10年资深架构师谈Linux上容器背后的虚拟化解决方案
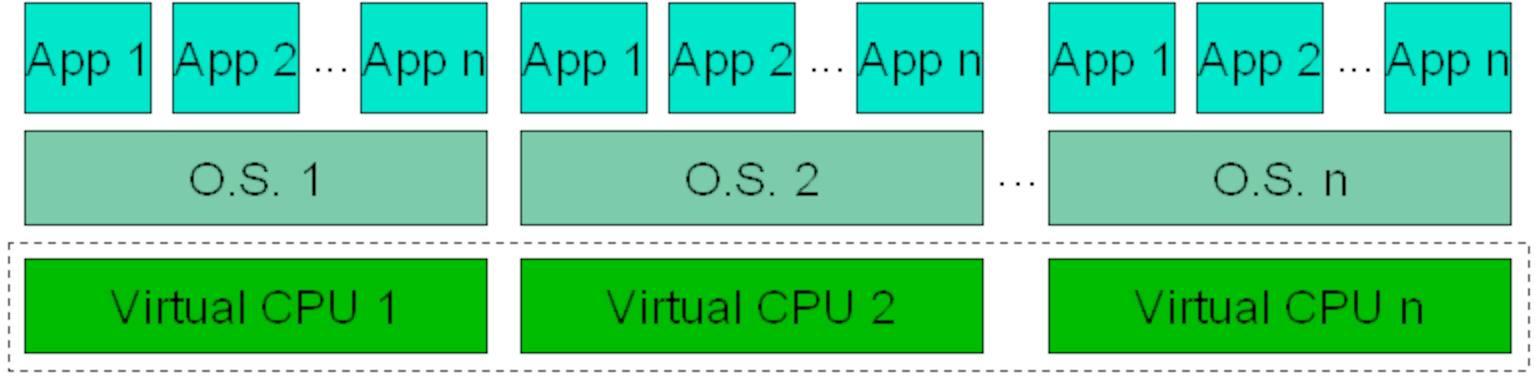
目前主流的虚拟化技术有类似Intel VT这样的纯粹底层硬件虚拟化技术,也有类似Xen这样的半虚拟化技术,它并不是一个真正的虚拟机,而是相当于自己运行了一个内核的实例,可以自由的加载内核模块,虚拟的内存和IO,稳定而且可预测。
也有kvm这样的完全虚拟化技术,所有的kvm类型的虚拟技术都可以装各种linux的发行版和各 种win的发行版,当然,还有最近比较流行的容器类技术,例如lxc,docker都是基于操作系统之上的进程级别的隔离技术, 本次分享主要围绕上层的虚拟化技术来剖析Linux上的解决方案。
1cpu vt技术
为解决纯软件虚拟化解决方案在可靠性、安全性和性能上的不足很多cpu都引入了硬件虚拟化的技术,比如Intel在它的硬件产品上引入了Intel VT(Virtualization Technology,虚拟化技术)。
Intel VT可以让一个CPU工作起来像多个CPU在并行运行,从而使得在一部电脑内同时运行多个操作系统成为可能。
Intel提供了:
- Cpu虚拟化
- 内存虚拟化
- I/O虚拟化
- 图形卡虚拟化
- 网络虚拟化
等功能,本章主要还是介绍上层软件相关的虚拟化技术,不再过多阐述这块内容,有兴趣大家也可以通过访问:http://www.intel.com/content/www/us/en/virtualization/virtualization-technology/intel-virtualization-technology.html来了解Intel VT相关的技术。
2chroot分析
chroot是内核提供的一个系统调用,从安全性的角度考虑,来限定用户使用的根目录,ch在经过 chroot 之后,系统读取到的目录和文件将不在是旧系统根下的而是新根下(即被指定的新的位置)的目录结构和文件,它的作用如下:
- 增加了系统的安全性,限制了用户的权力
- 建立一个与原系统隔离的系统目录结构,方便用户的开发
- 切换系统的根目录位置,引导 Linux 系统启动以及急救系统等
所以,很多容器技术都使用了chroot。
3chroot实现
下面我们来看下chroot系统调用的实现:
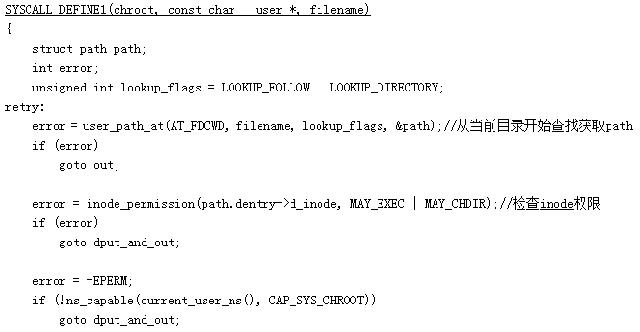

从上面的源码可以发现chroot的逻辑其实非常简单,先是通过user_path_at函数搜索路径获取该filename的path,然后通过set_fs_root把当前进程的文件系统的root设置为path。
4cgroup分析
介绍
cgroups(Control Groups)最初叫Process Container,由Google工程师(Paul Menage和Rohit Seth)于2006年提出,后来因为Container有多重含义容易引起误解,就在2007年更名为Control Groups,并被整合进Linux内核。可以理解为把进程放到一个组里面统一加以控制。
cgroups可以限制、记录、隔离进程组所使用的物理资源(包括:CPU、memory、IO等)。
使用方法

当我们创建文件夹后,自动生成的文件如下:
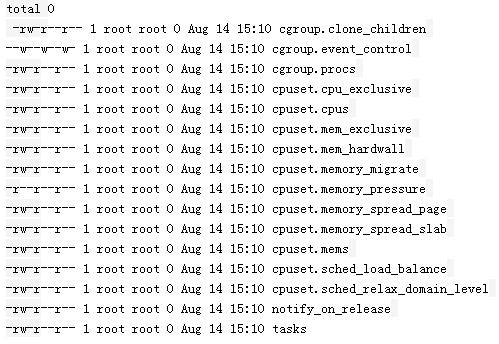
设置task允许使用的cpu为0-1:
echo 0-1 > cpuset.cpus
添加task到cgroup:
echo [pid] >> tasks
这样就可以对指定pid的进程限制使用的cpu仅为0和1。
体系结构
接下来我们介绍一下cgroup的整体架构:
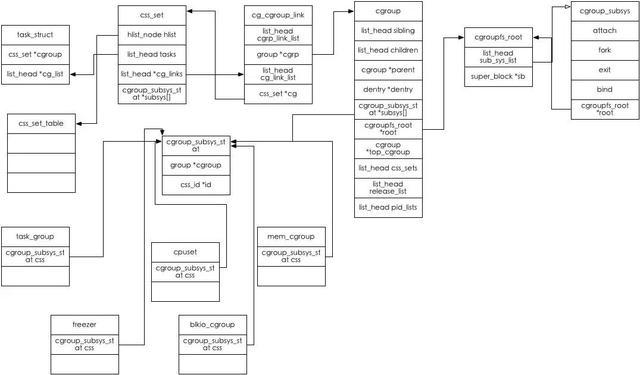
由上图,我们来简单介绍一下cgroup的主要概念:
- cgroupfs_root: 可以理解为我们mount操作指定的dir目录。
- css_set: 提供了与进程相关的cgroups信息.其中cg_links 指向一个由 struct_cg_cgroup_link 连成的链表。Subsys 是一个指针数组,存储一组指向 cgroup_subsys_state 的指针。一个 cgroup_subsys_state 就是进程与一个特定子系统相关的信息。通过这个指针数组,进程就可以获得相应的 cgroups 控制信息了。
- css_set_table: css_set_table保存了所有的css_set,hash函数及key为css_set_hash(css_set->subsys)
- hierarchy: 层级,cgroup可以组织成 hierarchical 的形式,既一颗cgroup树。group树上的子节点cgroup是父节点cgroup的孩子,继承父cgroup的特定的属性。
- cgroup: 可以理解为在mount目录下mkdir新建的目录。cgroups 中的资源控制都以cgroup为单位实现。cgroup表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个cgroup,也可以从某个cgroup迁移到另外一个cgroup。
- cg_group_link: 由于cgroup和css_cet之间是多对多的关系,cg_group_link是用来关联这两者的。一个css_set为什么会有多个cgroup?——其根本的原因在于一个task会被attach到多个hierarchy,并且在每个hierarchy下的必有一个cgroup管理着该task(一个task只有一个css_set),所以有几个hierarchy该css_set就有几个cgroup。一个cgroup为什么会有多个css_set?——因为一个cgroup可以attach多个进程,而这些进程它们的css_set可能不一样,这个由该task所属的cgroups决定,只有所属的cgroups完全一样,它们才会共享一个css_set,否则的话,它们的css_set就不一样。
- cgroup_subsys: 代表cgroup的某个子系统,它代表了某个子系统如何注册到cgroup或者销毁的过程:

上面的代码罗列了cgroup_subsys接口的钩子函数。
- cgroup_subsys_state: 代表每个子系统真正的控制结构,图中的cup,cupset,blkio_group等都是它的实现,也就是说,每个子系统对系统资源的限制就是通过cgroup_subsys_state的实现来完成的。
task和cgroup的关系:
css_set->tasks是所有引用该css_set的tasks的list的head,task之间用task->cg_list进行链接,一个cgroupfs_root的所有cgroup_subsys由cgroupfs_root->subsys_list组织;所有的cgroupfs_root通过它的root_list连接到roots这个全局变量头里。
从某种角度上来讲,cgroup的这个结构,有点像业务系统中的权限系统。
5cgroup文件系统
cgroup是通过标准的vfs接口方式提供给上层交互的,每当我们mount或者mkdir时候,目录下面的文件就是通过cgroup自己创建的,这些文件定义方式如下:
全局cgroup.c中:


子系统也维护了各自的files文件,比如cpuset:



以cgroup.procs文件的写操作为例:


这个写入的过程最终通过cgroup_attach_task把cgroup下的subsys attach到该task中。
- 创建cgroup
创建一个新的cgroup也是通过标准的vfs操作来执行的,在cgroup中定义了cgroup文件系统的一些操作:

创建cgroup是通过mkdir来创建的:





以上过程先为该cgroup所属的每个subsys创建一个cgroup_subsys_state,并初始化。
通过该cgroup->subsys可以获得该cgroup的所有cgroup_subsys_state,同样通过cgroup_subsys_state->cgroup可以知道该cgroup_subsys_state所属的cgroup。以后cgroup与subsys的group控制体的转换都是通过该结构来完成。
这里并没有建立css_set与该cgroup的关系,因为mkdir时该cgroup还没有attach任何进程,所以也不会有css_set与它有关系。
- attach task
attach task的过程是由cgroup_attach_task函数来完成的:

它的执行过程总共分为3步:
1、 cgroup_migrate_add_src从task的css_set中找到dst_cgrp相关的hierarchy,它通过调用cset_cgroup_from_root来找到src_cset指定dst_cgrpc层级下的cgroup:

2、cgroup_migrate_prepare_dst,通过find_css_set查找一个已经存在的css_set或者创建一个新的,首先通过find_existing_css_set查找是否有一个可用的css_set,否则,创建一个新的css_set,并且建立新的css_set与该task之前旧的css_set的所有关联的cgroup的关系,再把该新的css_set加入到哈希表hlist:


3、cgroup_migrate,进行真正的attach工作:
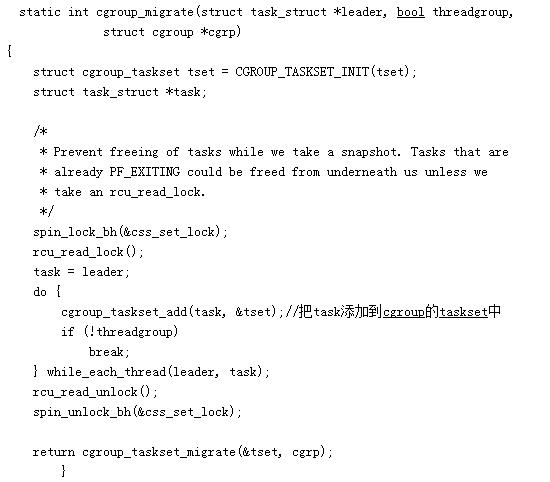
cgroup_taskset_migrate,先判断该task是否可以在所有subsys上can_attach,然后进行attach:



- cpuset 子系统
如果是多核心的cpu,这个子系统会为cgroup任务分配单独的cpu和内存。
这里我们简单分析对cpuset.cpus文件的操作:

在files数组中定义了write操作的函数是cpuset_write_resmask:


针对FILE_CPULIST的场景,由update_cpumask更新cpu对应的mask:


最终的目的就是在于更新该cgroup下的每个进程的cpus_allowed.
然后在下次task被唤醒的时候,select_task_rq_fair选择cpu_allowed里的某一个cpu,可能是load最低的)来确定它应该被置于哪个CPU的运行队列及运行,一个进程在某一时刻只能存在于一个CPU的运行队列里。
6Namespace分析
Cgroup提供了资源限制的功能,namespace则提供了资源隔离的功能,它提供六种namespace隔离功能:
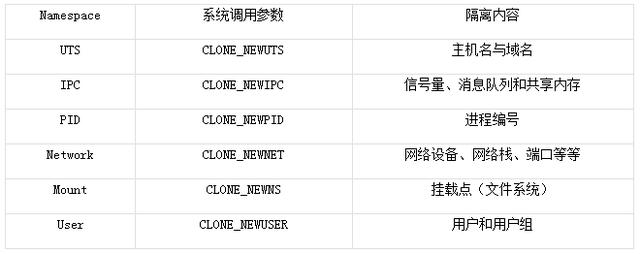
隔离后每个namespace看上去就像一个单独的Linux系统。

一个进程可以属于多个namesapce,在task_struct 结构中有一个指向namespace结构体的指针nsproxy:

假如不指定ns,那么默认所有的进程创建的时候,都会指定一个默认的ns:

如果想要手动指定自己的ns,那么可以通过clone函数传入参数来实现。
Clone函数执行的过程中会调用do_fork->copy_process->copy_namespaces->create_new_namespaces:


在创建完独立的ns后,以分配pid为例:

pid将会在其独立的ns中进行分配。
7lxc介绍
当我们了解完chroot,cgroup,namespace这些概念后,lxc其实是基于这些东西的封装,提供了一套软件包,来帮我们创建容器,我们可以粗略的认为LXC = Cgroup+ namespace + Chroot + veth +用户态控制脚本。
- docker 和虚拟化分析
docker在0.9.0之前的版本,是直接通过LXC来创建虚拟化容器的。目前docker自己维护了libcontainer来进行容器的管理。
下面摘录部分片段:
创建networknamespace:
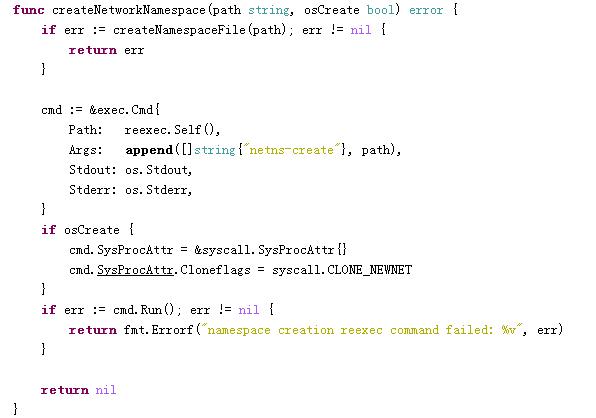
cgroup和相关限制的资源定义:




8其他
除了以上提到的进程资源隔离和限制的轻量级虚拟化解决方案外,Linux还提供了像KVM这样的全虚拟化解决方案:
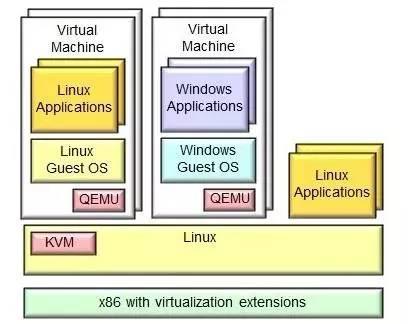
KVM是Kernel-based Virtual Machine的缩写,这是一个针对X86上的Linux完全虚拟化硬件解决方案,它可以基于Intel VT 和AMD-V这两种不同厂商的解决方案来实现。
您可以很容易地运行多个虚拟机运行Linux或windows镜像,每个虚拟机都有自己的单独的虚拟私人硬件;它包含一个磁盘,一个网卡,一个图形适配器等等。KVM实际上是一个开源的软件解决方案。
Q&A
Q1:虚拟化应该会带来一些系统性能损耗,在硬件虚拟化,半虚拟化,kvm完全虚拟化,docker等,老师有没有一些数据可供参考?
A1:理论上肯定是硬件虚拟化性能最好的。目前kvm已经在很多公司生产环境上跑了,我也在河狸家的生产环境上跑着kvm,目前支撑生产环境问题不大。docker只是一个进程级别的隔离,理论上对性能是不会有大的影响的,不过docker的主要问题还是网络上面,比如跨容器之间的通信,使用类似vxlan这样的技术,我测试了下性能至少损失30%。还有一种方法是建多个bridge,然后每个容器的veth和bridge挂钩。
Q2:虚拟化鼻祖开源的qemu用的是什么虚拟化技术?
A2:qemu是模拟器,底层还是调用了kvm,可以参考我最后发的那张kvm的架构图。
Q3:最近看Openstack,KVM是标准配置?
A3:openstack适合大集群的管理,像什么创业公司机器不多的话自己在libvert上涌python包一层管理都行,或者用apache下的cloud stack来管理。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

