腾讯Gaia平台的Docker应用实践
本文由 谢恒忠 根据2016年1月24日@Container容器技术大会·北京站上陈纯的演讲《 腾讯 Gaia平台的Docker应用实践》整理而成。
大家好,我是腾讯数据平台部的陈纯,今天非常高兴为大家介绍一下腾讯Gaia平台 Docker 实践。
首先我介绍一下Gaia平台。Gaia平台是腾讯数据平台部资源调度和管理的系统,承载公司的离线业务、实时业务以及在线设备service业务,最大单集群达到8800台,并发资源池个数达到2000个,服务于腾讯所有的事业群。
在2014年10月份我们正式上线对Docker类型的支持,通过Docker将Gaia云平台以更好用的方式呈现给各个业务。目前,Gaia平台已经服务于公司内部游戏云、广点通以及GPU深度学习等Docker类业务。
Gaia架构
下面我简要介绍一下Gaia架构。如下图:
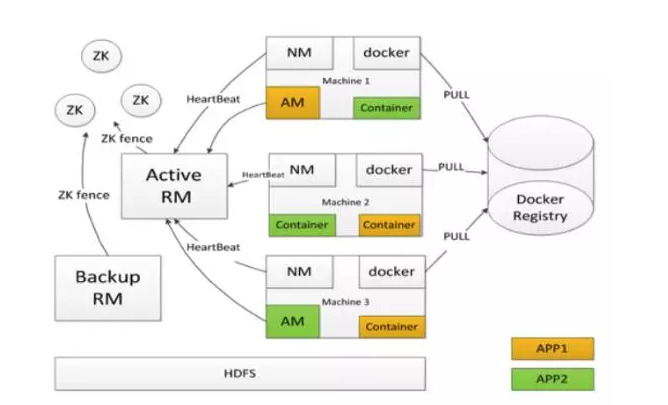
Gaia架构
Gaia其实是我们基于Hadoop的YARN改造的一个Docker的调度系统。
首先它相比社区的YARN有哪些特点呢?社区的YARN可能在RM、NM都已经实现了无单点的设计,可以热升级。在此基础之上,我们自研了一个AM,负责所有Docker类作业的调度。然后我们对AM以及Docker也进行了一定的改造,让它支持无单点的一个设计。右边的图中我们可以看到每个Slave节点上除了有NM之外,还有一个Docker进程,负责拉起所有的Docker作业,我们也实现了Docker的热升级。 除了对Master节点进行无单点改造之外,Gaia也为用户的APP提供了本地重试和跨机重试两种容灾方式。
第二点就是Gaia除了对CPU内存以及网络出带宽进行限制之外,还增加了对GPU和磁盘空间的隔离。
第三点是Gaia可以最大化的利用集群的所有资源,在保证用户最低资源使用量的情况下,在集群有空闲资源时还能借集群的空闲资源进行使用。
最后一点是我们自研的SFair调度器解决了调度器效率和扩展性的,目前调度器每秒最多可调度4K个Container实例。
当然我今天所演讲的主要内容并不是对Gaia进行分析,我今天演讲的内容主要是跟Docker相关的,因为我平常在组里面也是负责Docker的研发。
Docker热升级功能
Docker Daemon单点问题
首先我们来看一下Docker Daemon单点问题,相信所有使用Docker的人都会遇到这个问题。Docker Daemon在退出时会杀掉所有的Container,这一点对于在线服务来说完全不可接受。
其次Docker的坑也比较多,比如我们用的1.6.×版本:
第一个问题是我们遇到了Docker stats。Docker stats其实是用来监控Container实际使用资源的命令,当你的Container拉起来之后,用Docker stats监听这个Container使用资源,当Container被回收,Stop之后,Docker stats命令由于它没有正确的回收内存中的一些数据结构,会导致Docker Daemon crash,如果Docker Daemon crash,它就会把这个机器的所有Container都给杀掉。这个问题是我们遇到的,自己解决了,并且反馈到社区了。
第二个问题是Docker exec,Docker exec在Docker Daemon代码里面没有很好的做到同步,会引发一个NPE的异常,导致Docker Daemon crash。
第三个问题相信很多人都遇到过,在Docker 1.9.1版本之前,由于Container的stdout和stderr都会经过Docker Daemon进行缓存,并最终写入到磁盘的一个文件中。当Container打的日志量过大,或者速度过快,Docker Daemon来不及把这个日志写到文件中的时候,就会导致Docker Daemon crash。
Docker热升级功能设计
除了我这里列举的一些Docker Daemon的bug会导致Docker Daemon crash之外,我们日常也有对Docker Daemon进行升级的一个需求。总而言之,Docker Daemon的单点问题是一个痛点,所以我们就对Docker Daemon的热升级功能进行了开发。要开发这样一个功能,首先搞清楚Docker Daemon为什么会在它停止的时候杀掉所有的Container,主要是受限于两点:
第一用户的进程是Docker Daemon子进程;
第二就是Container的IO流会经过Daemon缓存,如果Docker Daemon挂掉的时候它不去杀掉所有的Container,在它被重新拉起来之后,它无法将这个IO流重新以原先的方式流经Daemon,这样势必会对它的Docker attach造成影响,所以现在一直都没有支持这样一个无单点的设计。
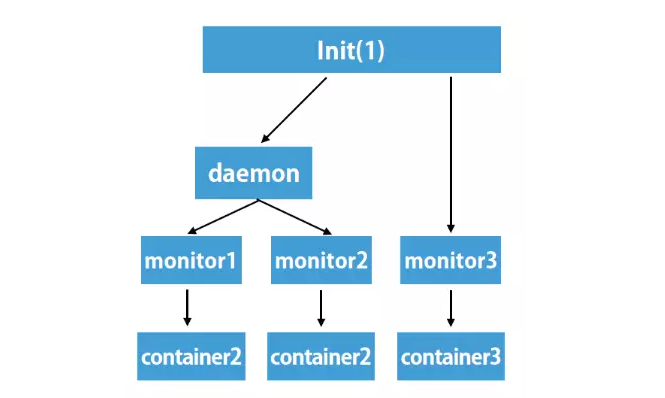
图1
我们的做法也非常简单,就是把原先的两层进程父子关系变为三层(如图1),在Docker Daemon代码里面有一个monitor的组件,这个monitor的组件最开始是一个goroutine的方式,我们将这个goroutine的方式改为进程的方式,等待Container的运行结束。这样在Docker Daemon挂掉的时候,它没必要去杀掉Container,也没必要去杀掉monitor,它只需要自己把自己的活干完退出之后,monitor的进程它自己就会变成孤儿进程,从而托管给INIT进程,也就是进程号唯一的进程。 这样在Docker Daemon重启之后,它就会从磁盘上加载所有Container的运行状态,恢复所有的Container状态。
下面讲述这样做对上层的调度系统的影响。一般调度系统拉起一个Container之后会使用Docker wait的命令去等待这个Container的运行结束,如果没有热升级功能的时候,client跟Daemon之间是通过http请求的方式通信的,那Docker Daemon挂掉之后势必会给client返回一个connection reset的response,这样的话上层的调度系统就势必会受到一些影响,对于这个client的状态就无法感知了。
Docker crash不影响Docker wait
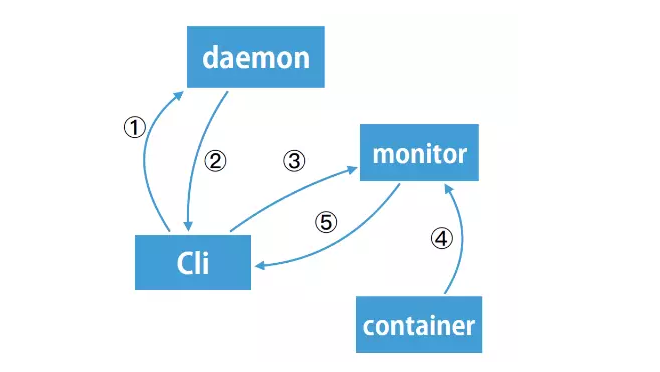
图 2
我们的做法就是(如图2)将这个wait的请求转发到monitor进程,就是最开始还是client向Daemon请求说我要wait这个Container结束,那这个时候Docker Daemon发现自己已经开启热升级功能的情况下,它将这个请求返回一个 305 redirect 请求,把redirect请求返回给monitor,这时候客户端收到这个response后,发现它是一个redirect ,它就会从location字段中拿到当前要操作的这个container的monitor进程的地址,是一个IP加端口的一个形式。 client进程就会给monitor进程发送一个wait请求,这时候monitor进程会等待container运行结束,当container运行结束之后会给client端返回response。可以看到改成这样一种工作流之后,DockerDaemon整个wait的请求过程跟Docker Daemon已经没有任何关系,它挂不挂其实对整个过程没有任何的影响。
Docker热升级功能实现
我接着介绍一下热升级功能的实现。首先为了兼容以前的方式,我们增加了一个开关,就是hot restart参数,并且将monitor的代码组件进行接口化设计,让它支持以前的goroutine以及外部进程两种方式。
其次由于Container结束时Docker Daemon可能是存活状态,也可能是已经死掉的状态,所以monitor进程在Container结束的时候会将它的启动和结束事件首先持久化到磁盘,再通知Docker Daemon更新Container状态。如果这时候Docker Daemon已经挂掉了,我们就重启一定的次数,如果没有通知成功,也不用继续等待这个Daemon进程启动就直接退出了,因为它原先已经把Container这个结束事件持久化到磁盘上了,当Docker Daemon重启之后,它就可以从磁盘加载这个Container的状态迁移文件,从而可以正确的恢复Container的状态。
第三比如说为了解决wait以及attach这些命令的问题,我们就将这些请求重定向到monitor进程进行处理,比如说attach请求的IO流,它以前是通过Daemon进行缓存的,那现在就通过monitor进程进行缓存,这样Docker Daemon挂掉对于每个Container来说并没有什么太大的影响。
第四比如说网络状态,现在Container Daemon的网络部分的代码已经全部迁出,迁出到一个新的工程叫做Libnetwork,Libnetwork中有很多的实体,比如说Libnetwork/Endpoint/Sandbox等有部分的状态是保存在内存中的,它原先自己会存储一些global的网络的状态,比如说global网络指的是一些Overlay网络,这种网络,它需要一些全局信息的保存,所以它会存在global kv,global kv可能是zkEtcd或者是Consul ,我当时在做这个功能的时候就为Libnetwork引入了localstore功能,这个功能就会存储一些本地的网络的状态信息,比如说bridge模式的一些状态信息。
Docker网络模式扩展
相信使用Docker的人都会遇到网络部分的问题,网络部分是一个比较头疼的问题,也是每一家都会必然解决的问题。原先Docker Daemon提供了两种方式:
第一种是Host方式,是完全没有隔离的一个方式,它的优点是性能好,但是缺点也很明显,就是没有网络隔离,有端口冲突的问题。
其次Docker Daemon提供了一个bridge方式,也就是NAT的网络模式,这种网络模式提供了网络隔离的功能,它解决了端口冲突问题。但是Container IP是一个私有的IP,对外是不可见的。所以从另外一台主机的Container想要直接访问这个Container是不行的,必须得通过主机的一个映射之后的主机的一个IP,以及映射之后的端口去访问这个Container。但是端口映射提高了业务迁移的成本,他们可能会需要去改代码,或者去改配制。并且NAT的这种方式对网络的IO性能比Host方式也低了接近10%。
用户对网络的需求
看一下Gaia平台在接入用户业务的过程中遇到的一些网络方面的需求。比如说用户可能会觉得端口冲突问题它不想改代码或者配置。第二就是可能有些业务会将本机的一个IP注册到ZooKeeper上做服务发现,这时候如果是使用NAT方式的话,这个私有IP如果注册到ZooKeeper上是完全没有任何意义的。第三就是有些业务会对有权限访问自己服务的IP做限制,比如说做白名单限制,这时候在同一个主机上的Container互相访问的时候,由于它的流量是从主机的Container首先发出,然后进入到global space,这时候会对它的IP进行原IP的替换,就是SNAT的过程。由于流量是从Docker 0进入的,所以它会将原IP替换成Docker 0的IP,也就是一个私有的IP,这时候在同组机的另外一个Container中看到的原IP就不是这个主机的IP,它是Docker 0的原IP,很显然这个IP是不能加入到它的白名单里面的,因为这是个私有IP,不能确定这个IP是从哪里访问过来的。
我们当初也做了一个改进,原先的SNAT的规则其实是MASQUERADE的规则,这个规则它会将原IP从哪个网卡进就会替换成哪个网卡的一个IP,后来我们加了一条规则是将它的原IP写死了,改成主机的IP,这样它在另外一个Container看到的是主机的IP,所以就不会有问题。
下面一点就是很多业务使用腾讯的TGW网关对外提供服务。我们在测试TGW对接NAT方式的时候发现报文是不通的, 之所以不通是因为外面的流量访问进来之后,它会首先做一个DNAT的过程 ,DNAT的过程会把目的IP转化成Container的一个私有IP,之后当Container中的进程进行回包的时候,这时候其实走的是一个NAT的过程,因为它进来的时候发生了DNAT的过程,这个过程是发生在PREROUTING阶段,然后出去的时候是一个逆过程,这个时候这个包的IP的替换会发生在路由决策之后,这样在路由决策的时候destination IP还没有替换,所以导致这个TCP/IP的协议无法对包进行封包,所以会导致通过TGW对接NAT的方式是不可行的。
下面一点是某些业务,比如说GPU业务,可能要求很好的网络性能,这个也是通过NAT的方式无法解决的。
固定IP网络模式

图 3
下面就看我们对于网络的改进(如图3)。前面很多公司也介绍了,大家会给Container分配一个内网IP,我们也是这么做的。 但是我们所不同的是我们在原先的网桥上面加了一个VLAN设备 ,这个起到什么怎么呢?比如说有一些内网IP跟主机的IP不处于同一个VLAN的时候,如果直接分配到Container中,通过网桥桥接起来,这时候网络是不能通的,因为需要给它出的流量打上一个vlan tag它才能通,这样我们就在原有的基础之上加了一个VLAN设备,这个VLAN设备后面再桥接一个网桥,然后让这些与主机的IP不同一个VLAN的IP的Container桥接到另外一个网桥上面, 这样它出来都会打上这个vlan tag ,这样就可以通了。 这种方式相比NAT的方式,可能的IP对外可见,没有端口映射带来的迁移成本,也少了iptables或者是用户态进程的一个转发过程,所以性能略优于NAT的方式 。 结合Gaia等上层调度系统可以实现IP漂移的功能,就是在Container发生迁移的过程中IP可以保持不变。
SR-IOV
下面介绍一下SR-IOV技术,SR-IOV技术是一个硬件虚拟化技术,它可以由一个网卡虚拟出多个功能接口,每个功能接口实际上是可以做一个网卡使用的。通过这种硬件取代内核的虚拟网络设备的方式,可以极大的提高网络的性能,并且减少了物理机CPU的消耗。Docker 1.9.0版本支持网络插件的方式,所以我们实现了一个SR-IOV的网络插件,去非常方便的使用这种方式。
下面(图4)的一个图表就是我们测试使用SR-IOV之后所带来的性能的提升。横坐标是测试的主要是在虚拟化比是1:1和1:4的情况下,网络流量包的大小是1个字节、64个字节和256个字节的情况下SR-IOV的方式相比NAT方式所带来的包量的提升。
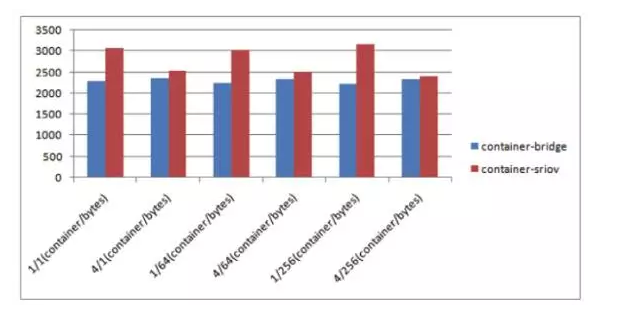
图 4
Docker Overlay网络模式
第三就是Overlay网络为我们提供了多租户网络隔离功能,并且每个租户可以分配一个独立的虚拟的IP段。这种方式不需要分配一个内网的IP,也不需要依赖于NAT的方式,这种方式想必是以后必然会用上的一种多租户的一个解决方案。但是Docker原生的Libnetwork在overlay driver为接入的Container默认连接了一个NAT网络对外提供服务,通过这个NAT的网络Container就不单可以访问与自己位于一个Overlay的其它的Container,也可以访问外网,因为它是通过NAT的方式去访问的。但是很多Container并不一定需要访问内网或者外网,所以我们给Libnetwork对象增加了一个internal开关,创建完全与外界隔离的一个网络。
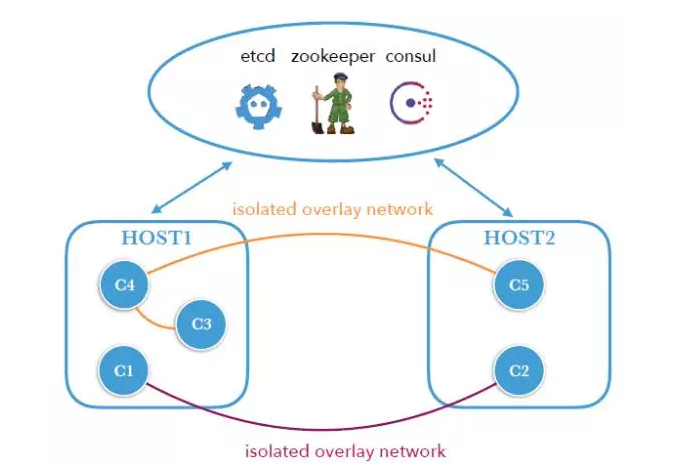
图 5
这个图(图5 )是位于不同主机上的5个Container,C1和C2构成一个Overlay网络,C3、C4、C5构成另外一个Overlay网络,这两个网络彼此之间不同,如果说某些Container想要对外提供服务,这时候我们可以给它分配一个内网的IP,让它对外提供服务。
Container数据存储
接下来分享一下我们在存储方面的工作。Container数据存储相信也是使用Docker的人绕不开的一个问题。我们的做法就是在Container迁移后不需要保留的数据,就给它分配一个host volume进行存储它的数据。如果这个Container迁移之后它的数据需要保留,给它分配一个Ceph RBD存储,我们是使用了Ceph volume plugin为每个Container分配一个RBD的存储目录。
Container资源隔离
接下来介绍一下我们在资源隔离方面的一些工作。Docker本身对内存的控制是hard limit方式,就是Container的进程的内存如果超过它申请的,比如说5G的一个总的上限,它就会将这个Container给杀掉。但是这种方式就非常不方便,比如说用户可能并不知道它的Container实际到峰值的时候使用到多少的内存,并且在很多情况下当Container超过它的内存上限的时候,这个机器的所有内存其实还有很多的空闲,这时候我们的做法是为这个机器上所有的Container设置一个总的流程上限,Hard limit。单个Container内存使用超出申请值,如果这个机器的所有Container没有超出设置的总的Hard limit值时不会触发kill,只有当总的内存超过Hard limit一定的百分比之后,才kill那些超出内存申请值最多的Container,这种方式可以大大降低集群中Container被kill的几率。
网络出带宽控制
下面一点是我们在做网络出带宽的控制的时候发现,如果直接使用net_cls的方式对流量进行标志的时候,数据包会经过bridge之后pid会发生丢失,这时候打的标记是没有效果的。所以我们的做法就是在iptables的mangle表中对Container出流量按IP进行标记,这个时候我们就可以方便的使用TC工具对标记的流量进行限制。
容器中资源显示问题
下面一个问题也是很多讲师都讲到的问题,是容器中自然显示的问题,原先跑在物理机或者虚拟机中的业务在使用腾讯网管系统记录机器的资源使用情况,但是如果都迁移到Container中之后,这个时候Container中显示的资源可能是主机的资源,那并不是它自己实际使用的资源。所以我们就需要解决这个问题,可能有一些团队是通过修改内核的方式去解决的,但是修改内核可能还需要自己维护这些patch。 我们的做法就是通过FUSE实现了一个用户态的文件系统,这个用户态的文件系统使用的是Cgroup的数据统计Container的实际资源使用 ,它可以为每个Container生成仿真的meminfo stats或者diskstats cpuuinfo文件,然后在启动Container的时候将这些文件直接mount到Container中,这个程序是用go语言实现的,使得它非常方便的嵌入到Docker的代码中,整个过程对Docker用户透明,这个链接( https://github.com/chenchun/cgroupfs)是我们做的这个功能的代码的地址。
文:陈纯
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

