,又很理所当然,细节就不说了。总之比较糟糕:
存放数据文件的diskgroup不能加载(mount),celldisk状态是unknown,部分asmdisk的header是invalid的,就连它自动备份的块也是invalid的,有磁盘物理损坏,物理损坏的磁盘没有的mirror也失效了。接近10TB的数据,想想也头疼吧。再说具体数据抢救工作之前,还是提醒下使用ASM/Exadata的朋友们,至少搭建个DataGuard吧,刚好建荣也做了这方面的分享,赶紧去读读。
鉴于问题非常棘手,综合各方信息,我们做了如下的方案:
- 将 数据库 文件抽取出来
- 尝试open
- 如失败再DUL
要将数据库文件(控制文件、数据文件、 日志 文件)从没有加载的磁盘组中抽取出来,需要借助于AMDU。
AMDU: ORACLE针对ASM开发的源数据转储工具,其全称为ASM Metadata Dump Utility
抽取的具体步骤:
- 从alert日志中找到启动参数(包括控制文件),编辑成新的参数文件/tmp/pfile
- 从pfile中找到控制文件的位置,并用amdu抽取
- 用抽取出来的控制文件,将数据库mount起来
- 从mount库把所有数据文件找出来,可能有2种格式
- OMF格式(数据文件带Oracle自动生成的数字)
- 自定义格式(手贱的),处理起来麻烦一些
- 日志文件同上处理
抽取数据文件
第一步:抽控制文件
先从alert日志找到控制文件位置:
control_files string +DATA/exdb/controlfile/curren t.266.278946847955,
11g开始amdu不需要编译可以直接使用。到/data文件系统,开始操作
amdu -diskstring '/o/*/ *' -extract data.266
在当前目录下会生成一个DATA_266.f的文件和一个report.txt文件,DATA_266.f就是控制文件了。
第二步:找数据文件和日志文件
如果你有备份的pfile最好,如果没有,就从alert日志里去找启动的时候的初始化参数,实在没有,手工编辑一个也行,包含sga_max_size,db_name,control_file这几个参数。
然后把数据库启动到mount状态,查找数据文件和日志文件:
select name from v$datafile;
select member from v$logfile;
运气好,都是这样的(OMF格式):
+DATA/exdb/datafile/system.256.278946847955 +DATA/exdb/datafile/sysaux.257.278946847955 +DATA/exdb/datafile/undotbs1.258.39804295139 +DATA/exdb/datafile/users.259.48049295141
运气不好,可能是有这样的(自定义格式):
+DATA/exdb/datafile/users_2013084.dbf +DATA/exdb/datafile/tbs_jifen_cx_0123.dbf
对于OMF格式的,仿照抽取控制文件,一个个抽:
amdu -diskstring '/o/*/ *' -extract data.256
对于自定义格式的,要从<diskgroup>.6去抽取元数据,然后找到其对应的number
- amdu -extract DATA.6 -diskstring 'o/* /DATA ' ,生成DATA_6.f 文件
for (( i=1; i<15; i++ ))
do
kfed read DATA_6.f blknum=$i |egrep 'name|fnum'>>aa.out
done
再依照OMF格式抽取方式抽取出所有数据文件。
值得一说的是,我们遭遇了一个3T的bigfile,extract消耗了将近24小时= =。--NFS挂过去的文件系统速度特别慢= =
最后对所有的文件用dbv做一次校验,有没有物理坏块。
尝试Open数据库
当到了这一步的时候,其实就跟寻常的数据库恢复类似了。 我们同样在open的时候遇到了ORA-1555、ORA-704错误。
记录下我们用到的参数和事件。
event:

隐含参数:

这里比较讨厌的是rollback segments不容易确定,因为你是mounted状态的数据库,连v$rollname都查询不了。
有两个办法来解决:
办法一,用strings去system文件里抓。
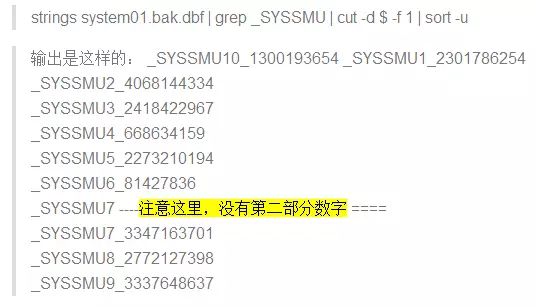
办法二,用DUL/AUL/ODU/GDUL等类似工具。相对来说这种方法得到的准确一些
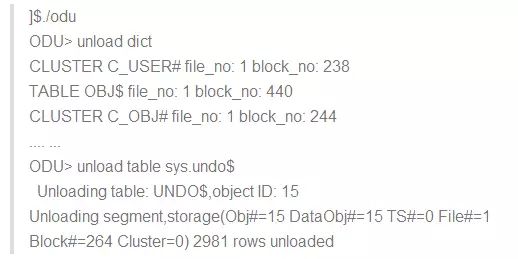
把得出的SYS_UNDO.dmp导入普通用户,去除status为1和2的回滚段(还原段)后放入到上述空着的2个参数。
open的时候可能还会报ORA-1555,需要推进SCN,以upgrade模式open。
推进SCN的方法很多网友也有分享过,度娘或者谷哥都可以。这里需要重点提示后续有需要的小伙伴的是,搞了两下没起来也别灰心。这次单就推进SCN这块,我们也折腾了好长时间,甚至一度两度打算放弃准备DUL了。
先看看oradebug poke的描述:

那首先是找到SCN的内存地址:

等号后面的值,就是当前显示的SCN了,不过,由于是mount状态,所以显示为0. 将当前的SCN(从v$datafile_header#查)随手加上100万,转为十六进制,推一把看看:

再次查看就能看到SCN的值了:

然后“alter database open uprade", 不断重复尝试.......
此外还用了bbed修改块,还去删除数据字典记录.......
终于,数据库总算open了,数据回来了。
关于更详细的细节,欢迎关注后续DBA+技术沙龙主题。
DUL和Ahttp://mp.weixin.qq.com/s?__biz=MzI4NTA1MDEwNg==&mid=2650756087&idx=2&sn=126b19493ff2a87130bc9c80c2dd8112&scene=21#wechat_redirectMDU
万幸的是,没有走到最后一步,没有用DUL来抽数据,不然,以这龟速,少说也是一个星期的事情。
DUL和AMDU都是救命的稻草,我们有能力使用,不代表我们一定要去用。而且我们从不在这个时候跟客户谈收费,作为服务商我们坚持救急如救火!而这些救命工具就如同山洞里的核武器,我们希望每个客户都能做好前期规划、维护、备份和容灾,让它们静静地躺着,作为一种威慑手段就好了。
关于exadata的维护
再好的东西,你不关心它,总会出问题的,Exadata也不例外。
摘抄《Exadata专家工具箱》里的几个工具,仅供参考:
sundiag

ExaWatcher

- Diskinfo
- IBCardino
- Iostat
- Netstat
- Ps
- Top
- Vmstat
Exachk

CheckHWnFWProfile

这些命令两周做一次检查还是必要的。
关于数据库运维管理工具
问题发生在别人身上的时候,我们听起来不可思议,觉得别人是不是傻啊,还是懒啊,其实不是,有的时候真是太忙太忙,忙不过来,这时候需要一套工具来帮助大家。
是的,说的就是你。还记得我们昨天的聊天么,你说,他们是不是傻啊,不做监控么,平时不去看么?我说,你要是管理几千个数据库,而你又没有合适的管理工具,一个边缘系统发生这种情况,是在所难免的。
那么什么样的数据库运维管理工具是合适的呢?
- 数据库多维度监控
- 日常运维场景化
- 数据库实时性能分析
- 应用性能追溯
这几个方面互为补充,逐渐让运维变得信手拈来。
1、数据库是一个非常专业的细分领域,传统的ITOM工具集成的监控功能往往太粗放,所以需要专业的数据库多维度监控,各项监控指标数据需要实时采集并存放,根据趋势进行告警。
就拿本案例来说,如果有对Exadata服务存活的监控,问题至少在故障发生前一星期就能得到预警,并及时处理。
2、日常运维场景化
太多的数据库意味着任何一个点的维护,都需要大量的时间消耗,因此需要集成、封装一些运维场景。比如:
- 自动化日常数据库的巡检
- 告警日志、跟踪日志的压缩和归档
- 比如定时作业的维护
- 容量趋势提醒及半自动扩容
- 以及一些自定义的场景(一些客户几百套Data Guard的日志修复)
- 历史数据自动归档
- .......
有了这些功能,你是不是可以省下好多时间钻研新技术,为企业核心技能的更新换代贡献自己的能量,而不需要整天想着逃离苦海了呢。
3、数据库实时性能分析
此功能意义很大,看下面两个场景:
- 比如一个电话打过来,小张,刚才小王说昨天下午2点22到2点30期间数据库很慢,他们自己重启了机器解决了,你分析下原因。这个时候你通常只能寄希望于dba_hist_sqlstat,但这个粒度太粗,结果就是往往没有结果;
- 时间不要离这么久,数据库发生大量TX锁资源了,帮忙查看下源头是谁。你一去看源头进程是3456,不过人家是idle进程,是一条select语句,显然不是它锁的。
如果有一个工具,能帮你实时记录数据库的这些信息,而且不用查询数据库,而是直接读取SGA,那这一些问题都能够分分钟解决,是不是很爽?
4、应用性能追溯
有些问题,明显是应用的问题,可是如果你不明确告诉他,是哪个应用模块,哪个用户干的,你几乎就说不清楚是应用的问题。
如果运维管理工具不仅仅能够帮你发现是哪个SQL语句导致,说出program,而且能告诉你是从哪个路径爬过来的,是由哪个jar包发起,那是不是一切就显而易见了呢。让背锅的日子见鬼去吧。
那么,存在这样的数据库运维管理工具么?
答案是yes。
作者介绍 杨志洪
- 【DBAplus社群】联合发起人,新炬网络首席布道师。Oracle ACE、OCM、《Oracle核心技术》译者。
- 数据管理专家,拥有十余年电信、银行、保险等大型行业核心系统Oracle数据库运维支持经验,掌握ITIL运维体系,擅长端到端性能优化、复杂问题处理。现主要从事数据架构、高可用及容灾咨询服务
- 文章出处:DBAplus社群(微信公众号ID:dbaplus)
正文到此结束
热门推荐










相关文章

近期评论
-
666 666
-
666
-
文章和留言都翻到11页了 没有OOM
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
-
-
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

