CacheSim-1 Cache背景知识简介
Introduction
CacheSim 简单的Cache模拟器 专辑目录
本文简要介绍Cache的背景知识,以及Cache结构的划分。
在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是,确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存。
From wiki
Cache
片上Cache的材质一般是SRAM,主存一般是DRAM,SRAM速度通常是DRAM的10~20倍。但是SRAM的工艺复杂,造价较高,同样的技术,DRAM的容量通常是SRAM的5~10倍。
高速缓冲(Cache)存储器是指为弥补主存速度不足,在处理器和主存之间设置一个高速、小容量的Cache,构成Cache-主存存储层次,使之从CPU来看,速度接近于Cache,容量却是主存的。
Cache的容量很小,它保存的内容只是主存内容的一个子集,且Cache与主存的数据交换是以块为单位的。为了把信息放到Cache中,必须应用某种函数把主存地址定位到Cache中,这称为地址映射。在信息按这种映射关系装入Cache后,CPU执行程序时,会将程序中的主存地址变换成Cache地址,这个变换过程叫做地址变换。
Cache的地址映射方式有直接映射、全相联映射和组相联映射。
典型的Intel的Cache结构:
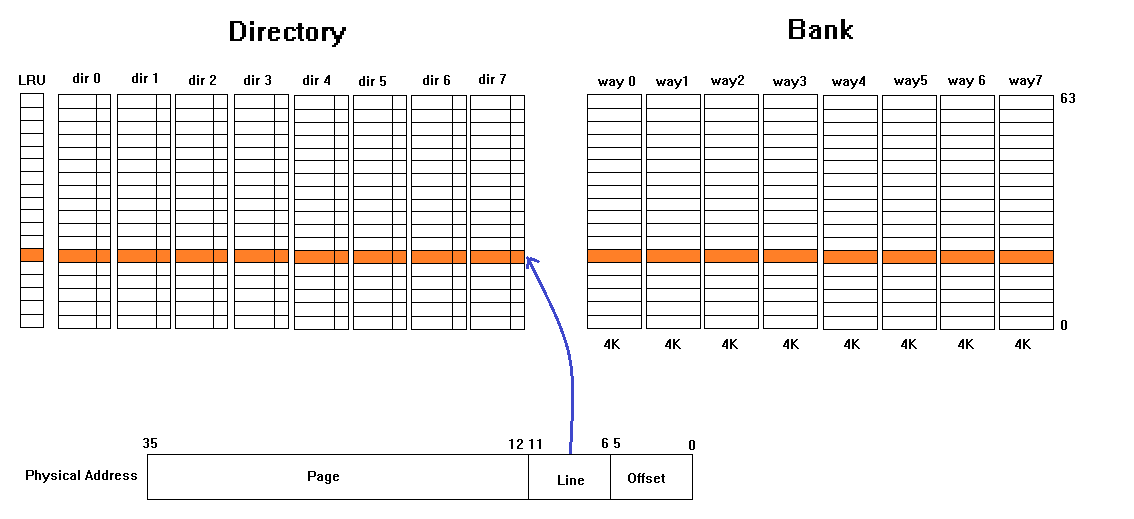
它是一个 8-way set 的 L1-Data Cache 结构,总 32K 大小,line 大小为 64 bytes
cache 中分两大部分:
- Directory:这部分是存放 bank 的信息,用来如何查找 bank
- Bank:这部分是实际存放数据的地方
名词解释
| Cache line | 又称为cache block,cache块,极少有人直译缓存线(除了开源中国有个翻译组) |
| way | 几路组相联,一般一个way对应一个line |
| Set | 组,四路组相联则表示4个cache line构成一个set,有的地方叫entry |
| 有效位 | 标识了cache line里的数据是否是有效的 |
| 脏位 | 标识了cache line里的数据是否和主存对应的块一致,如果是脏的,则需要写回到主存 |
地址映射方式
以组相联为例,
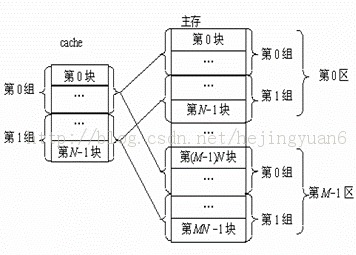
组相联映射实际上是直接映射和全相联映射的折中方案,其组织结构如图3-16所示。主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。也就是说,将Cache分成u组,每组v块,主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。例如,主存分为256组,每组8块,Cache分为8组,每组2块。
为了区分装入Cache的块是哪一个主存区的,需要用一个按地址访问的表存储器来存放Cache中的每一块位置目前是被主存中哪个区的块所占用的区号。这个表存储器是专门的硬件。我们的模拟器可以不去关心这一块的比较。
地址的划分
以组相联为例,
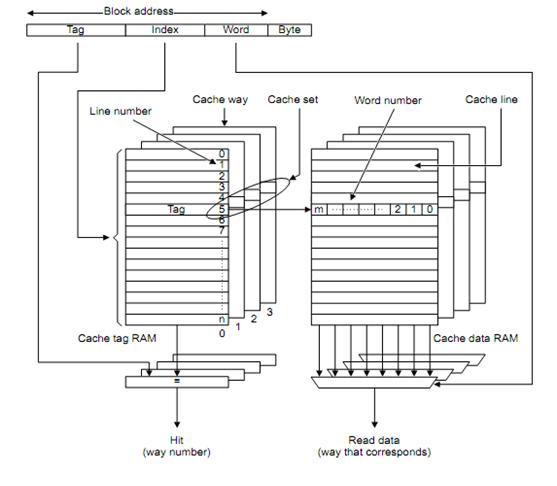
在我们的模拟器中,按照如下划分:
内存地址:
|tag |组号 |组内块号|块内地址| 各个部分的长度:
| tag | 剩余的可用空间的前面的部分 |
| 组号 | log2(cache_set_size) |
| 块内地址 | log2(cache_line_size) |
以16K D cache, 4-ways ,cache line 32bytes为例。先假设主存物理地址0x50000000~0x50004000这段地址内容在cache中,并且一一对应。
Unsigned long tag_index[4][128]={ {0x50000000,0x50000020, 0x50000040, 0x50000060, 0x50000080,…}, {0x50001000,0x50001020, 0x50001040, 0x50001060, 0x50001080,…}, {0x50002000,0x50002020, 0x50002040, 0x50002060, 0x50002080,…} {0x50003000,0x50003020, 0x50003040, 0x50003060, 0x50003080,…} }; Unsigned char data[4][1024][4] ={ {{0,1,2,3},{1,2,3,4},{2,3,4,5},{3,4,5,6},{4,5,6,7},{5,6,7,8}…}, {{0,1,2,3},{1,2,3,4},{2,3,4,5},{3,4,5,6},{4,5,6,7},{5,6,7,8}…}, {{0,1,2,3},{1,2,3,4},{2,3,4,5},{3,4,5,6},{4,5,6,7},{5,6,7,8}…}, {{0,1,2,3},{1,2,3,4},{2,3,4,5},{3,4,5,6},{4,5,6,7},{5,6,7,8}…}, } 上述数组中的每一个值代表了tag sram中的每一个tag。4代表set,128 = 16K/4/32bytes即line number。我们以虚拟地址0xC0000023为例,其物理地址为0x50000023。
其对应的byte=0xC0000023&0x1F = 0x3 ,index=(0xC0000023&0xFE0)>>5 = 1,tag =(0x50000023& 0xFFF)>>12 = 0x50000 那cache是如何索引的呢,其传输首先是0xC0000023这个虚拟地址计算其index = 1,则在4个set中查找index为1的tag这四个tag分别为0x50000020,0x50001020,0x50002020, 0x50003020,同时该虚拟地址会送入MMU将该虚拟地址转换层物理地址为0x50000023,在将物理地址计算出来后,将物理地址的tag位(bit[31:12])与上述tag进行比较,得出该物理地址所对应的set为0,即tag_index[0][1]满足该虚拟地址。之后CPU则会获取data[0][0xC0000023&0xFFF]处得数据。
Reference
CPU缓存
DRAM vs. SRAM
上海交大计算机组成与系统结构课程
理解 Cache
Cache 基本原理之:寻址
Cache类型和地址解析以及硬件实现
Cache 之解正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

