深析filemap.js——关于JS的算法及优化的实践
项目地址: 链接描述
项目简介: https://segmentfault.com/a/1190000005968734
关于项目的用法和介绍可以查看上面的两个链接,这篇文章主要内容是对 filemap.js 的代码进行一步一步的分析,详细介绍其运行原理和优化策略。
知识点准备:
-
NodeJS的基本使用方法(主要是fs文件系统); -
ES6特性及语法(let,const,for...of,arrow function...) -
n叉树先序遍历算法。
知识点1和2请自行查阅资料,现在对知识点3进行分析。
N叉树先序遍历算法
首先明白什么是树。引用 数据结构与算法JavaScript描述 :
一个树结构包含一系列存在父子关系的节点。每个节点都有一个父节点(除了顶部的第一个节点)以及零个或多个子节点:
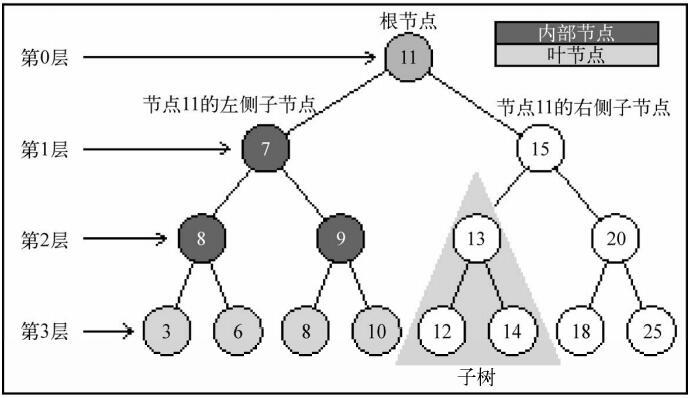
位于树顶部的节点叫作根节点(11)。它没有父节点。树中的每个元素都叫作节点,节点分为内部节点和外部节点。至少有一个子节点的节点称为内部节点(7、5、9、15、13和20是内部节点)。没有子元素的节点称为外部节点或叶节点(3、6、8、10、12、14、18和25是叶节点)。
一个节点可以有祖先和后代。一个节点(除了根节点)的祖先包括父节点、祖父节点、曾祖父节点等。一个节点的后代包括子节点、孙子节点、曾孙节点等。例如,节点5的祖先有节点7和节点11,后代有节点3和节点6。
有关树的另一个术语是子树。子树由节点和它的后代构成。例如,节点13、12和14构成了上图中树的一棵子树。
节点的一个属性是深度,节点的深度取决于它的祖先节点的数量。比如,节点3有3个祖先节点(5、7和11),它的深度为3。
树的高度取决于所有节点深度的最大值。一棵树也可以被分解成层级。根节点在第0层,它的子节点在第1层,以此类推。上图中的树的高度为3(最大高度已在图中表示——第3层)。
对于一棵树的遍历,有 先序 , 中序 和 后序 三种遍历方式,在本例中使用的是 先序遍历 的方式。至于三种遍历方式的异同,请阅读 数据结构与算法JavaScript描述 ,里面有详细的介绍。
首先我们创建一棵树:
let treeObj = { '1': [ { '2': [{ '5': [{ '11': '11' }, { '12': '12' }, { '13': '13' }, { '14': '14' }] }] }, { '3': [{ '6': '6' }, { '7': '7' }] }, { '4': [{ '8': '8' }, { '9': '9' }, { '10': '10' }] } ] } 为了简单方便,我把它的key和value都设置成了相同的值。在例子中我们使用的都是key值。
然后分析 先序遍历 的原理:
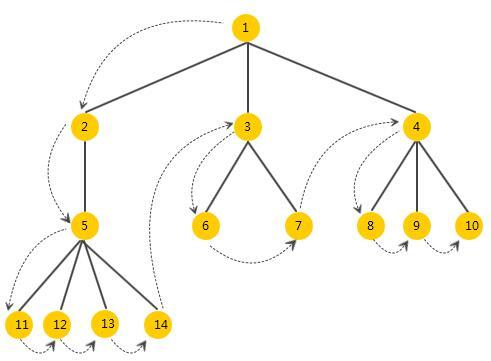
虚线为遍历顺序,可以看出 先序遍历 可以得到整棵树的结构,这正是我们所需要的。接下来看代码如何实现。先看完整代码:
let traverseNode = (node, deep) => { if (typeof node !== 'string') { let key = Object.keys(node) console.log(key, deep) for (let i = 0; i < node[key].length; i++) { traverseNode(node[key][i], deep + 1) } } } traverseNode(treeObj, 1) 我们创建了一个 traverseNode() 函数,它接收两个对象作为参数。 node 参数为传入的节点, deep 参数为节点的起始深度。
首先使用 Object.keys(obj) 方法取得节点的key值,同时输出深度值:
let key = Object.keys(node) console.log(key, deep)
运行,在控制台将会输出 [ '1' ] 1 。接下来我们使用递归来重复这个过程,进行完整的遍历运算:
for (let i = 0; i < node[key].length; i++) { traverseNode(node[key][i], deep + 1) } 这个递归就是我们前文一直在说的 先序遍历 。对于 二叉树 :
先序遍历是以优先于后代节点的顺序访问每个节点的。先序遍历的一种应用是打印一个结构化的文档。
先序遍历会先访问节点本身,然后再访问它的左侧子节点,最后是右侧子节点。
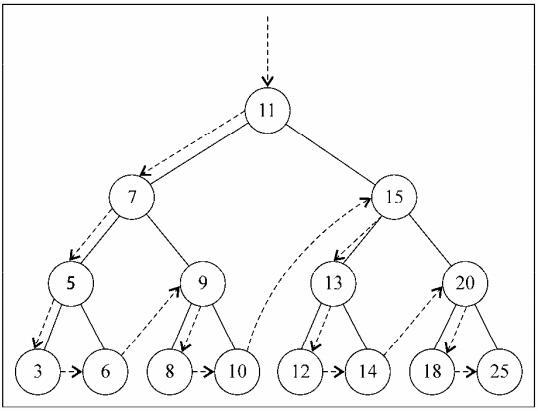
在理解完上面这段话以后,不难把 先序遍历 的思路扩展到 n叉树 :先访问节点本身,然后从左到右访问它的n个子节点。
每一次完整的for循环都意味着“往下走一层”,所以只需要 deep + 1 即可知道每一个节点对应的深度。
在本例子的遍历过程中, node 都是一个个的对象而非字符串。如果检测到 node 为字符串,证明其已经到了最后一层,需要停止,否则会无限循环导致溢出,所以我们需要添加一个判断:
if (typeof node !== 'string')
大功告成,现在我们尝试运行一下:
[ '1' ] 1 [ '2' ] 2 [ '5' ] 3 [ '11' ] 4 [ '12' ] 4 [ '13' ] 4 [ '14' ] 4 [ '3' ] 2 [ '6' ] 3 [ '7' ] 3 [ '4' ] 2 [ '8' ] 3 [ '9' ] 3 [ '10' ] 3
完美。
filemap.js原理
filemap.js 通过遍历一个文件夹内部的所有子文件和子文件夹,输出其目录结构。我们使用 fs 文件系统来进行。
const fs = require('fs') 然后来构造核心部分代码:
// 判断类型。若该路径对应的是文件夹则返回true,否则返回false let isDic = (url) => fs.statSync(url).isDirectory() const traverseFiles = (path, deep) => { let files = fs.readdirSync(path) for (let i = 0, len = files.length; i < len; i++) { if (files[i] !== 'filemap.js') console.log(deep, files[i], '/n') // 忽略filemap.js本身 let dirPath = path + '//' + files[i] // 当且仅当是文件夹时才进行下一轮遍历 if (isDic(dirPath)) traverseFiles(dirPath, deep + 1) } } 文件目录结构其实就是一棵典型的 n叉树 ,通过前文的例子,不难明白这段代码的原理。首先通过 fs.readdirSync(path) 同步地获取某路径对应的所有文件(夹),然后进行递归。可以把它理解为从第二层开始遍历,所以在写法上和前文例子稍有不同。
现在我们已经可以获取文件及其所在的深度了,接下来就是对这些信息进行格式化,使其输出更加直观。为了输出类似
|__folder |__file1 |__file2
这样的树状结构,我们需要判断不同的深度对应的缩进,所以我们来定义一个 placeHolder() 函数:
const placeHolder = (num) => { if (placeHolder.cache[num]) return placeHolder.cache[num] + '|__' placeHolder.cache[num] = '' for (let i = 0; i < num; i++) { placeHolder.cache[num] += ' ' } return placeHolder.cache[num] + '|__' } placeHolder.cache = {} 这里涉及到一个 缓存函数执行结果 的优化策略。由于该函数多次被使用,如果每一次都是从头开始进行for循环,在性能上有着巨大的浪费。所以我们可以把它的执行结果缓存起来,当以后遇到相同情况时只需要取出缓存的结果即可,无需重新运算,大大提升了性能。
现在我们把核心代码改写一下:
let isDic = (url) => fs.statSync(url).isDirectory() const traverseFiles = (path, deep) => { let files = fs.readdirSync(path) for (let i = 0, len = files.length; i < len; i++) { if (files[i] !== 'filemap.js') console.log(placeHolder(deep), files[i], '/n') // 忽略filemap.js本身 let dirPath = path + '//' + files[i] if (isDic(dirPath)) traverseFiles(dirPath, deep + 1) } } traverseFiles('./', 1) 在根目录中运行 node filemap.js ,我们就能够得到完美的文件目录树状结构图了。
功能进一步扩展
现在是“无差别”地对所有文件夹进行展开。如果想要忽略某些文件夹,比如 .git 或者 node_modules 之类的文件夹,应该如何做呢?参考命令行输入参数的方法,这个需求不难实现。
首先获取需要忽略的文件夹名:
let ignoreCase = {} if(process.argv[2] === '-i'){ for (let i of process.argv.slice(3)) { ignoreCase[i] = true } } ignoreCase 保存着需要忽略的文件夹名。这里使用对象而不是数组的原因是,当判断一个 item 是否被已经被保存的时候, item.indexOf(Array) 的效率并没有 Object[item] 来得高。使用 for...of 循环能够直接取得对象。
接下来我们可以在核心代码中多加一个判断:
let isDic = (url) => fs.statSync(url).isDirectory() const traverseFiles = (path, deep) => { let files = fs.readdirSync(path) let con = false for (let i = 0, len = files.length; i < len; i++) { if (files[i] !== 'filemap.js') console.log(placeHolder(deep), files[i], '/n') con = ignoreCase[files[i]] === undefined? true: false let dirPath = path + '//' + files[i] if (isDic(dirPath) && con) traverseFiles(dirPath, deep + 1) } } 被忽略的文件夹将不会进行递归运算。最后别忘了在退出进程:
process.exit()
至此,完整的 filemap.js 已经完成,其所有代码如下:
/** * @author Jrain Lau * @email jrainlau@163.com * @date 2016-07-14 */ 'use strict' const fs = require('fs') let ignoreCase = {} if(process.argv[2] === '-i'){ for (let i of process.argv.slice(3)) { ignoreCase[i] = true } } console.log('/n/nThe files tree is:/n=================/n/n') const placeHolder = (num) => { if (placeHolder.cache[num]) return placeHolder.cache[num] + '|__' placeHolder.cache[num] = '' for (let i = 0; i < num; i++) { placeHolder.cache[num] += ' ' } return placeHolder.cache[num] + '|__' } placeHolder.cache = {} let isDic = (url) => fs.statSync(url).isDirectory() const traverseFiles = (path, deep) => { let files = fs.readdirSync(path) let con = false for (let i = 0, len = files.length; i < len; i++) { if (files[i] !== 'filemap.js') console.log(placeHolder(deep), files[i], '/n') con = ignoreCase[files[i]] === undefined? true: false let dirPath = path + '//' + files[i] if (isDic(dirPath) && con) traverseFiles(dirPath, deep + 1) } } traverseFiles('./', 1) process.exit() 使用时只需要带上参数 -i 文件夹1 文件夹2 ... 即可控制文件夹的展开与否。
后记
在学习 数据结构与算法JavaScript描述 的过程中,有时候真的觉得特别困,后来发挥自己喜欢折腾的个性,想办法把枯燥的东西进行实践,不知不觉就会变得有趣了。在 filemap.js 的早期版本中有着许多bug和性能问题,比如不合理使用三元表达式,没有缓存函数执行结果,判断文件类型考虑不周等等情况。文中所涉及到的优化策略,有很多是来自他人的指点和一次次的修改才最终得出来的,在此非常感谢给予我帮助的人。
最后感谢你的阅读。我是Jrain,欢迎关注我的专栏,将不定期分享自己的学习体验,开发心得,搬运墙外的干货。下次见啦!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

