MySQL 锁问题最佳实践
前言
最近一段时间处理了较多锁的问题,包括锁等待导致业务连接堆积或超时,死锁导致业务失败等,这类问题对业务可能会造成严重的影响,没有处理经验的用户往往无从下手。下面将从整个数据库设计,开发,运维阶段介绍如何避免锁问题的发生,提供一些最佳实践供RDS的用户参考。
设计阶段
在数据库设计阶段,引擎选择和索引设计不当可能导致后期业务上线后出现较为严重的锁或者死锁问题。
1. 表引擎选择使用myisam,引发table level lock wait。
从5.5版本开始,MySQL官方就把默认引擎由myisam转为innodb,这两种引擎的主要区别:
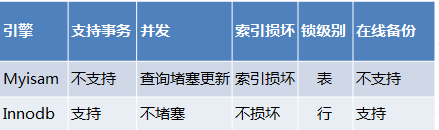
由于myisam引擎只支持table lock,在使用myisam引擎表过程中,当数据库中出现执行时间较长的查询后就会堵塞该表上的更新动作,所以经常会碰到线程会话处于表级锁等待(Waiting for table level lock)的情况,严重的情况下会出现由于实例连接数被占满而应用无法正常连接的情况
CREATE TABLE `t_myisam` ( `id` int(11) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8; Query |111 | User sleep | select id,sleep(100) from t_myisam | Query |108 | Waiting for table level lock | update t_myisam set id=2 where id=1| Query | 3 | Waiting for table level lock | update t_myisam set id=2 where id=1| 从上述的案例中可以看到,t_myisam表为myisam存储引擎,当该表上有执行时间较长的查询语句在执行的时候,该表上其他的更新全被堵塞住了,这个时候应用或者数据库的连接很快耗完,导致应用请求失败。这个时候快速的恢复方法为将线程id:111 kill掉即可(可以执行show processlist查看到当前数据库所有连接状态)。另外myisam存储引擎的表索引在实例异常关闭的情况下会导致索引损坏,这个时候必须要对表进行repair操作,该操作同样会阻塞该表上的所有请求。
2. 表索引设计不当,导致数据库出现死锁。
索引设计是数据库设计非常重要的一环,不仅仅关系到后续业务的性能,如果设计不当还可导致业务上的死锁。下面的一则案例就出现在线上系统,数据库在并发更新的时候出现了死锁,通过排查定位于update更新使用了两个索引导致,死锁信息如下:
*** (1) TRANSACTION: TRANSACTION 29285454235, ACTIVE 0.001 sec fetching rows mysql tables in use 3, locked 3 LOCK WAIT 6 lock struct(s), heap size 1184, 4 row lock(s) MySQL thread id 6641616, OS thread handle 0x2b165c4b1700, query id 28190427937 10.103.180.86 test_ebs Searching rows for update UPDATE test SET is_deleted = 1 WHERE group_id = 1332577 and test_id = 4580605 *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 132 page no 37122 n bits 352 index `PRIMARY` of table `testdriver`.`test` trx id 29285454235 lock_mode X locks rec but not gap waiting Record lock, heap no 179 PHYSICAL RECORD: n_fields 8; compact format; info bits 0 *** (2) TRANSACTION: TRANSACTION 29285454237, ACTIVE 0.001 sec fetching rows, thread declared inside InnoDB 4980 mysql tables in use 3, locked 3 5 lock struct(s), heap size 1184, 3 row lock(s) MySQL thread id 6639213, OS thread handle 0x2b1694cc2700, query id 28190427939 10.103.180.113 test_ebs Searching rows for update UPDATE test SET is_deleted = 1 WHERE group_id = 1332577 and test_id = 4212859 *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 132 page no 37122 n bits 352 index `PRIMARY` of table `testdriver`.`test` trx id 29285454237 lock_mode X locks rec but not gap Record lock, heap no 179 PHYSICAL RECORD: n_fields 8; compact format; 表结构:
CREATE TABLE `test` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘主键’, `test_id` bigint(20) DEFAULT NULL, `group_id` bigint(20) DEFAULT NULL COMMENT ‘Id,对应test_group.id’, `gmt_created` datetime DEFAULT NULL COMMENT ‘创建时间’, `gmt_modified` datetime DEFAULT NULL COMMENT ‘修改时间’, `is_deleted` tinyint(4) DEFAULT ‘0’ COMMENT ‘删除。’, PRIMARY KEY (`id`), KEY `idx_testid` (`test_id`), KEY `idx_groupid` (`group_id`) ) ENGINE=InnoDB AUTO_INCREMENT=7429111 ; SQL执行计划:
mysql>explain UPDATE test SET is_deleted = 1 WHERE group_id = 1332577 and test_id = 4212859 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | | 1 | SIMPLE | test | index_merge | idx_testid,idx_groupid | idx_testid,idx_groupid | 9,9 | | 1 | Using intersect(idx_testid,idx_groupid); Using where; Using temporary | 所以第一个事务先根据group_id索引,已经锁住primary id,然后再根据test_id索引,锁定primary id;第二个事务先根据test_id索引,已经锁住primary id,然后再根据group_id索引,去锁primary id;所以这样并发更新就可能出现死索引。
MySQL官方也已经确认了此 bug:77209 ,解决方法有两种:
- 加test_id + group_id的组合索引,这样就可以避免掉index merge;
- 将优化器的index merge优化关闭。
开发阶段
事务处理时间过长,导致并发出现锁等待。
并发事务处理在数据库中经常看到的应用场景,在这种场景下,需要避免大事务,长事务,复杂事务导致事务在数据库中的运行时间加长,事务时间变长则导致事务中锁的持有时间变长,影响整体的数据库吞吐量。下面的一则案例中,用户的业务数据库中出现大量的update等待,导致大量的业务超时报错:

问题排查:
-
通过
show processlist确定出现锁等待的线程以及SQL信息:|Query|37|updating|UPDATE test_warning SET ... WHERE test_id = '46a9b' -
通过innodb的information_schema数据库中的锁等待以及事务试图,查出相关的锁信息:
select r.trx_mysql_thread_id waiting_thread, r.trx_id waiting_trx_id,r.trx_query waiting_query, b.trx_id blocking_trx_id, b.trx_query blocking_query,b.trx_mysql_thread_id blocking_thread,b.trx_ started,b.trx_wait_started from information_schema.innodb_lock_waits w inner join information_schema.innodb_trx b on b.trx_id =w.blocking_trx_id inner join information_schema.innodb_trx r on r.trx_id=w.requesting_trx_id /G waiting_thread: 318984063 waiting_trx_id: 26432631 waiting_query: UPDATE test_warning SET ........ WHERE test_id = '46a9b' blocking_trx_id: 26432630 blocking_query: NULL blocking_thread: 235202017 trx_started: 2016-03-01 13:54:39从述的锁等待信息中发现,事务26432631被26432630阻塞了,那么我们就可以从general log中去排查一下事务26432630做了哪些操作。
-
从提前打开数据库的general log中查找到上述被blcok 的update语句在日志中的位置,发现了update被blcok的根本原因: 日志中有两条不同的SQL同时并发更新同一条记录,所以后更新的SQL会等待前更新的SQL,如果SQL1所在的事务1直没有提交,那么事务2将会一直等待,这样就出现上述updating的状态
235202017 Query UPDATE test_warning ..... WHERE test_id = '46a9b' 318984063 Query UPDATE test_warning ..... task_order_id = '' WHERE test_id = '46a9b'所以我们就可以在看一下这个事务的上下文:
thread id=235202017 的SQL上下文:235202017 Query SET autocommit=0 235202017 (13:54:39) Query UPDATE test_warning SET .... WHERE test_id = '46a9b' 235202017 Query committhread id=318984063 的SQL上下文:
318984063 Query SET autocommit=1 318984063 (13:54:39)Query SELECT .... FROM test_waybill WHERE (test_id IN ('46a9b')) 318984063 Query SELECT......FROM test_waybill WHERE test_id = '46a9b' 318984063 Query UPDATE test_warning SET ..... WHERE test_id = '46a9b' 318984063 (13:55:31)Query UPDATE test_waybill_current t ..... WHERE t.test_id IN ('46a9b') 318984063 Query SET autocommit=0可以看到事务1 从13:54:39开始,直到13:55:30结束,事务2 中有更新事务1中的同一条记录,所以直到事务1 提交后,事务2才得以执行完毕,有了这样的日志,将此信息发给用户很快就找到了问题,在事务1中由于还存在其他的业务逻辑,导致事务1的提交迟迟没有完成,进而导致了其他业务锁的发生。
维护阶段
DDL操作被大查询block。
当应用上线进入维护阶段,则开始会有较多的数据库变更操作,比如:添加字段,添加索引等操作,这一类操作导致的锁故障也是非常频繁的,下面将会介绍一则案例,一个DDL操作被查询block,导致数据库连接堆积:
Query |6 | User sleep | select id ,sleep(50) from t Query |4 | Waiting for table metadata lock | alter table t add column gmt_create datetime Query |2 | Waiting for table metadata lock | select * from t where id=1 Query |1 | Waiting for table metadata lock | select * from t where id=2 Query |1 | Waiting for table metadata lock | update t set id =2 where id=1 Metadata lock wait 的含义:为了在并发环境下维护表元数据的数据一致性,在表上有活动事务(显式或隐式)的时候,不可以对元数据进行写入操作。因此 MySQL 引入了 metadata lock ,来保护表的元数据信息。因此在对表进行上述操作时,如果表上有活动事务(未提交或回滚),请求写入的会话会等待在 Metadata lock wait。
导致 Metadata lock wait 等待的常见因素包括:活动事务,当前有对表的长时间查询,显示或者隐式开启事务后未提交或回滚,比如查询完成后未提交或者回滚,表上有失败的查询事务等。
上述案例中,查询,更新和DDL操作的线程状态都为Waiting for table metadata lock,对表t的操作全部被阻塞,前端源源不断的请求到达数据库,这个时候数据库的连接很容易被打满,那我们来分析一下为什么有这这些锁等待:
- alter 操作的锁等待:由于在表t上做了一个添加字段的操作,该操作会在结束前对表获取一个metadata lock,但是该表上已经有一个查询一直未结束,导致metadata lock一直获取不到,所以添加字段操作只能等待查询结束,这就解释了alter操作为什么状态为Waiting for table metadata lock。
- 查询和更新的锁等待:由于前面进行的alter操作已经在T表上试图获取metadata lock,所以后续对表T的的查询和更新操作在获取metadata lock的时候会被alter操作所阻塞,进而导致这些线程状态为Waiting for table metadata lock。
解决办法则是将线程6 kill 掉即可。
总结
锁问题是非常常见的问题,需要我们在数据库开发、设计、管理的各个阶段都需要注意,防范未然,做到心中有数。
设计开发阶段:
- 表设计要避免使用myisam存储引擎,改用innodb引擎;
- 为SQL创建合适的索引,避免多个单列索引执行出错;
- 避免大事务,长事务,复杂事务导致事务在数据库中的运行时间加长。
管理运维阶段:
- 在业务低峰期执行上述操作,比如创建删除索引;
- 在结构变更前,观察数据库中是否存在长时间运行的SQL,未提交的事务;
- 结构变更期间,监控数据库的线程状态是否存在lock wait。
正文到此结束
- 本文标签: struct IDE key schema ACE db 数据 实例 show processlist 删除 tab UI Select explain http SQL执行 ssl sql HTML 总结 ask ORM update 线程 时间 锁 Waiting for table level lock mysql 数据库 管理 开发 DDL Action linux tar NSA 解决方法 Waiting for table metadata lock INNODB_TRX 微软 list src autocommit
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

