从规则到模型-达达外卖排序算法简介
背景
2014年6月,达达配送上线,并迅速成长为国内最大的众包配送服务平台,为数十万商家提供低成本、高效率的配送服务。
2015年7月,为了更好地连接消费者和商家,达达推出了自己的外卖信息服务平台-派乐趣,实现了上游信息服务和下游配送服务的完整闭环。消费者可以通过派乐趣平台获取点餐、支付、配送、评价等一系列服务。成立以后,派乐趣经历了高速的增长,并在2015年底突破了一百万的日单量。
随着派乐趣入驻商家的快速增长,如何对附近的候选商户进行有效排序,帮助用户快速找到最适合自己的餐厅,成为派乐趣面临的一个核心问题。
商户排序问题
所有的信息平台在信息的展现过程中都会碰到排序问题。如何通过排序将更高质量的信息展现给用户,提供更好的用户体验,是信息平台必须解决的一个问题。
和传统的搜索排序和电商排序相比,外卖平台的商户排序有着特殊的需求,需要考虑的因素包括:
- 距离因素 :外卖服务和电商、搜索等线上服务的一个主要区别是受地理因素的限制和影响。比如,商家有一定的配送范围,而用户也会倾向于选择附近的商家,以获得更快的配送体验。因此,对商户的检索、筛选和排序都需要考虑距离因素。
- 时段和品类 :不同时间段用户对外卖的需求是不同的。比如中午12点和晚上6点左右用户对于正餐的需求量是最高的,而在下午3点钟左右用户对饮料、甜品类的需求可能更大一些,这就要求排序算法考虑时间和品类等相关因素。
- 质量和评价 :线下服务的一个特殊之处在于服务的很大一部分是不可见的,例如餐品的口味、送达速度、服务态度等, 在排序的时候需要将这些不可见因素量化,并体现在排序中。
业界用于解决排序问题的主流手段是learning to rank方法。 learning to rank方法又可分为三类: pointwise、 pairwise和 listwise。
三种方法中, pairwise和listwise方法在搜索排序、文本检索等领域效果更佳。pointwise方法则被广泛应用于搜索广告、团购平台和外卖平台的排序问题中。在应用中, pointwise方法会对所有的候选结果给出一个统一标准的分值,并根据分值进行排序。 相比于另外两种算法, pointwise 方法比较容易和其它控制项叠加,适用于不单纯追求相关性或转化率,具有多维度优化目标的问题。
派乐趣的商户排序就是有着多维度优化目标的问题,不仅需要优化转化率,还涉及到新店保护、商户质量控制、距离控制等各种细节考虑。因此,我们采用pointwise方法来解决派乐趣的商户排序问题。
商户排序算法演变
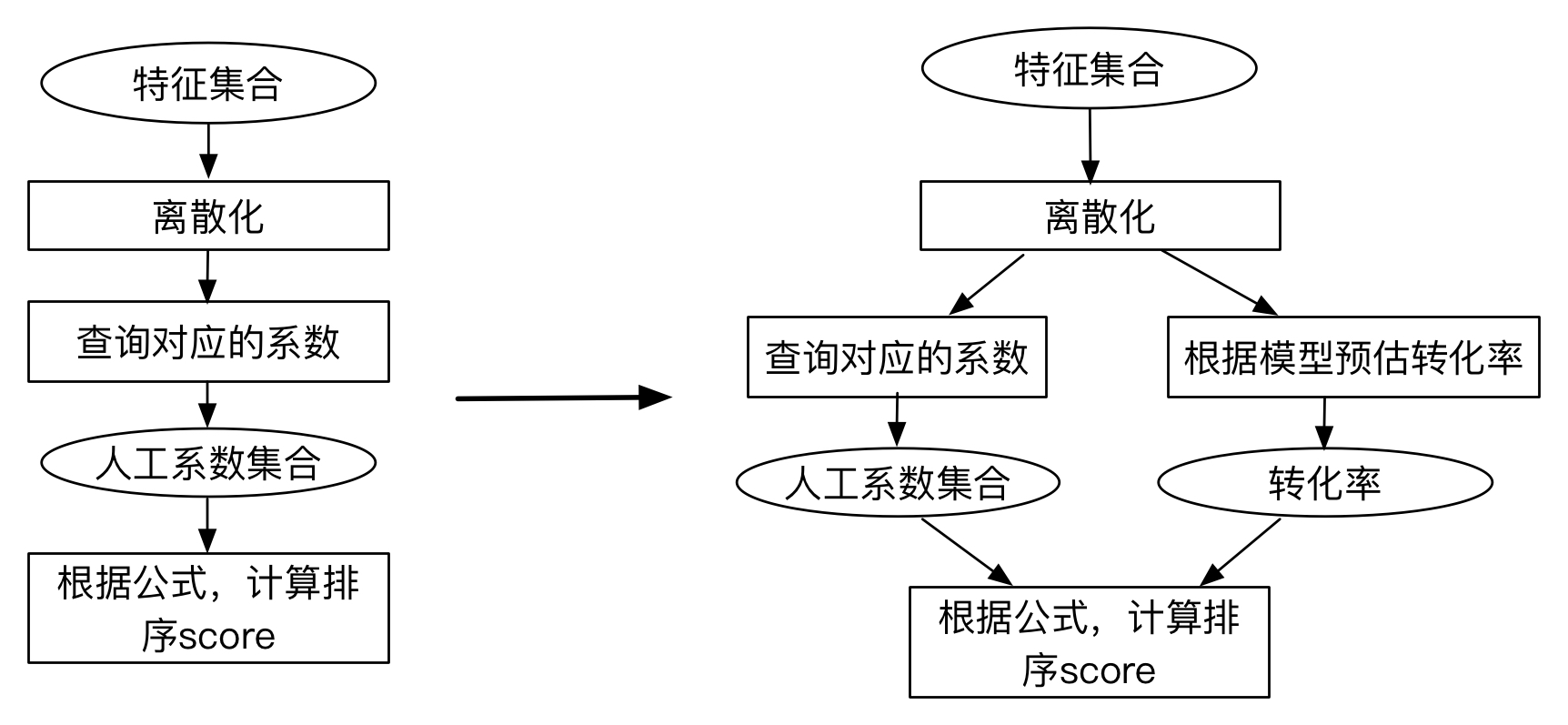
最早的时候,派乐趣使用人工制定的规则来对商户排序,主要是对距离、时段、品类、评分等特征进行离散化,针对不同的区间段人工设置不同的分值,根据一个公式计算出总的分值,对商户进行排序。采用人工规则的好处是:实现简单,解释性强,容易施加控制,没有冷启动的问题,比较适合业务早期数据不足时快速实现功能。
后来,随着业务的发展,对规则的维护和升级变得越来越复杂。同时,人工决定的规则无法保证完全合理,也无法捕捉到数据中的隐藏关联。为了解决这一问题,我们引入了转化率预估模型,对商户的转化率进行实时预估,将转化率和人工因子结合在一起,计算出一个组合分值,作为排序的依据。
基于转化率模型的商户排序算法
对于外卖平台来说,体现平台效率的核心指标是转化率,即访问平台的用户中下单的比例。我们的排序系统也是以此为主要目标进行优化: 我们希望针对每个用户,把转化率最高的商户排到最前面,从而提升系统整体的转化率 。为了保证准确性,转化率的预估考虑了用户、商户和上下文维度的多个特征。
同时,在排序的过程中,也需要考虑新商户保护、距离、优质商户优先等其它因素。这部分因素不一定和转化率直接相关,但是对于整个平台的健康发展至关重要,需要进行一定程度的特殊控制。因此, 我们将其设置成多个人工系数,和转化率一起作为排序的依据 。
综上,对于每个商户来说: 最终的排序score = 预估转化率 * 人工系数
转化率模型架构
我们使用基于离散特征的逻辑回归(logistic regression)模型来对转化率进行预估。主要原因是:
- 逻辑回归相对来说比较简单,可解释性较强
- 可以根据特征权重来判断特征的重要性,进行特征的筛选和增减
- 逻辑回归会输出一个连续的预估值,方便用于排序
- 使用离散特征可以方便地进行特征组合,使模型具有一定的非线性。
转化率模型的数据流主要分成两部分: 线下训练 和 线上预估 ,具体架构如下:
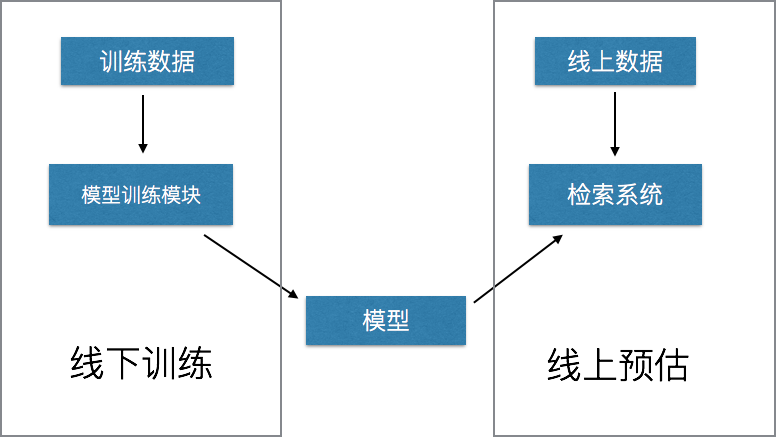
1. 线下训练模块
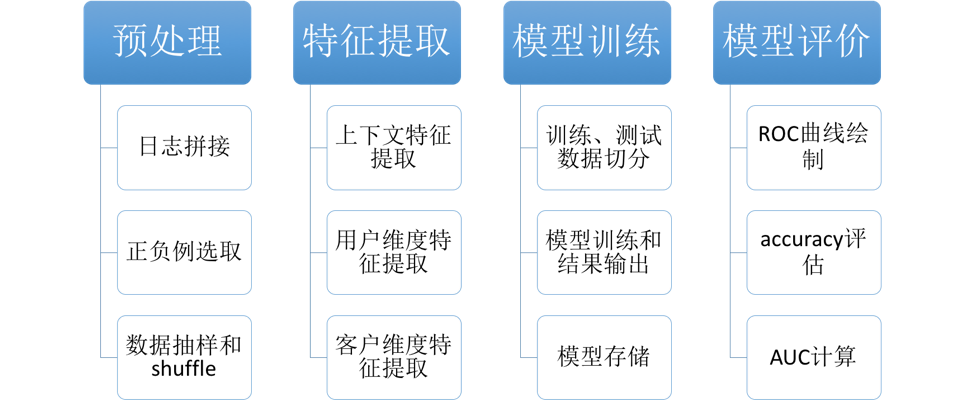
模型训练模块主要根据历史日志进行定期训练,获得预估模型,主要步骤为:
- 预处理 :主要涉及展现,点击和转化日志的拼接,以及正负例的抽样选取等。用于构建特征提取使用的基础数据
- 特征提取 :对上下文特征、用户维度特征和商户维度特征分别进行提取,并对提取结果进行合并
- 模型训练 :对训练和测试数据进行切分,使用训练数据进行模型训练,并将训练出的模型和特征映射存储到单独的文件中
- 模型评价 :使用测试数据对训练出的模型进行评价,主要包括ROC曲线的绘制,accuracy等指标的计算以及AUC的计算等。
2. 线上预估模块
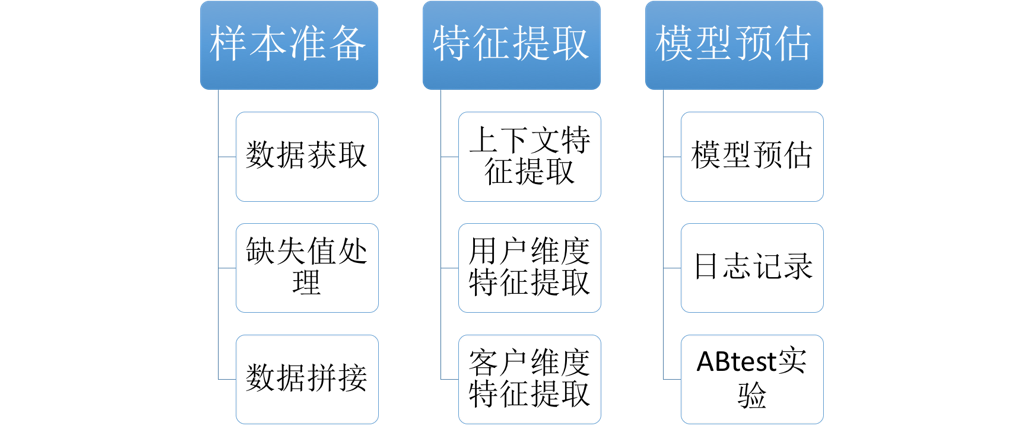
模型预估模块则会加载训练好的模型,用于线上的转化率预估,主要步骤为:
- 样本准备 :需要将线上的实时数据传入模型预测接口, 并进行拼接和缺失值处理
- 特征提取 :对上下文特征,用户维度特征和商户维度特征分别进行提取。
- 模型预估 :把特征提取的结果输入模型,获取预估的转化率,根据公式和人工系数计算出最终的排序score用于排序,并把结果记录在日志中。
排序算法的评估
排序算法的评估分成两部分:
- 线下评估 : 我们使用ROC曲线、AUC、accuracy等指标来评估模型的效果
- 线上评估 : 我们构建了用户级别的abtest框架,用来评估排序系统对转化率等线上指标的影响
ABtest实验结果显示,通过引入转化率预估模型,加上特征上的改进,相对于原有的规则排序,系统整体uv转化率有15%-20%的提升。
总结和展望
在构建排序算法的过程中,我们有了一系列的思考,总结如下:
- 使用规则还是模型 :成熟的系统中,应该是二者同时共存。通过规则来实现冷启动和快速的人工控制, 通过模型来对积累的数据进行细粒度刻画。
- 算法和特征哪个更重要 : 在项目前期,重要程度的排序是 工程 > 特征 > 算法。一开始最好选择简单、解释性强的算法,快速优化工程和特征。当工程搭建完成、效果稳定以后,再在算法上进行进一步优化。
- 离散特征vs连续特征 : 对于多数实际问题来说,无法拿到非常有用的连续特征。同时,使用离散特征比较容易进行特征组合,人工构造非线性特征。对于比较有用的连续特征,可以对其进行离散化以后使用。
- 什么样的特征更有用 : 我们发现,类似于广告中的重定向,引入用户的历史点击、购买行为对模型的预估效果有较大提升。此外,商户的历史点击率、转化率特征也比较重要。
以上是达达在商户排序中的一些实践和经验,我们最大的体会是:O2O领域在时间和空间上都有着更为严格的限制,对算法也提出了不同于传统线上算法的要求。
作为众包物流领域的领导者, 达达在供需检测、动态定价、路径规划、订单合并等方面正在进行不懈探索。我们也清楚的看到,这些领域隐藏着无数有趣的算法问题,等待我们去挑战。欢迎感兴趣的同学加入达达,和我们一起,在这一全新的算法领域里探索、学习和创新。
更多关于达达技术的文章,敬请关注达达技术公众号。

正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

