Mesos高可用解决方案剖析
王勇桥,80后的IT攻城狮,供职于IBM多年,Mesos和Swarm社区的贡献者。
本文节选自《程序员》,谢绝转载,更多精彩,请订阅《程序员》
责编:魏伟,欢迎投稿和咨询报道,详情联系weiwei@csdn.net
CSDN Docker专家群已经建立,还等什么,加入我们吧,微信搜索“k15751091376”加入
本文系作者根据自己对Mesos的高可用(High-Availability)设计方案的了解以及在Mesos社区贡献的经验,深度剖析了Mesos集群高可用的解决方案,以及对未来的展望。
Mesos高可用架构概述首先,我们来参考Mesos官方给出的设计架构,如图1所示。
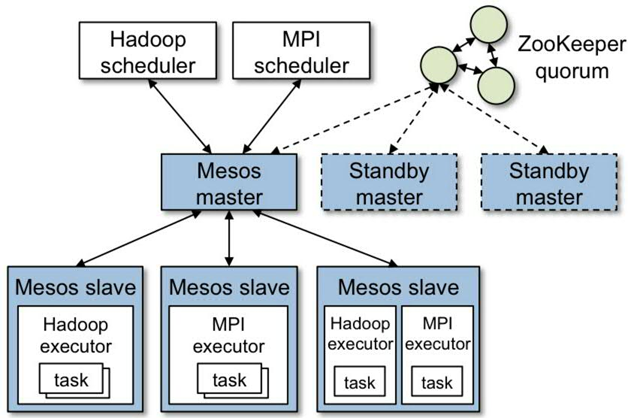
Mesos采用的也是现在分布式集群中比较流行的Master/Slave主从集群管理架构,Mesos master节点是整个集群的中枢,它责管理和分配整个Mesos集群的计算资源,调度上层Framework提交的任务,管理和分发所有任务的状态。这种主从架构设计简单,能够满足大多数正常情况下的集群运作需求,目前仍然存在于很多分布式的系统中,比如Hadoop、MySQL集群等。但是这种简单的设计存在一个致命缺陷,就是Mesos master必须做为一个服务程序持续存在于集群中,它虽然孤立,但是地位举足轻重,不容有失。
在单个Mesos master节点的集群中,如果Mesos master节点故障,或者服务不可用,虽然在每一个Slave节点上的任务可以继续运行,但是集群中新的资源将无法再分配给上层Framework,上层Framework将无法再利用已经收到的offer提交新任务,并且无法收到正在运行任务的状态更新。为了解决这个问题,提高Mesos集群的高可用性,减少Mesos master节点故障所带来的影响,Mesos集群采用了传统的主备冗余模式(Active-Standby)来支持一个Mesos集群中部署多个Mesos master节点,借助于ZooKeeper进行Leader的选举。选举出的Leader负责将集群的资源以契约(offer)的形式发送给上层的每一个Framework,并处理集群管理员与上层Framework的请求,另外几个Mesos master节点将作为Follower一直处于备用状态,并监控当前的状态,当Mesos master节点宕机,或服务中断之后,新Leader将会很快从Follower中选出来接管所有的服务,减少了Mesos集群服务的宕机时间,大大提高了集群的可用性。
Mesos高可用集群部署在Mesos高可用设计中,引入了ZooKeeper集群来辅助Leader的选举,这在当前的分布式集群中比较流行,比如Docker Swarm高可用集群同时支持利用consul、etcd、ZooKeeper进行Leader的选举,Kubernetes也采用了etcd等实现了自身的高可用。这种设计可以理解为大集群+小集群,小集群也就是ZooKeeper/etcd/consul集群,它们为大集群服务,比如提供Leader的选举,为大集群提供配置数据的存储和服务发现等功能。在一个复杂的系统中,这个小集群可以为系统的多个服务组件同时提供服务。因此在部署高可用Mesos集群时,必须首先部署好一个ZooKeeper集群。
本文主要介绍Mesos的高可用,不会详细介绍ZooKeeper的相关知识你可以参考官方文档https://ZooKeeper.apache.org/来部署。为了使读者可以快速搭建它们自己的Mesos高可用集群,我们将使用Docker的方式在zhost1.wyq.com(9.111.255.10),zhost2.wyq.com(9.111.254.41)和zhost3.wyq.com(9.111.255.50)机器上快速的搭建起一个具有三个节点的演示ZooKeeper集群,它们的服务端口都是默认的2181。
登录zhost1.wyq.com机器,执行如下命令启动第一个server:
# docker run -d / -e MYID=1 / -e SERVERS=9.111.255.10,9.111.254.41,9.111.255.50 / --name=zookeeper / --net=host / --restart=always / mesoscloud/zookeeper
登录zhost2.wyq.com机器,执行如下命令启动第二个server:
# docker run -d / -e MYID=2 / -e SERVERS=9.111.255.10,9.111.254.41,9.111.255.50 / --name=zookeeper / --net=host / --restart=always / mesoscloud/zookeeper
登录zhost3.wyq.com机器,执行如下命令启动第三个server:
# docker run -d / -e MYID=3 / -e SERVERS=9.111.255.10,9.111.254.41,9.111.255.50 / --name=zookeeper / --net=host / --restart=always / mesoscloud/zookeeper
ZooKeeper集群搭建好之后,执行以下命令,通过指定一个不存在的znode的路径/mesos来启动所有的Mesos master,Mesos slave和Framework。
登陆每一个Mesos master机器,执行以下命令,在Docker中启动所有的Mesos master:
# docker run -d / --name mesos-master / --net host mesosphere/mesos-master / --quorum=2 / --work_dir=/var/log/mesos / --zk= zk://zhost1.wyq.com:2181,zhost2.wyq.com:2181,zhost3.wyq.com:2181/mesos
登陆每一个Mesos Agent机器,执行以下命令,在Docker中启动所有的Mesos agent:
# docker run -d / --privileged / -v /var/run/docker.sock:/var/run/docker.sock / --name mesos-agent / --net host gradywang/mesos-agent / --work_dir=/var/log/mesos / --containerizers=mesos,docker / --master= zk://zhost1.wyq.com:2181,zhost2.wyq.com:2181,zhost3.wyq.com:2181/mesos
注意:Mesosphere官方所提供的Mesos Agent镜像mesosphere/mesos-agent不支持Docker的容器化,所以作者在官方镜像的基础至上创建了一个新的镜像gradywang/mesos-agent来同时支持Mesos和Docker的虚拟化技术。
使用相同的znode路径来启动framework,例如我们利用Docker的方式来启动Docker Swarm,让它运行在Mesos之上:
$ docker run -d / --net=host gradywang/swarm-mesos / --debug manage / -c mesos-experimental / --cluster-opt mesos.address=9.111.255.10 / --cluster-opt mesos.tasktimeout=10m / --cluster-opt mesos.user=root / --cluster-opt mesos.offertimeout=1m / --cluster-opt mesos.port=3375 / --host=0.0.0.0:4375 zk://zhost1.wyq.com:2181,zhost2.wyq.com:2181,zhost3.wyq.com:2181/mesos
注:mesos.address和mesos.port是Mesos scheduler的监听的服务地址和端口,也就是你启动Swarm的机器的IP地址和一个可用的端口。个人感觉这个变量的命名不是很好,不能见名知意。
用上边的启动配置方式,所有的Mesos master节点会通过ZooKeeper进行Leader的选举,所有的Mesos slave节点和Framework都会和ZooKeeper进行通信,获取当前的Mesos master Leader,并且会一直检测Master节点的变化。当Leader故障时,ZooKeeper会第一时间选出新Leader,然后所有的Slave节点和Framework都会获取到新Leader进行重新注册。
ZooKeeper Leader的选举机制根据ZooKeeper官方推荐的Leader选举机制:首先指定一个Znode,如上例中的/mesos(强烈建议指定一个不存在的Znode路径),然后使用SEQUENCE和EPHEMERAL标志为每一个要竞选的client创建一个Znode,例如/mesos/guid_n来代表这个client。
当为某个Znode节点设置SEQUENCE标志时,ZooKeeper会在其名称后追加一个自增序号,这个序列号要比最近一次在同一个目录下加入的znode的序列号大。具体做法首先需要在ZooKeeper中创建一个父Znode,比如上节中指定的/mesos,然后指定SEQUENCE|EPHEMERAL标志为每一个Mesos master节点创建一个子的Znode,比如/mesos/znode-index,并在名称之后追加自增的序列号。
当为某个Znode节点设置EPHEMERAL标志时,当这个节点所属的客户端和ZooKeeper之间的seesion断开之后,这个节点将会被ZooKeeper自动删除。
ZooKeeper的选举机制就是在父Znode(比如/mesos)下的子Znode中选出序列号最小的作为Leader。同时,ZooKeeper提供了监视(watch)的机制,其他的非master节点会不断监视当前的Leader所对应的Znode,如果它被删除,则触发新一轮的选举。大概有两种做法:
1.所有的非Leader client监视当前Leader对应的Znode(也就是序列号最小的Znode),当它被ZooKeeper删除的时候,所有监视它的客户端会立即收到通知,然后调用API查询所有在父目录(/mesos)下的子节点,如果它对应的序列号是最小的,则这个client会成为新的Leader对外提供服务,然后其他客户端继续监视这个新Leader对应的Znode。这种方式会触发“羊群效应”,特别是在选举集群比较大的时候,在新一轮选举开始时,所有的客户端都会调用ZooKeeper的API查询所有的子Znode来决定谁是下一个Leader,这个时候情况就更为明显。
2.为了避免“羊群效应”,ZooKeeper建议每一个非Leader的client监视集群中对应的比自己节点序小一号的节点(也就是所有序号比自己小的节点中的序号最大的节点)。只有当某个client所设置的watch被触发时,它才进行Leader选举操作:查询所有的子节点,看自己是不是序号最小的,如果是,那么它将成为新的Leader。如果不是,继续监视。此 Leader选举操作的速度是很快的。因为每一次选举几乎只涉及单个client的操作。
Mesos高可用实现细节Mesos主要通过contender和detector两个模块来实现高可用,架构如图2所示。
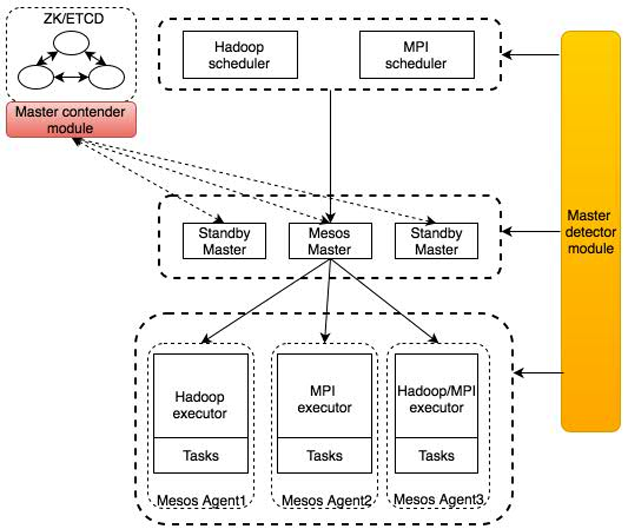
Contender模块用来进行Leader选举,它负责把每个Master节点加入到选举的Group中(作为/mesos目录下的一个子节点),组中每个节点都会有一个序列号,根据上文对ZooKeeper选举机制的介绍,组中序列号最小的节点将被选举为Leader。
以上文例子为例(假设作者部署了三个节点的Mesos master),可以查看ZooKeeper的存储来加以验证。
登录到ZooKeeper集群中的某一个节点,执行如下命令链接到集群中的某个节点,查看这个Group:
# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES a6fab50e2689 mesoscloud/zookeeper "/entrypoint.sh zkSer" 50 minutes ago Up 49 minutes zookeeper # docker exec -it a6fab50e2689 /bin/bash # cd /opt/zookeeper/bin/ # ./zkCli.sh -server 9.111.255.10:2181 [zk: 9.111.255.10:2181(CONNECTED) 0] ls /mesos [json.info_0000000003, json.info_0000000004, json.info_0000000002, log_replicas]
我们可以看到在/mesos目录下有三个带有后缀序号的子节点,序号值最小的节点将作为master节点,查看序号最小的节点json.info_0000000002的内容如下:
[zk: 9.111.255.10:2181(CONNECTED) 1] get /mesos/json.info_0000000002 {"address":{"hostname":"gradyhost1.eng.platformlab.ibm.com","ip":"9.111.255.10","port":5050},"hostname":"gradyhost1.eng.platformlab.ibm.com","id":"93519a55-4089-436c-bc07-f7154ec87c79","ip":184512265,"pid":"master@9.111.255.10:5050","port":5050,"version":"0.28.0"} cZxid = 0x100000018 ctime = Sun May 22 08:42:10 UTC 2016 mZxid = 0x100000018 mtime = Sun May 22 08:42:10 UTC 2016 pZxid = 0x100000018 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x254d789b5c20003 dataLength = 264 numChildren = 0 根据查询结果,当前的Mesos master节点是
gradyhost1.eng.platformlab.ibm.com。
Detector模块用来感知当前的master是谁,它主要利用ZooKeeper中的watcher的机制来监控选举的Group(/mesos目录下的子节点)的变化。ZooKeeper提供了getChildren()应用程序接口,此接口可以用来监控一个目录下子节点的变化,如果一个新子节点加入或者原来的节点被删除,那么这个函数调用会立即返回当前目录下的所有节点,然后Detector模块可以挑选序号最小的作为master节点。
每一个Mesos master会同时使用Contender和Detector模块,用Contender进行master竞选。在master节点上使用Detector模块的原因是在Mesos的高可用集群中,你可以使用任意一个master节点的地址和端口来访问Mesos的WebUI,当访问一个Replica节点时,Mesos会把这个浏览器的链接请求自动转发到通过Detector模块探测到的master节点上。
其他的Mesos组件,例如Mesos Agent,Framework scheduler driver会使用Detector模块来获取当前的Mesos master,然后向它注册,当master发送变化时,Detecor模块会第一时间通知,它们会重新注册(re-register)。
由于IBM在Mesos社区的推动,在MESOS-4610项目中,Mesos Contender和Detector已经可以支持以插件的方式进行加载。现在Mesos社区官方仅支持用Zookeeper集群进行Leader选举,在支持了插件的方式加载后,用户可以实现自己的插件,用另外的方式比如选择用etcd(MESOS-1806)、consule(MESOS-3797)等集群进行Leader选举。
注意:现在Mesos仅用ZooKeeper进行Leader的选举,并没有用它进行数据的共享。在Mesos中有一个Replicated Log模块,负责进行多个master之间的数据共享、同步等。可以参考Mesos的官方文档获取详细的设计 http://mesos.apache.org/documentation/latest/replicated-log-internals/ 。同时为了使Mesos的高可用不依赖与一个第三方的集群,现在社区正在考虑用Replicated log替代第三方集群进行Leader选举,具体进度可以参考MESOS-3574项目。
Mesos master recovery在Mesos设计中,master除了要在Replicated log中持久化一些集群配置信息(例如Weights、Quota等),0集群maintenance的状态和已经注册的Agent的信息外,基本上被设计为无状态的。master发生failover,新的master选举出来之后:
它会首先从Replicated log中恢复之前的状态,目前Mesos master会从Replicated log中recover以下信息。
1.Mesos集群的配置信息,例如weights,quota等。这些配置信息是Mesos集群的管理员通过HTTP endpoints来配置的。
2.集群的Maintenance信息。
3.之前注册的所有的Agent信息(SlaveInfo)。同时master会为Agents 的重新注册(re-register)设置一个超时时间(这个参数通过master的slave_reregister_timeout flag进行配置,默认值为10分钟),如果某些Agents在这个时间内没有向新master重新注册,将会从Replicated log中删除,这些Agents将不能以原来的身份(相同的SlaveId)重新注册到新的Mesos master,其之前运行的任务将全部丢失。如果这个Agent想再次注册,必须以新的身份。同时为了对生产环境提供安全保证,避免在failover之后,大量的Agents从Replicated log中删除进而导致丢失重要的运行任务,Mesos master提供了另外一个重要的flag配置recovery_slave_removal_limit,用来设置一个百分比的限制,默认值为100%,避免过多的Agents在failover之后被删除,如果将要删除的Agents超过了这个百分比,那么这个Mesos master将会自杀(一般的,在一个生产环境中,Mesos的进程将会被Systemd或者其他进程管理程序进行监管,如果Mesos服务进程退出,那么这个监管程序会自动再次启动Mesos服务)。而不是把那些Agents从Replicated log中删除,这会触发下一次的failover,多次failover不成功,就需要人为干预。
另外,新的Mesos master选举出来之后,所有之前注册的Mesos agents会通过detector模块获取新的master信息,进而重新注册,同时上报它们的checkpointed资源,运行的executors和tasks信息,以及所有tasks完成的Framework信息,帮助新master恢复之前的运行时内存状态。同样的原理,之前注册的Framework也会通过detector模块获取到新的Master信息,向新master重新注册,成功之后,会获取之前运行任务的状态更新以及新的offers。
注意:如果在failover之后,之前注册并且运行了任务的Frameworks没有重新注册,那么它之前运行的任务将会变成孤儿任务,特别对于哪些永久运行的任务,将会一直运行下去,Mesos目前没有提供一种自动化的机制来处理这些孤儿任务,比如在等待一段时间之后,如果Framework没有重新注册,则把这些孤儿任务杀掉。现在社区向通过类似Mesos Agents的逻辑,来持久化Framework info,同时设置一个超时的配置,来清除这些孤儿任务。具体可以参见MESOS-1719。
Mesos Agent健康检查Mesos master现在通过两种机制来监控已经注册的Mesos Agents健康状况和可用性:
1.Mesos master会持久化和每个Agent之间的TCP的链接,如果某个Agent服务宕机,那么master会第一时间感知到,然后:
1-1. 把这个Agent设为休眠状态,Agent上的资源将不会再offer给上层Framework。
1-2. 触发rescind offer,把这个Agent已经offer给上层Framework的offer撤销。
1-3. 触发rescind inverse offer,把inverse offer撤销。
2.同时,Mesos master会不断的向每一个Mesos Agent发送ping消息,如果在设定时间内(由flag.slave_ping_timeout配置,默认值为15s)没有收到对应Agent的回复,并且达到了一定的次数(由flag. max_slave_ping_timeouts 配置,默认值为5),那么Mesos master会:
2-1. 把这个Agent从master中删除,这时资源将不会再offer给上层的Framework。
2-2. 遍历这个Agent上运行的所有的任务,向对应的Framework发送TASK_LOST状态更新,同时把这些任务从master删除。
2-3. 遍历Agent上的所有executor,把这些executor删除。
2-4. 触发rescind offer,把这个Agent上已经offer给上层Framework的offer撤销。
2-5. 触发rescind inverse offer,把inverse offer撤销。
2-6. 把这个Agent从master的Replicated log中删除。
Mesos Framework健康检查同样的原理,Mesos master仍然会持久化和每一个Mesos Framework scheculer之间的TCP的连接,如果某一个Mesos Framework服务宕机,那么master会第一时间感知,然后:
1.把这个Framework设置为休眠状态,这时Mesos master将不会在把资源offer给这个Framework 。
2.触发rescind offer,把这个Framework上已经收到的offer撤销。
3.触发rescind inverse offer,把这个Framework上已经收到的inverse offer撤销。
获取这个Framework注册的时候设置自己的failover时间(通过Framework info中的failover_timeout参数设置),创建一个定时器。如果在这个超时时间之内,4.Framework没有重新注册,则Mesos master会把Framework删除:
4-1. 向所有注册的Slave发送删除此Framework的消息。
4-2. 清除Framework上还没有执行的task请求。
4-3. 遍历Framework提交的并且正在运行的任务,发送TASK_KILLED消息,并且把task从Mesos master和对应的Agent上删除。
4-4. 触发rescind offer,把这个Framework上已经收到的offer撤销。
4-5. 触发rescind inverse offer,把Framework上已经收到的inverse offer撤销。
4-6. 清除Framework对应的role。
4-7. 把Framework从Mesos master中删除。
未来展望从我个人的角度看,Mesos高可用这个功能应该做如下增强。
1.现在的设计中,Mesos的高可用必须依赖一个外部的ZooKeeper集群,增加了部署和维护的复杂度,并且目前这个集群只是用来做Leader选举,并没有帮助Mesos master节点之间存储和共享配置信息,例如Weights、Quota等。社区现在已经发起了一个新项目MESOS-3574,将研究和实现用Replicated log来替代ZooKeeper,帮助Mesos master选举和发现Leader。个人认为价值比较大,它实现之后,可以大大简化Mesos高可用架构的复杂度。
2.现在ZooKeeper作为搭建Mesos高可用集群的唯一选择,可能在比较大的集成系统中不合时宜,在IBM工程师的推动下,社区已经将和Mesos高可用的两个模块Contender和Detector插件化,用户可以实现自己的插件来进行Mesos master的选举和发现,已经实现了对etcd的支持。感兴趣的同学可以参考MESOS-1806项目。
3.另外,Mesos现在这个高可用的设计采用了最简单的Active-standby模式,也就是说只有当前的Mesos master在工作,其他的candidate将不会做任何事情,这会导致资源的浪费。另外在特别大的Mesos集群中,master candidates并不能提供负载均衡。未来是不是可以考虑将Mesos高可用修改为Active-Active模式,比如让master candidates可以帮助处理一些查询的请求,同时可以帮助转发一些写请求到当前的master上,来提高整个集群的性能和资源利用率。
正文到此结束
- 本文标签: CTO REST http 虚拟化 node tar UI TCP 插件 ask mysql 端口 配置 时间 Docker src IBM 负载均衡 sql 需求 json client Hadoop js zookeeper SDN Document Uber root https 安全 遍历 同步 executor web ip 集群 API Kubernetes 参数 ORM apache 自动化 cat 管理 程序员 快的 删除 目录 db 进程 数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

