如何在分布式实时计算框架 Storm 中调用 ODM 规则运算
分布式实时计算框架 Storm 简介
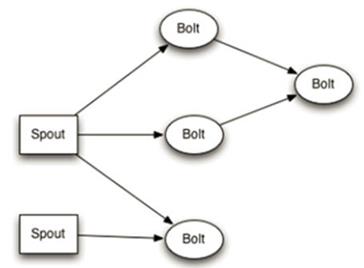
Storm 是目前流行的分布式实时流计算框架之一,它提供了可容错分布式计算所要求的基本需求和保障机制,可以满足高吞吐 , 实时的关键业务应用的需求。在编写基于 Storm 的分布式计算应用时,我们首先需要创建一个拓扑(Topology), 拓扑是一个由 Spout 节点和 Bolt 节点构成的有向图,其中 Spout 节点负责采集数据并发射数据流到 Storm 集群,Bolt 节点负责从 Spout 节点或其他 Bolt 节点接收数据流,并进行业务处理。在编写基于 Storm 的分布式应用时,我们可以在 Bolt 节点中调用 ODM 规则集,从而将业务规则相关的逻辑和数据采集以及数据流的控制分离开来,在业务发生变更时,我们可以动态的重新部署新的规则集,而不是重新发布并运行整个 Storm 拓扑。
图 1. Storm 拓扑
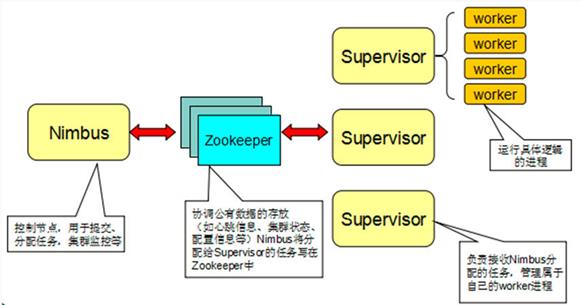
在编写好 Storm 拓扑后,我们需要将 Storm 应用打包成一个 Uber Jar( 也称为 Fat Jar, 即将所有的依赖类库打包到一起发布),并提交到 Storm 集群上运行,Storm 集群由 Nimbus 节点和 Supervisor 节点构成,其中 Nimbus 节点负责将应用代码(Uber Jar)分发给 Supervisor 节点 , 指派任务,并监控任务的执行。Supervisor 节点负责监听从 Nimbus 节点分配来的任务,启动工作进程来运行相应的任务。Supervisor 节点和 Nimbus 节点通过 zookeeper 来进行通信。
图 2. Storm 集群
ODM 规则集调用方式简介
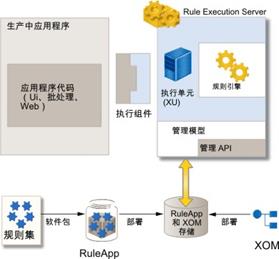
Rule Execution Server (RES) 是 IBM ODM 产品在分布式环境中管理和执行规则集的组件。RES 可作为集中式服务部署,从而响应多个客户机的请求并同时执行多个规则集。它提供的多种规则执行组件,让用户可以选择合适的执行模式,将业务规则管理系统集成到企业应用中。RES 基于模块化的体系结构,使它即可以作为一组 Java SE POJO 对象来部署和运行,又可以在完全兼容 Java EE 的应用程序服务器上部署和运行。它将规则引擎封装为一个 JCA 资源适配器——执行单元 (XU) 资源适配器,在应用程序服务器与规则引擎之间实施 JCA 交互,由 XU 资源适配器来管理规则引擎,加载规则集,并在业务应用和规则引擎间传递业务规则的调用参数和执行结果。
图 3. RES 组件结构
根据规则执行单元 XU 的部署方式,可以将规则调用分成基于 J2EE 的调用方式和基于 J2SE 的调用方式两大类:
- 基于 J2EE 的调用方式是指将 XU 作为独立的资源适配器,安装到应用服务器上,由应用服务器去管理 XU 的资源池,客户端采用 ODM 产品提供的 J2EE 规则执行组件(jrules-res-session, jrules-res-session-ejb3, jrules-res-session-mdb 等)创建规则会话,进行规则的本地或远程调用(其中 jrules-res-session 组件仅支持 POJO 规则会话的本地调用)。
- 基于 J2SE 的调用方式是指将 XU 作为类库打包到本地应用中,由业务应用自己管理 XU 的创建和资源池 , 并创建 J2SE 规则会话,调用规则集。
除了基于 J2EE 和 J2SE 的两种调用方式外,ODM RES 还提供了一个规则决策服务 (Decision Service) 应用,用户可以通过 Decision Service 用 SOAP 方式或 REST 方式调用规则集。
在 Storm 中调用规则集时,客户端代码运行在 Storm 的工作节点 JVM 中,因此能选择的规则调用方式有:
- 基于 J2EE 的 EJB 远程调用
- MDB 异步消息规则调用
- Decision Service 调用
- 基于 J2SE 的规则调用
前三种方式要求将规则执行单元 XU 安装到独立的应用服务器上,当规则执行成为 Storm 实时计算的瓶颈时,我们只能垂直或水平的扩展运行 ODM RES 的应用服务器,并且无论是 EJB 远程调用,MDB 异步消息调用还是 Decision Service 调用,都需要访问位于外部网络的应用服务器,网络延时可能会影响 Storm 实时处理的能力。
在 Storm 中使用 J2SE 规则会话调用规则集
在 Storm 中调用规则集的一个比较好的方式是使用基于 J2SE 的规则会话,采用这种调用方式,每个 Storm Executor 会初始化自己的 XU 实例,进行规则运算。规则运算也成为了 Storm 拓扑的一部分,而不是依赖运行于外部网络的 RES 服务器集群。接下来我们将通过 ODM Getting Started 的 miniloan sample 为例,演示一下如何在 Storm 中用 J2SE 规则会话的方式调用的规则集。
- 创建一个 Storm Java 项目,并将 ODM 安装目录 executionserver/lib 中的下列 jar 加入到项目的 classpath 中 :
- 规则引擎相关 : asm-*.jar,bcel-*.jar,jdom-*.jar,dom4j-*.jar,log4j-*.jar, openxml4j-*.jar, jrules-engine.jar
- RES 相关:j2ee_connector-*.jar,slf4j*.jar ,mina*.jar,jrules-res-execution.jar
- 将 ODM 安装目录 executionserver/bin 中的 XU 配置文件 ra.xml 添加到项目的源代码路径中,并对项目中的 ra.xml 做如下定制化:
- 将 XU 的 traceLevel 设成 WARNING
- 设置 XU persistenceType 和 persistenceProperties 属性,在生产环境中,我们推荐 persistenceType 设为 jdbc, 并根据规则数据库信息,设置 persistenceProperties 属性,如:
<config-property-value> DRIVER_CLASS_NAME=com.ibm.db2.jcc.DB2Driver, URL=jdbc:db2://dbHost:50000/ODMDB, USER=dbUser, PASSWORD=dbPassword, XOM_PERSISTENCE_TYPE=jdbc, XOM_PERSISTENCE_DRIVER_CLASS_NAME=com.ibm.db2.jcc.DB2Driver, XOM_PERSISTENCE_URL=jdbc:db2://dbHost:50000/ODMDB, XOM_PERSISTENCE_USER= dbUser, XOM_PERSISTENCE_PASSWORD= dbPassword </config-property-value>
-
设置 XU 的 plugins 属性,支持规则集热部署,在 J2SE 的调用方式中,规则集的热部署通知方式为 TCP/IP, 除了在这里作如下设置外:
<config-property-value>
{pluginClass=Management,xuName=default,protocol=tcpip,tcpip.port=1883,tcpip.host=<RES_Console_Host>,tcpip.retryInterval=20}
</config-property-value>
还需要指定 RES 控制台的管理协议为 TCP/IP, 并重新部署 RES 控制台应用,具体配置详情参见 Configuring the Rule Execution Server EAR for TCP/IP management
- 编写规则数据流生产者 Spout, 通常是从消息队列中读取消息,并将结果作为数据流发射出去,为了便于演示,我们将直接随机产生数据流,作为规则执行 Bolt 的输入。
清单 1. RulesSpout.java
public class RulesSpout extends BaseRichSpout { SpoutOutputCollector _collector; @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { _collector = collector; } @Override public void nextTuple() { Random ran = new Random(); Borrower borrower = new Borrower("John", ran.nextInt(2000), ran.nextInt(100000)); Loan loan = new Loan(ran.nextInt(1000000), 12, 0.05); _collector.emit(new Values(borrower, loan)); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("borrower", "loan")); } } - 编写规则执行 Bolt,在 prepare 方法中初始化 J2SE Session Factory 和 J2SE 规则会话对象,在 execute 方法中去调用这两个对象的方法,执行规则运算,prepare 方法在 Bolt 执行时只会被调用一次,因此 J2SE Session Factory 和 J2SE 规则会话对象只会被创建一次,在以后的每次的规则计算时 (execute 方法 ) 都将重用这两个对象,为了便于演示,规则运算结果将直接打印出来,而不是作为数据流重新发射出去。
清单 2. RulesExecutionBolt.java
public class RulesExecutionBolt extends BaseRichBolt { private IlrJ2SESessionFactory factory; private IlrStatelessSession session; @Override public void prepare(Map conf, TopologyContext context, OutputCollector collector) { try { factory = new IlrJ2SESessionFactory(); session = factory.createStatelessSession(); } catch (IlrSessionCreationException e) { e.printStackTrace(); } } @Override public void execute(Tuple tuple) { Borrower borrower = (Borrower) tuple.getValueByField("borrower"); Loan loan = (Loan) tuple.getValueByField("loan"); Map<String,Object> rulesetParams = new HashMap<String, Object>(); rulesetParams.put("borrower", borrower); rulesetParams.put("loan", loan); Map<String,Object> result = executeRules(rulesetParams, "/miniloanruleapp/miniloanrules"); System.out.println(((Loan)result.get("loan")).getApprovalStatus()); } private Map<String,Object> executeRules(Map<String,Object> rulesetParams, String rulesetPath) { try { IlrSessionRequest sessionRequest = factory.createRequest(); sessionRequest.setRulesetPath(IlrPath.parsePath(rulesetPath)); sessionRequest.setForceUptodate(true); sessionRequest.setInputParameters(rulesetParams); IlrSessionResponse sessionResponse = session.execute(sessionRequest); return sessionResponse.getOutputParameters(); } catch (IlrSessionException rse) { rse.printStackTrace(); } catch (IlrFormatException rse) { rse.printStackTrace(); } return null; } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } } - 编写 Storm 拓扑,将数据流的采集和规则运算整合起来,在运行时我们可以根据实际情况决定数据采集节点和规则运算节点的数量,以及工作进程的数量,比较好的做法是:工作进程的数量 = 规则运算节点数量 = 数据采集节点数量 *N,这样 Storm 在分配任务时会保证每个工作节点上至少运行一个规则运算节点和 N 个数据采集节点,数据采集节点 Spout 发射的数据会优先发射到同一工作节点上的规则运算节点上,从而有效地降低整个 Storm 拓扑的网络开销。
清单 3. RulesTopology.java
public class RulesTopology { public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("ruleInput", new RulesSpout(), Integer.parseInt(args[0])); builder.setBolt("ruleExectuion", new RulesExecutionBolt(), Integer.parseInt(args[1])).localOrShuffleGrouping("ruleInput"); Config conf = new Config(); conf.setNumWorkers(Integer.parseInt(args[2])); if (args.length > 3) { StormSubmitter.submitTopology(args[3], conf, builder.createTopology()); } else { LocalCluster cluster = new LocalCluster(); cluster.submitTopology("test-minloan", conf, builder.createTopology()); } } } -
将 Storm 项目打包成 Uber Jar(minloan-toplogy.jar),并用如下的命令提交打包好的拓扑到 Storm 集群上:
storm jar minloan-toplogy.jar storm. RulesTopology 8 4 4 MiniloanTopology
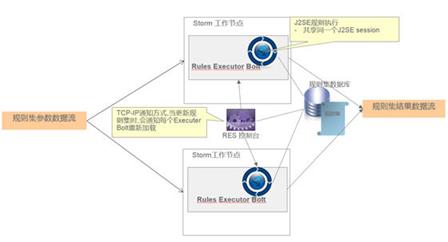
在提交成功后,我们可以通过 Storm UI 看到运行中的 MiniloanTopology 拓扑以及每个节点处理的吞吐量。在本例中,我们将拓扑提交到 4 个工作节点上,每个工作节点上会运行两个数据采集节点和一个规则运算节点,4 个规则运算节点从同一个规则数据库加载规则集。在业务逻辑发生变更后,业务人员可以直接在 Decision Center 上修改业务规则,然后部署新的规则集到 RES 控制台,RES 控制台会通知每个 Storm 工作节点重新加载最新的规则集,而不需要重新部署整个 Storm 拓扑。
图 4. ODM Rule Execution in Storm
小结
Storm 提供了一个简单的编程模型,让我们能够快速的开发实时的分布式应用,将 Storm 和 ODM 结合起来,我们可以方便的使用 Storm 提供的数据采集框架,从 Kafak 等开源消息队列中采集数据,然后采用 J2SE 的方式调用 ODM 规则集,这样可以很好的支持大批量实时的规则调用需求,并能根据业务需求,动态的扩展规则计算节点的数量。
正文到此结束
- 本文标签: 数据库 企业 Service UI 目录 App db 参数 集群 http SOA 协议 实例 tar Uber Property 配置 CTO db2 REST cat src executor 管理 服务器 DOM Developer 安装 Persistence TCP IBM value 产品 lib plugin IDE web parse ip 开源 map ACE 需求 classpath XML 进程 build ORM 数据 java HTML mina 开发 zookeeper Word 代码 定制 消息队列
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

