使用 CombineFileInputFormat 在 Hadoop 中处理小的压缩文件
简介
Apache Hadoop 软件库能够处理从纯文本文件到数据库的多种类型的数据格式。MapReduce 框架根据作业的 InputFormat 来验证输入规范,并将输入文件拆分成逻辑 InputSplits,然后将其分配给某个单独的 Mapper。
FileInputFormat 是所有基于文件的 InputFormat 的基类,它有以下直属子类:
-
TextInputFormat -
SequenceFileInputFormat -
NLineInputFormat -
KeyValueTextInputFormat -
CombineFileInputFormat
所有这些 InputFormat 都提供了 getSplits(JobContext) 的一个通用实现,它还可以覆盖 isSplitable ( JobContext , Path ) 方法,确保输入文件没有被拆分,并作为一个整体由 Mapper 处理。它实现了从 org.apache.hadoop.mapreduce.InputFormat 类继承的 createRecordReader ,使用它从逻辑 InputSplit 收集输入记录,供 Mapper 进行处理。
InfoSphere BigInsights Quick Start Edition
InfoSphere® BigInsights™ Quick Start Edition 是一个免费的、可下载的 InfoSphere BigInsights 版本,是 IBM 基于 Hadoop 的产品。使用 Quick Start Edition,您可以尝试使用 IBM 开发的特性来提高开源 Hadoop 的价值,比如 Big SQL、文本分析和 BigSheets。引导式学习可让您的体验尽可能地顺畅,包括按部就班、自订进度的教程和视频,可帮助您开始让 Hadoop 为您所用。没有时间或数据限制,您可以自行安排时间,在大量数据上试验。观看视频,学习教程(PDF),并 立刻下载 InfoSphere BigInsights Quick Start Edition 。
不过,Hadoop 处理少量大文件时的性能比处理大量小文件时的性能更好一些。(“小” 在这里指的是比 Hadoop 分布式文件系统(HDFS)块要小得多。)通过设计 CombineFileInputFormat 可以缓解这种情况,它可以高效地处理小文件,让 FileInputFormat 为每个文件创建一个 split。 CombineFileInputFormat 将多个文件打包到每个 split 中,所以每个 Mapper 都要处理更多的 split。 CombineFileInputFormat 在处理大文件时也有其优势。实质上,它使 Mapper 操作中处理的数据量与 HDFS 中文件的块大小之间的耦合度降低了。
目前, CombineFileInputFormat 是 Hadoop 类库中的一个抽象类 (org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat<K,V>),没有任何具体实现。为了获得 CombineFileInputFormat 的优势,您需要创建一个具体的 CombineFileInputFormat 子类,并实现 createRecordReader() 方法,该方法将实例化一个委托 CustomFileRecordReader 类,它使用其自定义构造函数来扩展 RecordReader 。此方法还要求构造一个 CustomWritable 作为 Hadoop Mapper 类的键。对于每一行, CustomWritable 将包括文件名称和该行的偏移长度。
查看一个 Hadoop 示例 ,该示例演示了如何使用 CombineFileInputForma 来计算单词在给定输入目录下的文本文件中出现的次数。
在这里,您将学习如何添加一些,在运行时读取采用解压缩形式的 gzip(默认编解码器)文件的内容,从而扩展和实现 CombineFileInputFormat 。我们将生成一个键值输出,其中 键 是文件名 和该行的偏移的组合,而 值 是该行的文本表示。本文中的示例使用了 MapReduce 框架中的 CustomInputFormat 。您将开发以下关键的类:
-
CompressedCombineFileInputFormat - 扩展 CombineFileInputFormat 并实现
createRecordReader,以便传入用来组合文件逻辑的记录读取器。 -
CompressedCombineFileRecordReader - 扩展了
RecordReader,而且是CombineFileRecordReader的委托类。 -
CompressedCombineFileWritable - 实现
WritableComparable,保存文件名 和偏移量,并覆盖compareTo方法,以便先比较文件名,再比较偏移量。
CompressedCombineFileInputFormat 示例使用了 MapReduce 程序,它使用了可公开获得的美国国家海洋和大气管理局(NOAA)的历史天气数据。NOAA 使用了三个气象要素(气温、降水和降雪)的每月汇总数据,为美国站汇编极端天气的统计数据。这里使用的示例将从压缩(gzip)文件形式提供的气象数据( 国家气候数据中心 )计算出最高温度。 请参见参考资料,获得关于获取气象数据的详细信息。
回页首
多个压缩文件输入格式
我们的解决方案采用了压缩的 CombineFileInputFormat ,它使用三个具体的类:
-
CombineFileInputFormat的抽象实现的一个子类 (org.apache.hadoop.mapreduce.lib.input. CombineFileInputFormat<K,V>) -
RecordReader的具体子类 (org.apache.hadoop.mapreduce.RecordReader<K,V>) - 自定义的
Writable类,它实现了WritableComparable(org.apache.hadoop.io.WritableComparable),并生成了文件行的键,它包含文件名和行的偏移量
CompressedCombineFileInputFormat
CompressedCombineFileInputFormat.java 是 CombineFileInputFormat 的子类。它实现了 InputFormat.createRecordReader(InputSplit, TaskAttemptContext ), 为 CombineFileSplit 构造 RecordReader 。 CombineFileSplit 是输入文件的一个子集。与 FileSplit 不同, CombineFileSplit 类不代表一个文件的 split,而是要将输入文件拆分成更小的集合。split 可以含有来自不同文件的块,但在同一个 split 中的所有块对于同一机架可能是本地的。通过每个文件读取一个记录,您可以使用 CombineFileSplit 来实现 RecordReader 。它不要求将文件对半拆分,所以 isSplitable() 方法被重写为返回 false(否则返回默认值 true)。清单 1 显示了一个示例。
清单 1. CompressedCombineFileInputFormat.java
package com.ssom.combinefile.lib.input; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat; import org.apache.hadoop.mapreduce.lib.input.CombineFileRecordReader; import org.apache.hadoop.mapreduce.lib.input.CombineFileSplit; public class CompressedCombineFileInputFormat extends CombineFileInputFormat<CompressedCombineFileWritable, Text> { public CompressedCombineFileInputFormat(){ super(); } public RecordReader<CompressedCombineFileWritable,Text> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException { return new CombineFileRecordReader<CompressedCombineFileWritable, Text>((CombineFileSplit)split, context, CompressedCombineFileRecordReader.class); } @Override protected boolean isSplitable(JobContext context, Path file){ return false; } } CompressedCombineFileRecordReader
CompressedCombineFileRecordReader.java 是 CombineFileRecordReader 的委托类,它是一个通用的 RecordReader,可以为 CombineFileSplit 中的每个块分发不同的 RecordReaders。 CombineFileSplit 可以组合来自多个文件的数据块。此类允许您使用不同的 RecordReaders 来处理来自不同文件的数据块。
在调用 Hadoop 作业时, CombineFileRecordReader 将会读取 HDFS 输入路径中需要处理的所有文件大小,并根据 MaxSplitSize 决定需要多少 split。对于每个 split(必须是一个文件,因为 isSplitabe() 被覆盖并被设置为返回 false), CombineFileRecordReader 都会创建一个 CompressedCombineFileRecordReader 实例,并传递 CombineFileSplit 、 context 和 index ,供 CompressedCombineFileRecordReader 用来查找要处理的文件。
在实例化 CompressedCombineFileRecordReader 之后 ,它将确定输入文件是否包含压缩编解码器 (org.apache.hadoop.io.compress.GzipCodec)。如果是的话,则会在运行时解压缩该文件,并将它用于处理。否则,则认为它是一个文本文件。在处理该文件时, CompressedCombineFileRecordReader 会创建 CompressedCombineFileWritable ,使用它作为被调用的 Mapper 类的键。对于已读取的每一行, CompressedCombineFileWritable 包括文件名和该行的偏移长度,如MapReduce 示例中所示。
清单 2 显示了一个 CompressedCombineFileRecordReader.java 示例。
清单 2. CompressedCombineFileRecordReader.java
package com.ssom.combinefile.lib.input; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.compress.CompressionCodec; import org.apache.hadoop.io.compress.CompressionCodecFactory; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.CombineFileSplit; import org.apache.hadoop.util.LineReader; /** * RecordReader is responsible from extracting records from a chunk * of the CombineFileSplit. */ public class CompressedCombineFileRecordReader extends RecordReader<CompressedCombineFileWritable, Text> { private long startOffset; private long end; private long pos; private FileSystem fs; private Path path; private Path dPath; private CompressedCombineFileWritable key = new CompressedCombineFileWritable(); private Text value; private long rlength; private FSDataInputStream fileIn; private LineReader reader; public CompressedCombineFileRecordReader(CombineFileSplit split, TaskAttemptContext context, Integer index) throws IOException { Configuration currentConf = context.getConfiguration(); this.path = split.getPath(index); boolean isCompressed = findCodec(currentConf ,path); if(isCompressed) codecWiseDecompress(context.getConfiguration()); fs = this.path.getFileSystem(currentConf); this.startOffset = split.getOffset(index); if(isCompressed){ this.end = startOffset + rlength; }else{ this.end = startOffset + split.getLength(index); dPath =path; } boolean skipFirstLine = false; fileIn = fs.open(dPath); if(isCompressed) fs.deleteOnExit(dPath); if (startOffset != 0) { skipFirstLine = true; --startOffset; fileIn.seek(startOffset); } reader = new LineReader(fileIn); if (skipFirstLine) { startOffset += reader.readLine(new Text(), 0, (int)Math.min((long)Integer.MAX_VALUE, end - startOffset)); } this.pos = startOffset; } public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { } public void close() throws IOException { } public float getProgress() throws IOException { if (startOffset == end) { return 0.0f; } else { return Math.min(1.0f, (pos - startOffset) / (float) (end - startOffset)); } } public boolean nextKeyValue() throws IOException { if (key.fileName== null) { key = new CompressedCombineFileWritable(); key.fileName = dPath.getName(); } key.offset = pos; if (value == null) { value = new Text(); } int newSize = 0; if (pos < end) { newSize = reader.readLine(value); pos += newSize; } if (newSize == 0) { key = null; value = null; return false; } else { return true; } } public CompressedCombineFileWritable getCurrentKey() throws IOException, InterruptedException { return key; } public Text getCurrentValue() throws IOException, InterruptedException { return value; } private void codecWiseDecompress(Configuration conf) throws IOException{ CompressionCodecFactory factory = new CompressionCodecFactory(conf); CompressionCodec codec = factory.getCodec(path); if (codec == null) { System.err.println("No Codec Found For " + path); System.exit(1); } String outputUri = CompressionCodecFactory.removeSuffix(path.toString(), codec.getDefaultExtension()); dPath = new Path(outputUri); InputStream in = null; OutputStream out = null; fs = this.path.getFileSystem(conf); try { in = codec.createInputStream(fs.open(path)); out = fs.create(dPath); IOUtils.copyBytes(in, out, conf); } finally { IOUtils.closeStream(in); IOUtils.closeStream(out); rlength = fs.getFileStatus(dPath).getLen(); } } private boolean findCodec(Configuration conf, Path p){ CompressionCodecFactory factory = new CompressionCodecFactory(conf); CompressionCodec codec = factory.getCodec(path); if (codec == null) return false; else return true; } } CompressedCombineFileWritable
CompressedCombineFileWritable.java 类实现 WritableComparable 并扩展 org.apache.hadoop.io.Writable, java.lang.Comparable ,如清单 3中所示。
Writable 是一个序列化对象,它根据 DataInput 和 DataOutput 来实现简单而又有效的序列化协议。MapReduce 框架中的任意键或值类型都可以实现该接口。该实现通常使用静态的 read(DataInput) 方法,此方法构造了一个新的实例,调用 readFields(DataInput) ,并返回实例。
Comparable 是一个接口,是 Java™ 集合框架 (JCF) 的成员。它规定了实现它的每个类的对象上的整体排序。这种排序被称为类的 自然 排序。该类的 compareTo 方法被称为其 自然比较 方法。实现此接口的对象的列表(和数组)可以通过 Collections.sort (和 Arrays.sort )自动进行排序。实现该接口的对象可以作为有序映射中的键,或者作为一个有序集中的元素,不需要指定一个比较器。
因为这类特性,您可以使用比较器来比较 CompressedCombineFileWritable 。 hashCode() 命令常用于在 Hadoop 中对键进行分区。值得一提的是, hashCode() 实现将会在 JVM 的不同实例之间返回相同的结果。 Object 中的默认 hashCode() 实现不适合该属性。因此,将会覆盖 hashCode() 、 equals() 和 toString() 方法,以便获得一致性和效率。
清单 3. CompressedCombineFileWritable.java
package com.ssom.combinefile.lib.input; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; /** * This record keeps filename,offset pairs. */ @SuppressWarnings("rawtypes") public class CompressedCombineFileWritable implements WritableComparable { public long offset; public String fileName; public CompressedCombineFileWritable() { super(); } public CompressedCombineFileWritable(long offset, String fileName) { super(); this.offset = offset; this.fileName = fileName; } public void readFields(DataInput in) throws IOException { this.offset = in.readLong(); this.fileName = Text.readString(in); } public void write(DataOutput out) throws IOException { out.writeLong(offset); Text.writeString(out, fileName); } public int compareTo(Object o) { CompressedCombineFileWritable that = (CompressedCombineFileWritable)o; int f = this.fileName.compareTo(that.fileName); if(f == 0) { return (int)Math.signum((double)(this.offset - that.offset)); } return f; } @Override public boolean equals(Object obj) { if(obj instanceof CompressedCombineFileWritable) return this.compareTo(obj) == 0; return false; } @Override public int hashCode() { final int hashPrime = 47; int hash = 13; hash = hashPrime* hash + (this.fileName != null ? this.fileName.hashCode() :0); hash = hashPrime* hash + (int) (this.offset ^ (this.offset >>> 16)); return hash; } @Override public String toString(){ return this.fileName+"-"+this.offset; } } 回页首
MapReduce 示例
本节中的示例通过一个样本 MapReduce 程序介绍了如何使用 CompressedCombineFileInputFormat 。MapReduce 程序使用了 NOAA 的历史气象数据,以及使用温度、降水和降雪的每月汇总数据,为美国站汇编极端天气的统计数据。这里使用的示例将从压缩(gzip)文件形式提供的气象数据中计算出最高温度。
该示例将引导您完成 CompressedCombineFileInputFormat 使用的各个方面。您需要使用 InfoSphere BigInsights Quick Start Edition 来运行该示例。
假设
该示例假设:
- 已安装并运行 Hadoop 环境。
- 示例所需数据是从 NOAA 的 国家气候数据中心 下载的。
- 下载数据已输入 HDFS。
- 在 InfoSphere BigInsights Quick Start Edition(适用于非生产环境)中提供和执行运营统计数据。
运行示例
CompressedCombineFileInputFormat 的类被打包为一个 JAR 文件 (CompressedCombine-FileInput.jar),这样您就可以在其他项目中引用它。对于在使用默认输入格式 (org.apache.hadoop.io.Text) 和自定义输入格式 (com.ssom.combinefile.lib.input.CompressedCombineFileInputFormat) 时的性能差异,我们将使用单独的 MapReduce 程序进行说明。
输入数据
NCDC 数据是公开的。表 1 显示了我们的示例中的 NCDC 数据的格式。
表 1. NCDC 数据
| 读数 | 描述 |
|---|---|
| 0057 | # MASTER STATION 目录标识符 |
| 332130 | # USAF 气象站标识符 |
| 99999 | # WBAN 气象站标识符 |
| 99999 | # WBAN 气象站标识符 |
| 19470101 | # 观测日期 |
| 0300 | # 观测时间 |
| 4 | # 数据源标记 |
| +51317 | # 纬度(度×1000) |
| +028783 | # 经度(度×1000) |
| FM-12 | # 报告类型代码 |
| +0171 | # 海拔(米) |
| 99999 | # 来电来函标识符 |
| V020 | # 质量控制流程名称 |
| 320 | # 风向(度) |
| 1 | # 质量代码 |
| N | # 类型代码 |
| 0072 | # 速率 |
| 1 | # 速度质量代码 |
| 00450 | # 天空云底高度 |
| 1 | # 质量代码 |
| CN | # 云底高度尺寸 |
| 010000 | # 能见距离(米) |
| 1 | # 质量代码 |
| N9 | # 变异代码 |
| -0128 | # 空气温度(摄氏度×10) |
| 1 | # 质量代码 |
| -0139 | # 露点温度(摄氏度×10) |
| 1 | # 质量代码 |
| 10268 | # 大气压力(百帕×10) |
| 1 | # 质量代码 |
数据文件是按日期和气象站进行组织的。自 1901 年以来,每年都有一个目录。在每个目录中,每个气象站都有一个压缩文件,其中包含该气象站当年的读数。图 1 显示了 1947 年的第一个条目。
图 1. 示例文件列表

我选择了 1901 年、1902 年和 1947 年的数据,这涉及 1000 多个压缩文件。 这些文件的总大小约为 56 MB。
使用默认输入格式
Mapper 类是一个泛型,有 4 个正式的类型参数,指定映射函数的输入键、输入值、输出键和输出值类型,如下所示。
public class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 对于默认的输入格式:
- 输入键长整数偏移量
- 输入值是一行文本
- 输出键是一个年份
- 输出值是一个空气温度(整数)
map() 方法传递一个键和一个值,它将包含输入行的文本值转换成一个 Java 字符串。然后,它使用 substring() 方法来提取值。在本例中, Mapper 将年份写入为一个 Text 对象(因为我们只是用它作为一个键),并且将温度打包在一个 IntWritable 中。只在有温度值,而且质量代码指示温度读数没问题时,才会写入一个输出记录。
Reducer 类也是一个泛型:它有四个正式的类型参数,用于指定输入和输出类型。reduce 函数的输出类型是 Text 、 IntWritable 和年份,以及它的最高温度,这是通过遍历温度并与目前发现的每个最高温度的记录进行比较得出的。Reducer 类的定义是:
public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 如果有多个年份,输出看起来如下所示。
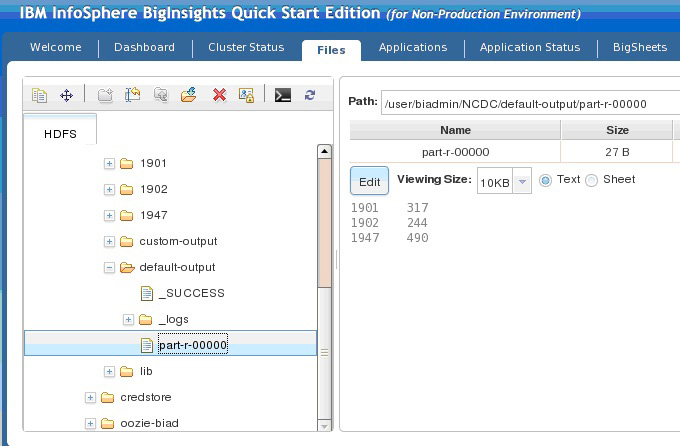
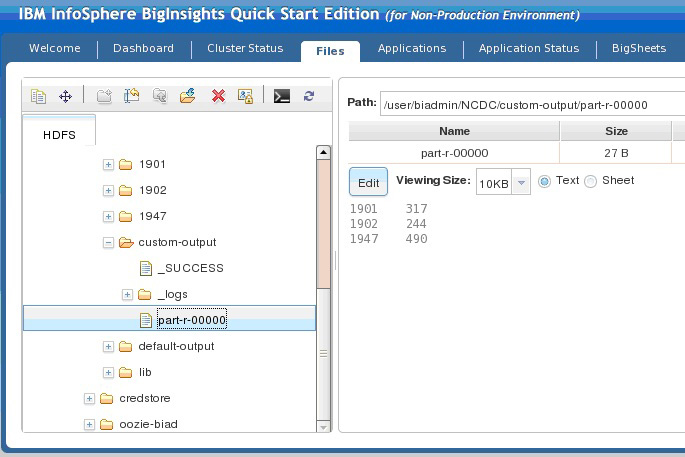
- 1901 — 278
- 1947 — 283
图 2 和图 3 显示了在 InfoSphere BigInsights Administration Console 中使用默认的( Text )输入格式运行该程序的结果。
图 2. 应用程序的状态 — 默认执行
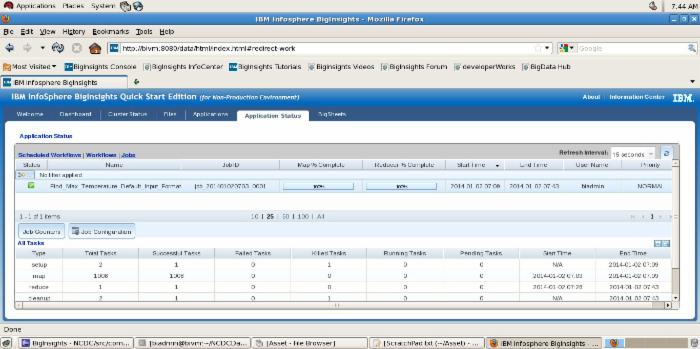
点击查看大图
关闭 [x]
图 2. 应用程序的状态 — 默认执行
图 3. 完成

点击查看大图
关闭 [x]
图 3. 完成
InfoSphere BigInsights Administration Console 提供了如表 2 所示的关键统计数据。
表 2. 生成的统计数据
| 关键属性 | 结果 |
|---|---|
| Name | Find_Max_Temperature_Default_Input_Format |
| Job ID | job_201401020703_0001 |
| Map % Complete | 100% |
| Reducer % Complete | 100% |
| Start Time | 2014-01-02 07:09 |
| End Time | 2014-01-02 07:43 |
| User Name | biadmin |
| Priority | NORMAL |
| 执行操作并获得结果所用的总时间为 34 分钟。 |
图 4 显示了 MapReduce 程序的输出。
图 4. 响应文件的内容 — 默认执行
使用自定义输入格式
同样,您将使用 Mapper 类,它是一个泛型,使用 CompressedCombineFileWritable 作为输入键,如下所示。
public class MaxTMapper extends Mapper<CompressedCombineFileWritable, Text, Text, IntWritable> { 处理逻辑与前面的示例是相同的(参阅使用默认输入格式)。
Reducer 类保持不变,其定义为:
public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 为了设置作业的输入格式,我们使用了:
job.setInputFormatClass(CompressedCombineFileInputFormat.class);
示例键和值是:
Key:227070-99999-1901-116370 Line: 0029227070999991901101520004+62167+030650FM -12+010299999V0201401N003119999999N0000001N9+00331+99999102311 ADDGF100991999999999999999999
图 5 和图 6 显示了在 InfoSphere BigInsights Administration Console 中运行自定义的( Text )输入格式的结果。
图 5. 应用程序的状态 — 自定义执行
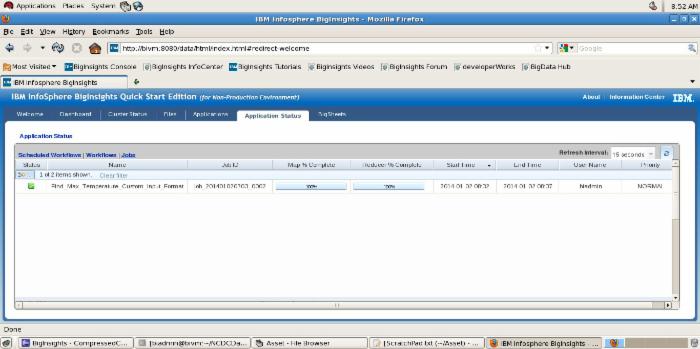
点击查看大图
关闭 [x]
图 5. 应用程序的状态 — 自定义执行
图 6. 完成

InfoSphere BigInsights Administration Console 提供了如表 3 所示的关键统计数据。
表 3. 来自多个年份的输出
| 关键属性 | 获得的结果 |
|---|---|
| Name | Find_Max_Temperature_Custom_Input_Format |
| Job ID | job_201401020703_0002 |
| Map % Complete | 100% |
| Reducer % Complete | 100% |
| Start Time | 2014-01-02 08:32 |
| End Time | 2014-01-02 08:37 |
| User Name | biadmin |
| Priority | NORMAL |
| 执行操作并获得结果所用的总时间为 5 分钟。 |
图 7 显示了 MapReduce 程序的输出。
图 7. 响应文件的内容 — 自定义执行
回页首
结束语
如果可以的话,最好避免使用许多小文件,因为 MapReduce 在以集群中的磁盘传输速率运行时的性能最好。处理许多小文件会增加运行一个作业需要执行的查找的数量。如果出于商业或战略上的原因,您有大量小文件,而且有可用的 HDFS,那么 CombineFileInputFormat 可能很有用。 CombineFileInputFormat 不仅有利于小文件,而且还可以在处理大文件时带来性能优势。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

