基于容器的分布式系统的设计模式
1、 介绍
在20世纪80年代末和20世纪90年代初,面向对象编程彻底改革了软件开发方法,普及了将应用程序作为模块化组件的创建方法。随着基于容器化软件组件的微服务架构的逐渐普及,现在在分布式系统开发中也发生着类似的革命。容器之间相互隔离的优点使得容器成为了分布式系统中合适的基本单元。随着这种架构类型的成熟,我们可以看到设计模型的出现,从容器的角度来思考问题可以将低层次代码细节抽象化。
这篇论文描述了我们观察到的三种基于容器分布式系统的设计模型:单个容器模式,密切合作模式容器的单节点模式,以及分布式算法的多节点模式。跟面向对象编程的设计模式类似,这些模式包含了最佳实践,简化了开发,使系统更加可靠。
2、分布式系统设计模式
在面向对象编程被使用了几年之后,设计模式出现并被编成文档。这些模式被编纂好,并且被规整成解决特别常见的编程问题的方法。这个编纂进一步提高了编程最前沿的技术,因为它可以让经验不那么丰富的人也写出很好的代码,并且让重复使用的库文件的蓬勃发展,这些库文件可以让开发代码更加可靠、快速。
前分布式系统工程的技术水准,比起面向对象开发,更像是20世纪80年代的编程的水平。显然,MapReduce模式将“大数据”编程的力量带入广泛的领域和更多的开发者是一个巨大的成功,将正确的模式放在合适的位置可以很大程度上提高分布式系统编程的质量、速度和可达性。虽然MapReduce的成功受限于单个编程语言,在Apache Hadoop生态系统范围内,只对一种编程语言(java)产生了影响。为分布式系统开发一款全面的一套模式需要一个非常通用,与语言无关的交流工具来呈现系统的精髓。
所以,很幸运能够看到过去两年内,越来越多的人选择使用容器技术。容器和容器镜像正是分布式系统模式开发所需要的抽象。至今为止,容器和容器镜像已经在很大程度上受到了欢迎,因为它是一种更好,更可靠的通过产品来交付软件的方法。因为容器是密闭的,包含了依赖关系,并且有一个原子的部署信号("succeeded”/“failed”),他们很大程度上提升了之前在数据中心或云端部署软件的技术。但是容器不仅仅只是一个很好的部署工具,我们认为容器最终会成为面向对象软件系统中的对象一样,并且因此驱使了分布式系统设计模式的发展。在接下来的部分,我们会解释为什么我们相信会是这样,并且描述出现的一些在未来几年中可以使分布式系统规整化的设计模式。
3、单个容器管理模式
容器为定义接口提供了一个自然的边界,类似于对象边界。容器不仅能够暴露专用应用功能,还能够通过这个接口跟管理系统挂钩。
传统的容器管理接口是极其有限的。对容器的有效操作为:run,pause和stop。虽然这个接口十分有用,但是更丰富的接口可以给系统开发者和操作者提供更多的实用功能。考虑到目前几乎所有现代编程语言对HTTP服务器的开发以及对json这种数据格式的普遍支持,很容易让容器提供一个基于HTTP管理的API。
“upward”方向,容器可以暴露一套丰富的应用程序信息,包括应用专用监控参数(QPS,应用程序健康等等),用户感兴趣的信息(threads,stack,lock contention,network,message statistics等等),组件配置信息和组件日志。一个具体例子就是,Kubernetes,Aurora,Marathon和其它容器管理系统允许用户通过特定的HTTP端点(比如,”/health”)来定义健康检查。对于之前说过的“upword”API的其它元素的标准化支持就更少了。
“downward”方向,容器接口提供一个地方来定义生命周期,使得写管理系统控制的软件组件更加容易。比如,集群管理系统通常会将“priorities”归到任务中,即使集群订阅超额,高优先级的任务也会保证运行。这个保证通过杀死已经在运行的低优先级的任务来完成,低优先级的任务要等到资源可用的时候才会再继续完成。驱逐只要通过简单的杀死低优先级的任务就可以实施,但是这就给开发人员带来了很多不必要的负担,他们需要在代码中处理任务被杀掉的情况。相反,如果在应用系统和管理系统中定义了正式的生命周期,应用程序组件就会变得更加可管理,因为开发者可以依照正式的生命周期来开发。比如,Kubernetes使用Docker的“优雅终止”功能,通过SIGTERM信号来警告容器,它在一个自定义的时长之后会接受到SIGKILL信号,并被终止。这就允许应用程序通过完成当前任务,把状态写入磁盘等等操作之后再终止。你可以想象扩展这种机制用来支持序列化和恢复,使得有状态的分布式系统状态管理更加容易。
对于更加复杂的生命周期的例子,考虑到Android的Activity模型,这个模型包含了一系列的回调函数(比如onCreate(),onStart(),onStop(),…)和一个状态机来定义何时触发这些回调函数。没有了正式的生命周期,健壮,开发可靠的安卓应用程就更加难了。在基于容器的系统中,这就对应了自定义的一些钩子,这些钩子会在容器创建时,容器开始运行时,容器结束运行前等情况下被调用。
4、单节点,多容器应用程序模式
除了单个容器的接口,我们也看到了一些跨容器的设计模式。我们之前就已经确认了几个这样的模式。这种单节点的模式包括了同时运行在单个主机上的共生容器。容器管理系统支持同时运行多个容器作为一个整体单元,所以抽象(Kubernetes叫它“pods”,Nomad叫它“task groups”)是一个用来启动我们之前描述过的模式的必需功能。
4.1 sidcar模式
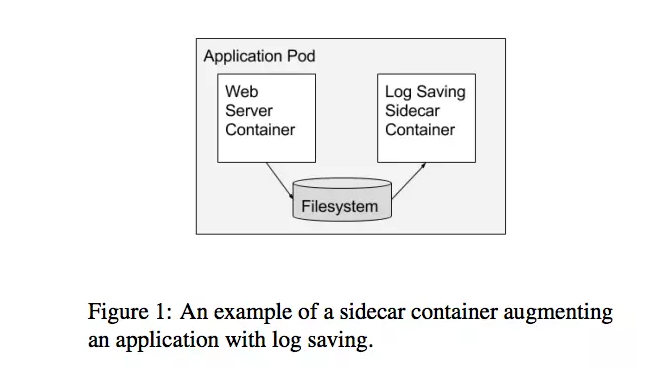
对于多个容器配置来说,第一个,也是最普遍的情况就是sidcar模式。Sidecar扩展并且提高了大多数的容器。比如,主容器可能是一个网页服务器,它可能跟“logsaver” sidecar容器配对,然后saidecar容器从本地磁盘收集网页服务器的日志,并且将他们stream到集群存储系统。图1展示的就是sidcar模式的一个例子。另一个普遍的例子就是从本地磁盘内容服务的网页服务器,这个sidecar会定期跟git库进行内容管理系统或者其它数据源的存储进行同步。这两个例子在谷歌是十分普遍的。因为在同一个机器上的容器可以共享一个本地磁盘数据卷,所以sidecar是可能做的。
虽然创建sidecar容器的功能到主容器里永远可行,但是使用分开的容器有以下几点好处。首先,容器是资源账户和分配的单元,那么比如一个网页服务器容器的cgroup可以被配置,那样的话,它就会提供持续的低延迟反应到问题,虽然logsaver容器在网页服务器不忙的时候被配置来清除空闲CPU周期。第二,容器是打包的单元,所以将服务和日志保存分到不同的容器可以让两个独立的编程团队之间的可靠性分开,并且允许他们独立测试,跟一起测试的时候是一样的。第三,容器是重复使用的单元,所以sidecar容器可以跟很多不同的主容器(比如logsaver容器可以被任意产生日志的组件使用)。第四,容器控制边界错误服务,使得整个系统能够正确推出(比如,网页服务器即使在日志保存运行失败的状态下也能够继续服务)。最后一点,容器是配置的单元,每个功能都可以更新,并且必要的时候能独立回滚。(但是要注意的是,最后一点好处也有不好的地方——总体系统的测试模型必须要考虑到在生产过程中所有的容器版本组合,这些版本可能会很大,因为容器总体上来说通常不能自动升级。当然,单一的应用程序没有这个问题,组件化的系统在某种程度上更容易测试,因为他们是在更小的可以独立测试的单元的基础上测试的)。注意,这五点优点应用于我们接下来在论文中描述的容器模式。
4.2 Ambassador模式
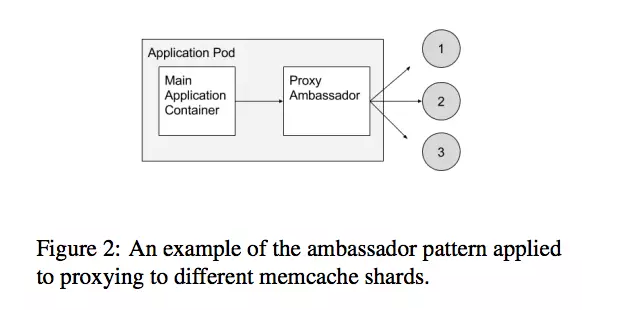
接下来要说的是我们观察到的ambassador模式。Ambassador容器代理服务会跟主容器进行交流。比如,开发者可能匹配一个正在跟twenproxy ambassador进行交流的memcache。应用程序相信这只是跟单个在本地主机上的memcache交流,但是现实中,twenproxy正在跟多个memcache集群中的其他节点的分布式安装进行共享。这个容器模式以三种方式简化了编程:他们只需要思考编程,依据他们连接到本地主机的单个服务器,他们可以通过运行真正的memcache实例来单独测试他们的应用程序,而且他们也可以利用其他的应用程序(可能会用不同语言编写)重新使用twenproxy ambassador。Ambassadors也是可能的因为在同一个机器上分享同一个本地主机网络接口。这个模式的例子如图片2所示的。
4.3 适配器模式
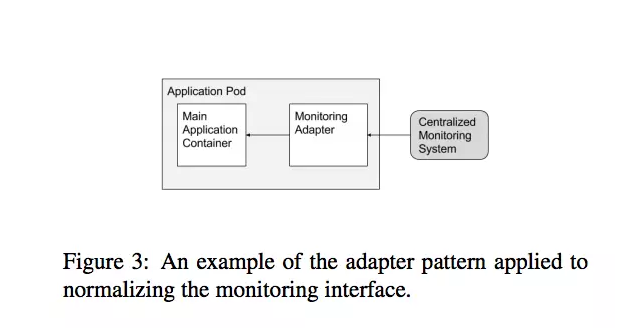
最后一个要说的是我们观察到的适配器模式。相比于用外部的简化来呈现应用程序的ambassador模式,适配器用的事简化的,均质的应用程序来呈现外部世界。他们是通过将多容器间输出和接口标准化才做到这样的。适配器模式具体的例子就是,适配器确保所有在一个系统内的容器都有相同的监控接口。现在应用程序使用很多种方法来输出他们的参数(比如,JMX,statsd等等)。但是对于单个监控工具来说,收集,集合,以及从异构应用程序呈现数据就很容易,如果所有应用程序呈现一致的监控界面的话。在谷歌,我们通过编码规范来完成,但是只有在你从scratch创建自己的软件的时候才有可能。适配器模式让异构的旧世界和开源应用程序呈现统一的接口,不需要修改原始程序。主容器能够跟适配器通过本地主机或者共享的本地数据卷交流。详情请查看图3。注意,一些已经存在的监控方法能够跟多种类型的后端,他们在监控系统中使用专用应用程序代码,提供了一个不那么清洁的关注点的隔离。
5、多节点应用程序模式
在单个机器上移动合作的容器,让创建合作的多节点分布式应用程序更加容易。之后我们接下来会具体描述一下这些分布式系统模式中的三种。比如之前章节提过的那些模式,这些也要求为Pod抽象提供系统支持。
5.1 leader选举模式
分布式系统中常见问题之一就是leader选举。副本被普遍使用在一个组件的多个相同的实例之间共享负载,副本的另一个更加复杂的作用就是在应用程序需要区分副本跟设置来作为“leader”。其它的副本对于快速取代leader的位置是十分快速的,如果之前的副本失败了的话。一个系统甚至可以平行运行多个leader选举,比如,要定义多个碎片中每一个的leader。运行leader选举有很多库。用起来又复杂又难理解,要正确使用真的很困难,另外,他们的限制之处在于,只能用特定的编程语言来写。把leader选举库连接到应用程序的另一种方法就是使用leader选举容器。leader选举容器,每一个都跟需要leader选举的应用程序的实例同步,而且能够在他们自己之间进行选举,同时他们也可以在本地主机上呈现一个简化的HTTP API给每一个需要leader选举的应用程序容器(比如,becomeLeader,renewLeadership等等)。这些leader选举容器只能被创建一次,随后简化的接口可以由应用程序开发人员重新使用,不管他们选择什么语言来实现。在软件工程领域,这是最好的抽象和封装的代表。
5.2 work quene模式
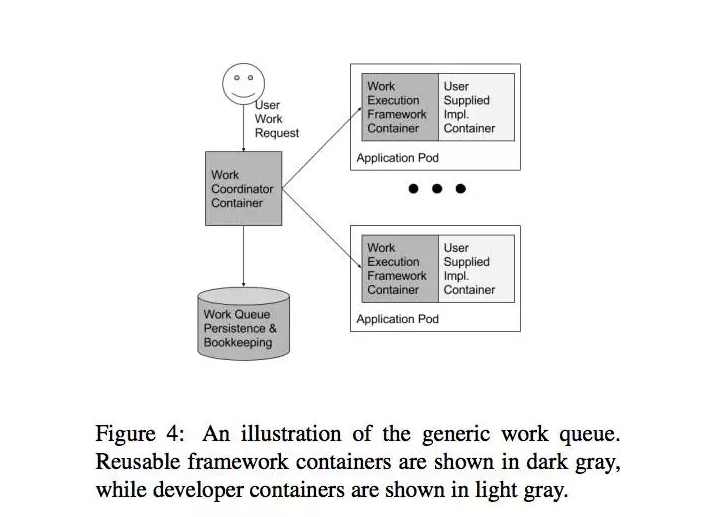
虽然work queen跟leader选举一样,是一种很好研究的项目,因为有很多框架可以来实现他们,他们同时也是分布式系统模式例子,这个模式可以从面向容器的架构中受益。在之前的系统中,框架限制于单个语言环境编程(比如,Celery for Python),或者work和二进制的分布练习留给了实现它的人(比如,Condor)。实现run()和mount()接口的容器可用性使实现一个通用的work queen框架十分简单,这个框架可以处理任意的进程中打包为容器的代码,并且创建一个完整的work queen系统。开发者只能选择去创建一个可以在文件系统处理输入数据文件的容器,并且将之转化为一个输出文件;这个容器将会变成work queen的一个阶段。用户的代码整合到这个共享的work queen框架的方式图4中已经阐述了。
5.3 Scatter/gather模式
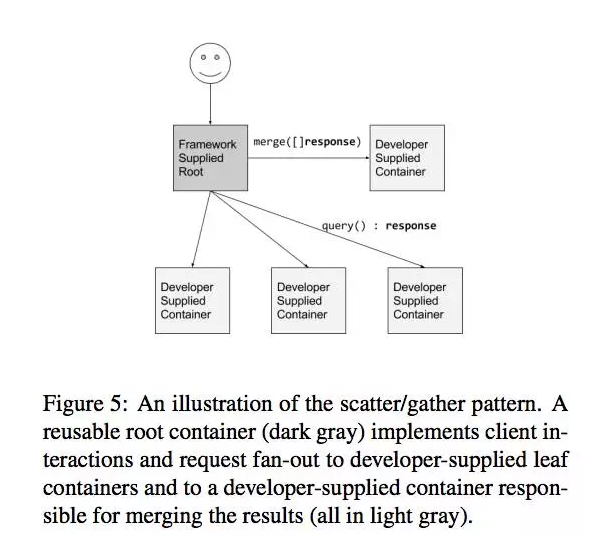
最后一个要强调的分布式系统模式就是Scatter/gather模式。在这样一个系统中,一个外部客户发送一个初始请求到“root”或者“parent”节点。这个root将请求分散到很多很多服务器上来执行平行计算。每个碎片返回部分数据,root将这个数据收集起来归成单个的回应到原始请求。这个模式在搜索引擎中是十分普遍的。开发这样一个分布式系统牵扯到很多样板文件代码:分散请求,收集回应,与客户端交互等等。代码有很多是泛化的,再次,就如同在面向对象编程中,代码可以用这种方法被重构,单个实现可以被提供的方法,这个方法也可以被用在任意容器中,只要他们实施一个特殊的接口就可以。特别是,为了实施一个Scatter/gather系统,用户被要求提供两个容器。第一,容器实施了树结构端节点;这个容器会执行部分求值,并且返回对应结果。第二个容器就是合并容器;这个容器带走了所有树结构端节点的总生产额,并且将它们归到单个回应的组。
这样的系统如图5所示。
6、相关工作
面相服务的架构体系(SOA)更新地比原来早,和基于容器的分布式系统共享很多特征。比如,都强调可重用的定义好的通过网络进行通信的接口的组件。另一方面,SOA系统中的组件趋向于大粒度,相比于我们之前描述过的多容器模式,有更多的松耦合。此外,SOA中的组件实施商务活动,我们在这里重点关注的组件类似于比较容易创建分布式系统的通用库。“微服务”这个词语最近出来,描述的是我们在这篇论文中讨论过的组件的类型。
标准化管理接口的概念要至少要追溯到SNMP。SNMP主要关注管理硬件组件,而且现在还没有出现用来管理微服务/基于容器的系统。这还是没能阻止许多容器管理系统的开发,包括Aurora,ECS,Docker Swarm,Kubernetes,Marathon和Nomad。
在第5节中提到的分布式算法都有段很长的历史。你们可以在Github上找到很多leader选举实施,虽然他们结构上作为库而不是独立的组件。还是有很多受欢迎的work quene实现了的,包括Celery和Amazon SQS。Scatter/gather已经成为一个企业的继承模式。
文章由才云科技翻译,如若转载,必须注明转载自“才云科技”。
原文作者:Brendan Burns、 David Oppenheimer
原文链接: https://www.usenix.org/system/ ... 7f865

正文到此结束
- 本文标签: ask 集群 大数据 HTTP服务器 Kubernetes 测试 同步 科技 配置 生命 GitHub java 谷歌 git src 搜索引擎 IDE message Android 翻译 开源 tar 安装 http API 云 Docker ip 企业 cat 数据 文章 Apache Hadoop 服务器 开发 map ECS SOA 图片 json 质量 Uber 产品 开发者 python 设计模式 root 参数 js apr 主机 管理 cache 实例 Hadoop Amazon 进程 UI Word 代码 apache 软件 https
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

