微信公众号爬虫
最近需要持续更新3w左右公众号的文章, 受技术leader的影响重新写了一下爬虫的一些代码, 效果不错, 写此文记录一下
前言
- 无论是新方案还是旧方案, 获取公众号文章列表, 获取阅读点赞, 获取评论等接口可以通过抓包来获取
- 以上接口都是需要授权的, 授权参数主要有一下几个
- uin : 用户对于公众号的唯一ID, 本来是一个数字, 传的是base64之后的结果
- key : 与公众号和uin绑定, 过期时间大概是半小时
- pass_ticket: 另外一个验证码, 与uin进行绑定
- req_id: 在文章里HTML里, 每次请求会不一样, 用来构成获取阅读点赞接口的RequestBody, 一次有效
- 获取阅读点赞接口有频率限制, 测试的结果是一个微信号5分钟可以查看30篇文章的阅读点赞
旧方案
在2015年的时候微信网页版限制还是没那么严格的, 当时采用的主要思路是使用微信网页版, 然后用requests去模拟登陆一下,
然后不停的去访问类似下面的接口爬取信息:
https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxcheckurl?requrl=encodeURIComponent('http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5NzQ3ODAwMQ==#wechat_redirect')
当时为了能让爬虫多个实例跑, 用了一下 Celery 框架(现在想简直智障, 多个实例跑直接把程序启动N次就行了啊。。摔), 由于是模拟登陆, 所以又写了一套复杂的东西去生成二维码, 然后获取登陆URL, 具体的模拟登陆原理参考这个 wechat-deleted-friends , 另外相关的Celery Task里写的逻辑太复杂了, 一个Task里就带上了 requests断线重连机制, 模拟登陆机制, 解析列表, 解析文章等, 另外由于是web版微信有一套蛮复杂的sync机制, 有时候直接掉线需要再次的去手动登陆, 很是麻烦。
之后web版微信已经无法的获取Key了(2016年开始), 此方案就废弃了。。
新方案
经leader提醒, 改了一下架构, 其中项目的整体结构如下:
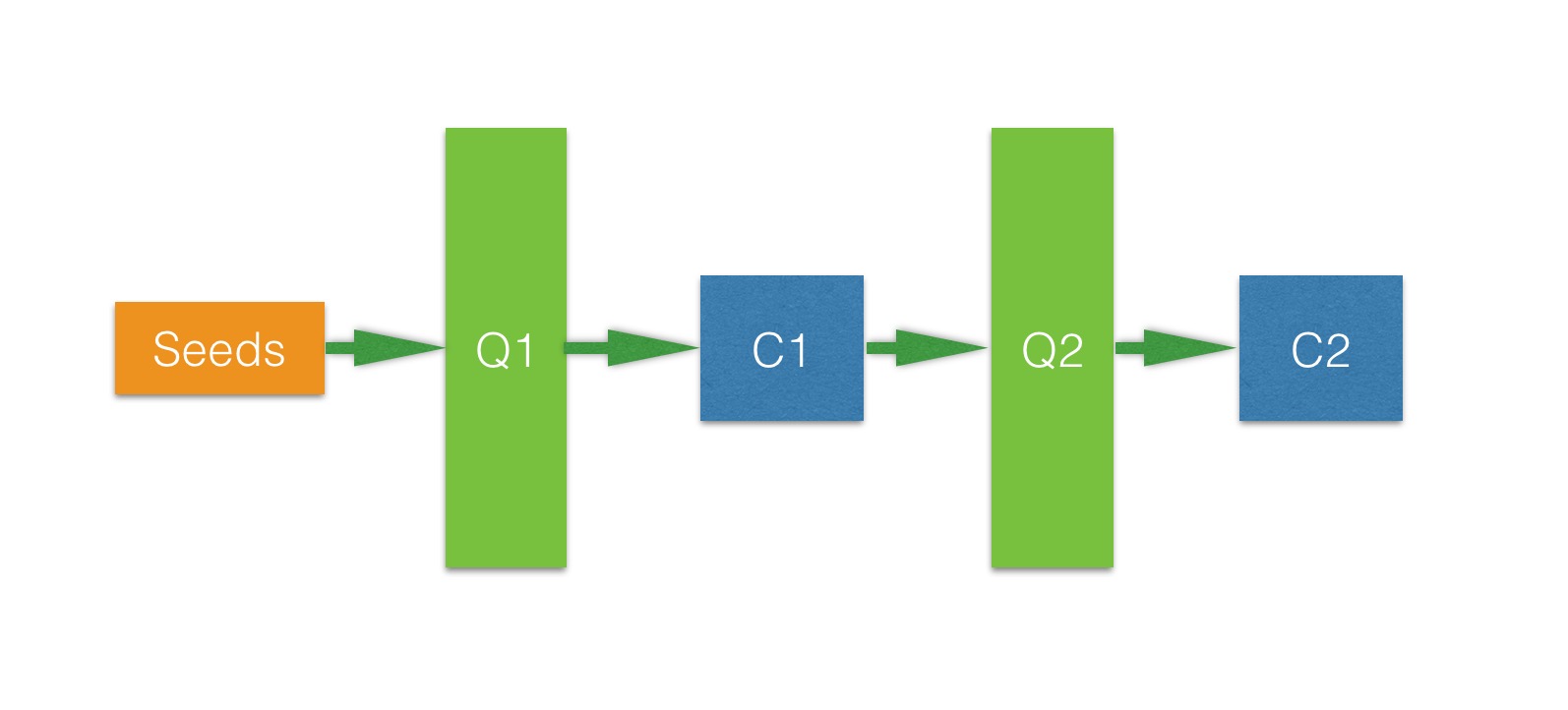
- Seeds 是一个producer, 在此处指通过某种方式获取 uin, key, pass_ticket 信息, 思路类似中间人攻击+解析squid日志
- Consumer C1从Q1队列中取出seeds后爬取某个公众号的文章列表, 解析后将文章Meta信息放入队列Q2
- Consumer C2获取文章原信息后就可以直接做入库&爬取操作了
- 之后可以继续加队列然后去实现爬取文章阅读点赞的相关数据了, 由于有频率限制。一个微信号一天只能最多获取8000篇文章的阅读点赞信息
- 抛弃了Celery和其默认选用的RabbitMQ队列, 这种东西实在太重了。。改用beanstalkd做消息队列
- 目前的效果是单微信号每日更新4w左右的公众号文章, 如果想继续增加数量可以通过加机器来扩展
Over
声明: 本文 “微信公众号爬虫” 采用 CC BY-NC-SA 4.0 协议进行授权.
转载请注明原文地址: http://stackbox.cn/2016-07-21-weixin-spider-notes/index.html
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

